Dreambooth Stable Diffusion
1.0.0
Pour courir sur Vast.ai
Pour courir sur Google Colab
Pour fonctionner sur un PC local (Windows)
Pour courir sur un PC local (Ubuntu)
Adapter le tutoriel Dreambooth de Corridor Digital au repo de Joepenna
Utilisation de légendes dans Dreambooth de Joepenna

Salut! Je m'appelle Joe Penna.
Vous avez peut-être vu quelques vidéos YouTube sous Mysteryguitarman . Je suis maintenant un réalisateur de longs métrages. Vous avez peut-être vu l'Arctique ou le Stowaway.
Pour mes films, je dois être en mesure de former des acteurs, des accessoires, des emplacements, etc.
Je ne peux pas publier tous les tests pour le film sur lequel je travaille, mais quand je teste avec mon propre visage, je les publie sur ma page Twitter - @mysteryguitarm.
Beaucoup de ces tests ont été effectués avec un copain - Niko de Corridordigital. C'est peut-être la façon dont vous avez trouvé ce dépôt!
Je ne suis pas vraiment un codeur. Je suis juste têtu et je n'ai pas peur de googler. Donc, finalement, des gens vraiment intelligents se sont joints à eux et ont contribué. Dans ce dépôt, en particulier: @djbielejeski @gammagec @mrsaad –– mais tant d'autres dans notre discorde!
Ce n'est plus mon dépôt. Ce sont les gens-qui-wanna-see-dreambooth-on-sd-working-well's Repo!
Maintenant, si vous voulez essayer de faire cela ... Veuillez d'abord lire les avertissements ci-dessous:
Respectons le travail acharné et la créativité des personnes qui ont passé des années à perfectionner leurs compétences.
Sur le côté technique:
Cette implémentation n'implémente pas entièrement les idées de Google sur la façon de préserver l'espace latent.
Il ne semble pas y avoir de moyen facile de former deux sujets consécutivement. Vous vous retrouverez avec un fichier 11-12GB avant l'élagage.
~2gb La meilleure pratique consiste à changer le jeton en un nom de célébrité ( note: jeton, pas en classe - donc votre invite serait quelque chose comme: Chris Evans person ). Voici ma femme formée avec exactement les mêmes paramètres, à l'exception du jeton
Remarque Runpod met périodiquement améliore leur image Docker de base, ce qui peut conduire à Repo ne fonctionne pas. Aucune des vidéos YouTube n'est à jour, mais vous pouvez toujours les suivre comme guide. Suivez les vidéos / tutoriels YouTube Runpod typique, avec les modifications suivantes:
De l'intérieur de la page My Pods,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Inscrivez-vous à Runpod. N'hésitez pas à utiliser mon lien de référence ici, afin que je n'ai pas à payer pour cela (mais vous le faites).
Après vous être connecté, sélectionnez SECURE CLOUD ou COMMUNITY CLOUD
Assurez-vous de trouver une vitesse interne "élevée" afin que vous ne perdez pas de temps et d'argent sur les téléchargements lents
Sélectionnez quelque chose avec au moins 24 Go de VRAM comme RTX 3090, RTX 4090 ou RTX A5000
Suivez ces instructions vidéo ci-dessous:
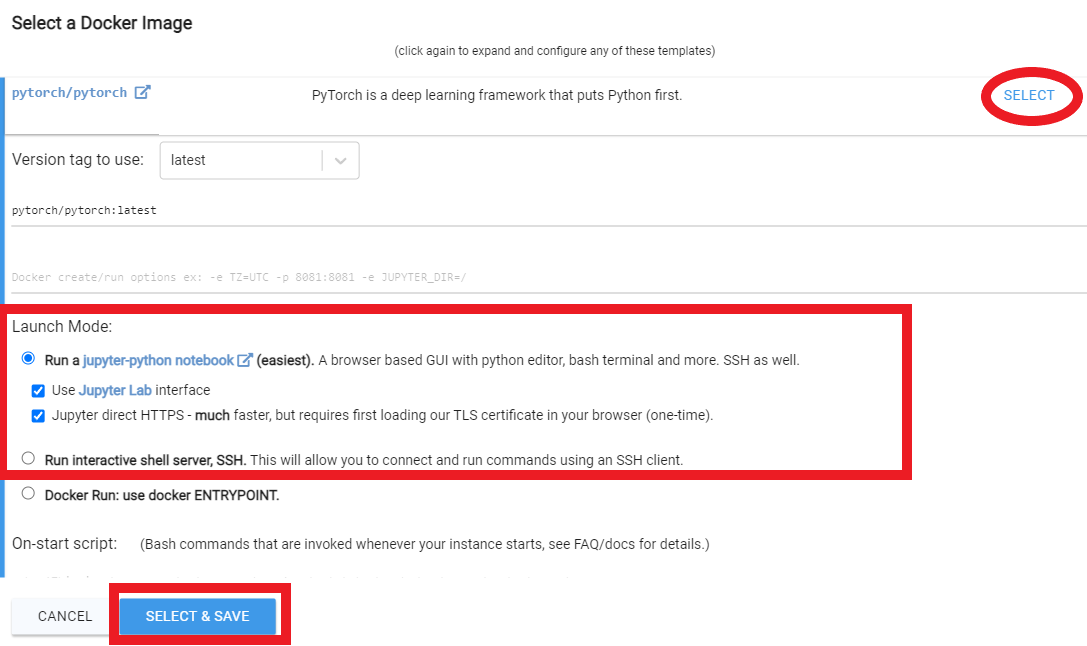
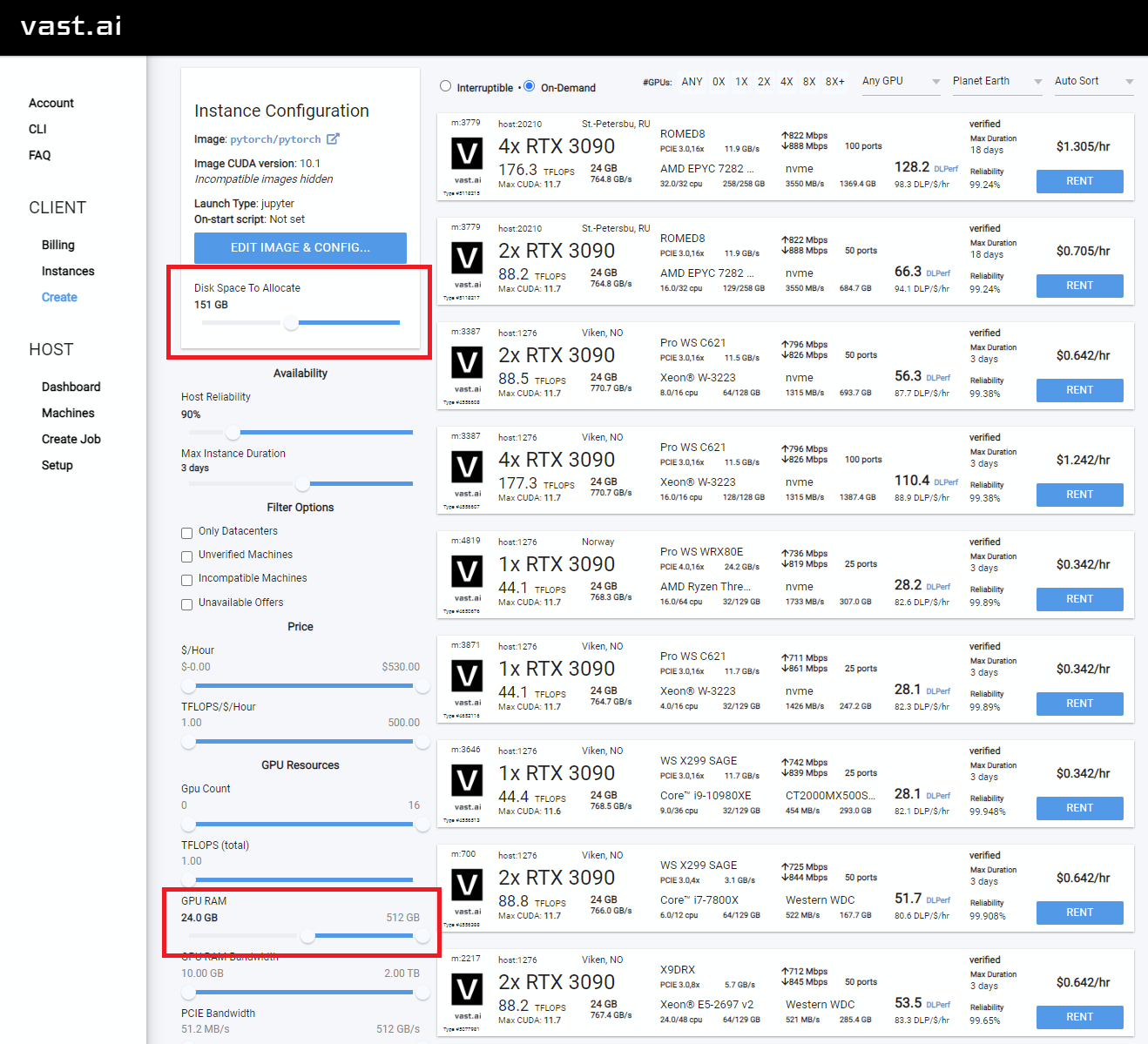
Rent , puis dirigez-vous vers votre page Instances et cliquez sur Open 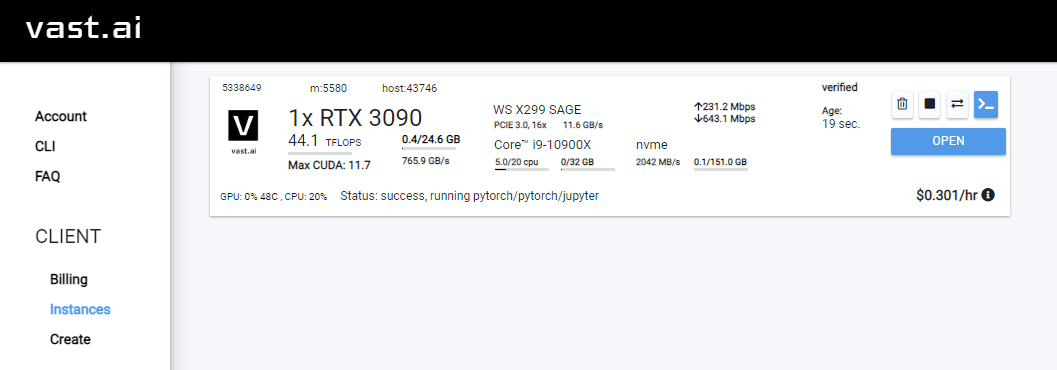
Notebook -> Python 3 (vous pouvez faire cette prochaine étape de plusieurs façons, mais je le fais généralement) 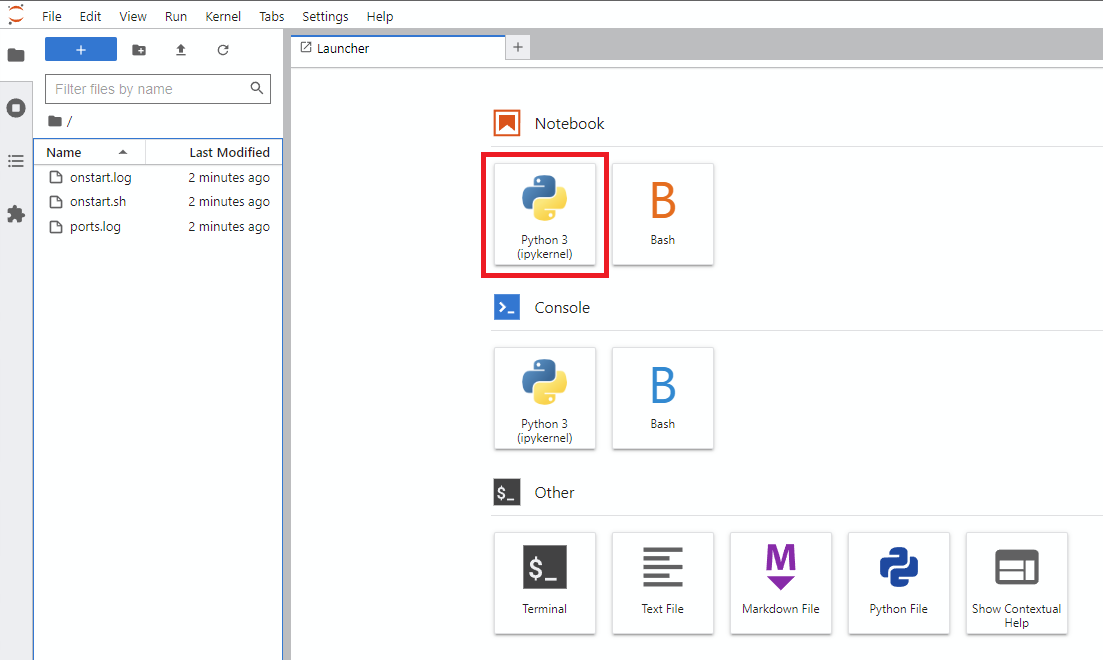
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion à gauche et ouvrez le dreambooth_simple_joepenna.ipynb ou dreambooth_runpod_joepenna.ipynb Fichier 
cmd ouvertC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers arguments.py
| Commande | Taper | Exemple | Description |
|---|---|---|---|
--config_file_path | chaîne | "C:\Users\David\Dreambooth Configs\my-config.json" | Le chemin d'accès le fichier de configuration à utiliser |
--project_name | chaîne | "My Project Name" | Nom du projet |
--debug | bool | False | Les défauts facultatifs sont False . Activer la journalisation de débogage |
--seed | int | 23 | Par défaut facultatifs à 23 . Graine pour semence_tout |
--max_training_steps | int | 3000 | Nombre d'étapes d'entraînement pour fonctionner |
--token | chaîne | "owhx" | Jeton unique, vous souhaitez représenter votre modèle formé. |
--token_only | bool | False | Les défauts facultatifs sont False . Entraîner uniquement en utilisant le jeton et pas de classe. |
--training_model | chaîne | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Chemin vers le modèle pour s'entraîner (Model.CKPT) |
--training_images | chaîne | "D:\stable-diffusion\training_images\24 Images - captioned" | Path to Training Images Directory |
--regularization_images | chaîne | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Chemin vers le répertoire avec des images de régularisation |
--class_word | chaîne | "woman" | Faites correspondre CLASS_WORD à la catégorie des images que vous souhaitez entraîner. Exemple: man , woman , dog ou artstyle . |
--flip_p | flotter | 0.0 | Les défauts facultatifs se déroulent à 0.5 . Pourcentage de retournement. Exemple: Si vous êtes défini sur 0.5 , retournera (miroir) vos images d'entraînement 50% du temps. Cela aide à étendre votre ensemble de données sans avoir besoin d'inclure plus d'images de formation. Cela peut conduire à des résultats pires pour la formation au visage, car les visages de la plupart des gens ne sont pas parfaitement symétriques. |
--learning_rate | flotter | 1.0e-06 | Les défauts facultatifs sont à 1.0e-06 (0,000001). Définir le taux d'apprentissage. Accepte la notation scientifique. |
--save_every_x_steps | int | 250 | Par défaut facultatifs à 0 . Enregistre un point de contrôle toutes les x étapes. À 0 sauvegarde uniquement à la fin de la formation lorsque max_training_steps est atteint. |
--gpu | int | 0 | Par défaut facultatifs à 0 . Spécifiez un GPU autre que 0 à utiliser pour la formation. Le support multi-GPU n'est pas actuellement implémenté. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Les légendes sont prises en charge. Voici le guide sur la façon dont nous les avons mis en œuvre.
Disons que votre jeton est Effy et que votre classe est personne, votre racine de données est / train alors:
training_images/img-001.jpg est sous-titré avec effy person
Vous pouvez personnaliser le sous-titrage en l'ajoutant après un symbole @ dans le nom de fichier.
/training_images/img-001@a photo of effy => a photo of effy
Vous pouvez utiliser deux jetons dans vos légendes S - Uppercase S - et C - Uppercase C - pour indiquer le sujet et la classe.
/training_images/img-001@S being a good C.jpg => effy being a good person
Pour créer un nouveau sujet, vous avez juste besoin de créer un dossier pour cela. Donc:
/training_images/bingo/img-001.jpg => bingo person
La classe reste la même, mais maintenant le sujet a changé.
Encore une fois - le jeton est maintenant le bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
Un dossier plus profondément et vous pouvez changer la classe: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
Non vient le kicker: un niveau plus profondément et vous pouvez légendre le groupe d'images: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
La majorité du code dans ce dépôt a été écrite par Rinon Gal et. Al, les auteurs du document de recherche sur l'inversion textuel. Bien que quelques idées sur les images de régularisation et la préservation des pertes antérieures (des idées de "Dreambooth") aient été ajoutées, par respect à la fois à l'équipe du MIT et aux chercheurs de Google, je renommage cette fourche: "Le repo anciennement connu sous le nom de" Dreambooth "" .
Pour une alternative d'implémentation, veuillez consulter "Alternate Option" ci-dessous.
La ground truth (vraie image, prudence: très belle femme) 
Même invite pour toutes ces images ci-dessous:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Inviter avec juste votre jeton. c'est-à-dire "Joepenna" au lieu de "Joepenna Person"
Si vous vous êtes entraîné avec joepenna sous la person de classe, le modèle ne doit connaître votre visage que:
joepenna person
Exemples d'invites:
Incorrect ( person disparue suivant joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ c'est juste ( person est incluse après joepenna )
portrait photograph of joepenna person 35mm film vintage glass
Vous pourriez parfois obtenir quelqu'un qui vous ressemble un peu avec Joepenna (surtout si vous vous êtes entraîné à trop d'étapes), mais c'est uniquement parce que cette itération actuelle de Dreambooth surtrains tellement à tel qu'elle saigne dans ce jeton.
Pendant la formation, Stable ne sait pas que vous êtes une personne. Ça va juste imiter ce qu'il voit.
Donc, si ce sont vos images d'entraînement ressemblent à ceci:
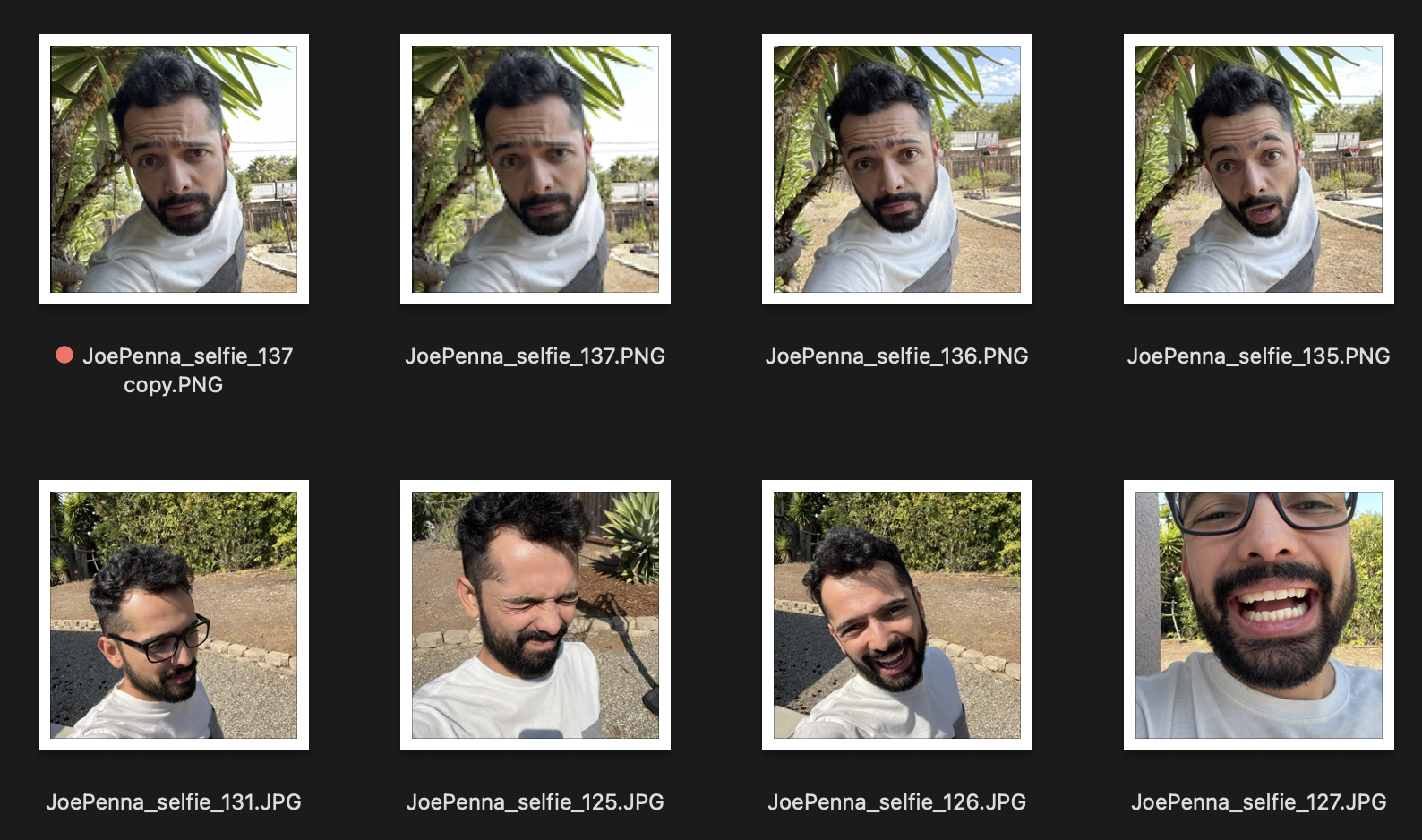
Vous n'aurez que des générations à l'extérieur à côté d'un arbre épineux, portant une chemise blanche et gris, dans le style de ... enfin, une photographie de selfie.
Au lieu de cela, cet ensemble de formation est bien meilleur:
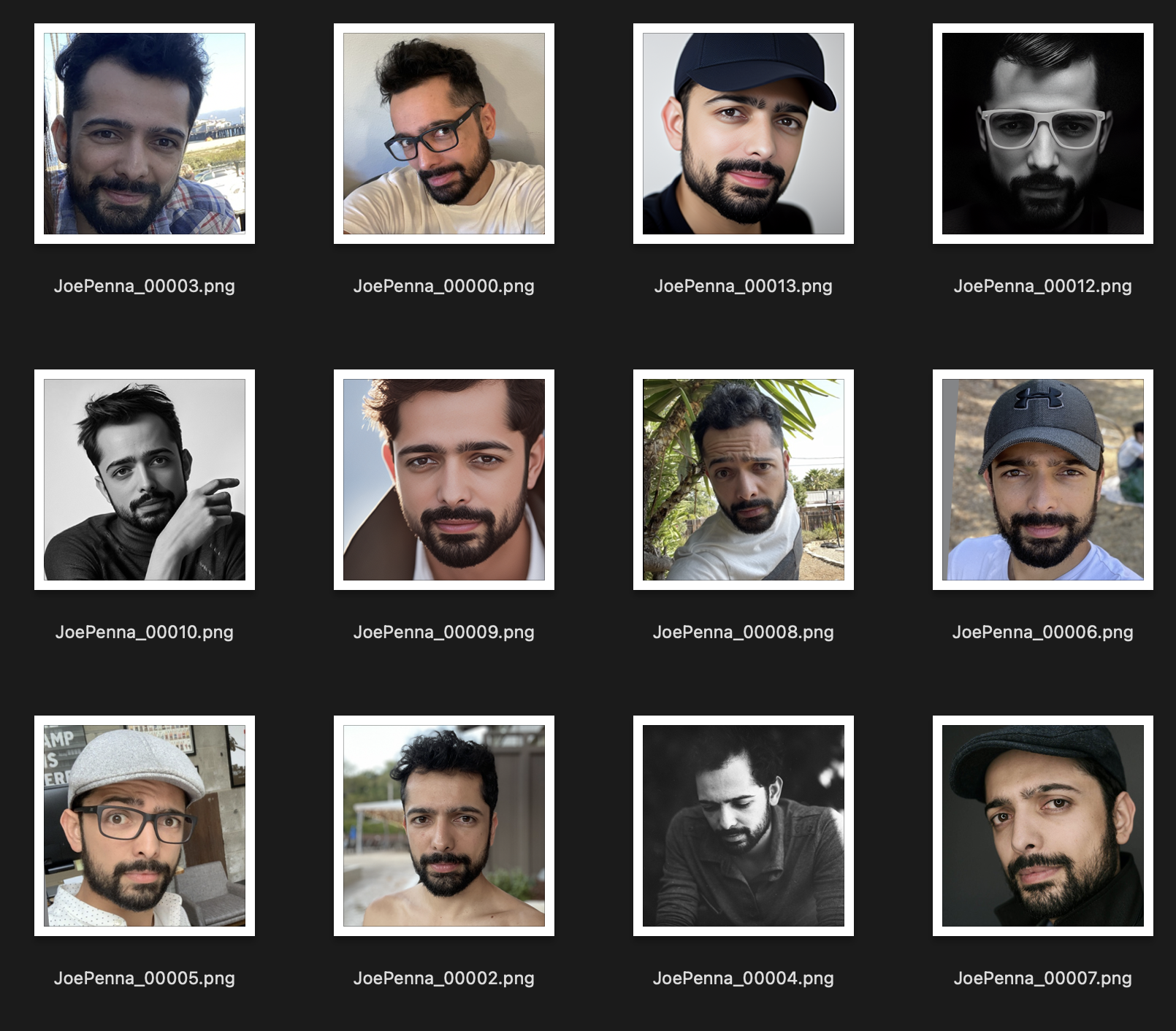
La seule chose cohérente entre les images est le sujet. Ainsi, Stable examinera les images et n'apprendra que votre visage, ce qui fera la "modification" dans d'autres styles possibles.
Êtes-vous sûr de l'inviter non?
Il devrait être <token> <class> , pas seulement <token> . Par exemple:
JoePenna person, portrait photograph, 85mm medium format photo
Si cela ne vous ressemble toujours pas, vous ne vous êtes pas entraîné assez longtemps.
D'accord, quelques raisons pour lesquelles: vous avez peut-être été entraîné trop longtemps ... ou vos images étaient trop similaires ... ou vous ne vous êtes pas entraîné avec suffisamment d'images.
Aucun problème. Nous pouvons résoudre ce problème avec l'invite. La diffusion stable met beaucoup de mérite à tout ce que vous tapez en premier. Alors enregistrez-le pour plus tard:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
Vous ne vous êtes pas entraîné assez longtemps ...
Aucun problème. Nous pouvons résoudre ce problème avec l'invite:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
Dreambooth est désormais soutenu dans les diffuseurs de câlins pour une formation avec une diffusion stable.
Essayez-le ici:


