Dreambooth Stable Diffusion
1.0.0
Zum Laufen auf Vast.ai
Für das Laufen auf Google Colab
Zum Ausführen auf einem lokalen PC (Windows)
Zum Laufen auf einem lokalen PC (Ubuntu)
Anpassung des Dreambooth -Tutorials von Corridor Digital an Joepennas Repo
Verwenden von Bildunterschriften in Joepennas Dreambooth

Hallo! Mein Name ist Joe Penna.
Vielleicht haben Sie unter Mysteryguitarman ein paar YouTube -Videos von mir gesehen. Ich bin jetzt ein Spielfilmregisseur. Sie haben vielleicht Arctic oder Stowaway gesehen.
Für meine Filme muss ich in der Lage sein, bestimmte Schauspieler, Requisiten, Standorte usw. auszubilden, also habe ich ein paar Änderungen an @Xavierxiaos Repo vorgenommen, um die Gesichter der Menschen auszubilden.
Ich kann nicht alle Tests für den Film veröffentlichen, an dem ich arbeite, aber wenn ich mit meinem eigenen Gesicht teste, veröffentlichen ich diese auf meiner Twitter -Seite - @Myteryguitarm.
Viele dieser Tests wurden mit einem Kumpel von mir durchgeführt - Niko von Corridordigital. Es könnte sein, wie Sie dieses Repo gefunden haben!
Ich bin nicht wirklich ein Coder. Ich bin nur stur und habe keine Angst vor Googeln. Schließlich haben sich einige wirklich kluge Leute angeschlossen und haben dazu beigetragen. In diesem Repo speziell: @djbielejeski @gammagec @mrsaad - - aber so viele andere in unserer Zwietracht!
Dies ist nicht mehr mein Repo. Dies ist die Menschen, die whanna-see-dreambooth-on-SD-Working-Wells Repo!
Wenn Sie jetzt versuchen möchten, dies zu tun ... lesen Sie bitte zuerst die Warnungen unten:
Respektieren wir die harte Arbeit und Kreativität von Menschen, die jahrelang ihre Fähigkeiten verbessern.
Auf die technische Seite:
Diese Implementierung implementiert die Ideen von Google nicht vollständig, wie der latente Raum erhalten bleibt.
Es scheint keine einfache Möglichkeit zu geben, zwei Themen nacheinander zu trainieren. Sie werden vor dem Beschneiden eine 11-12GB Datei erhalten.
~2gb Notizbuch verfügt Die beste Praxis besteht darin, das Token in einen Prominentennamen zu ändern ( Hinweis: Token, nicht Klasse - Ihre Aufforderung wäre also so etwas wie: Chris Evans person ). Hier ist meine Frau, die genau mit den gleichen Einstellungen trainiert wurde, mit Ausnahme des Tokens
Hinweis RunPod aktualisiert regelmäßig ihr Basis -Docker -Image, was dazu führen kann, dass Repo nicht funktioniert. Keines der YouTube -Videos ist auf dem neuesten Stand, aber Sie können ihnen dennoch als Leitfaden folgen. Folgen Sie den typischen Runpod -YouTube -Videos/Tutorials mit den folgenden Änderungen:
Von innerhalb der Seite My Pods,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Melden Sie sich für Runpod an. Fühlen Sie sich frei, meinen Empfehlungslink hier zu verwenden, damit ich nicht dafür bezahlen muss (aber Sie tun dies).
Wählen Sie nach dem Anmelden entweder SECURE CLOUD oder COMMUNITY CLOUD aus
Stellen Sie sicher, dass Sie eine "hohe" Interent -Geschwindigkeit finden, damit Sie keine Zeit und Geld für langsame Downloads verschwenden
Wählen Sie etwas mit mindestens 24 GB VRAM wie RTX 3090, RTX 4090 oder RTX A5000 aus
Folgen Sie folgenden Videoanweisungen unten:
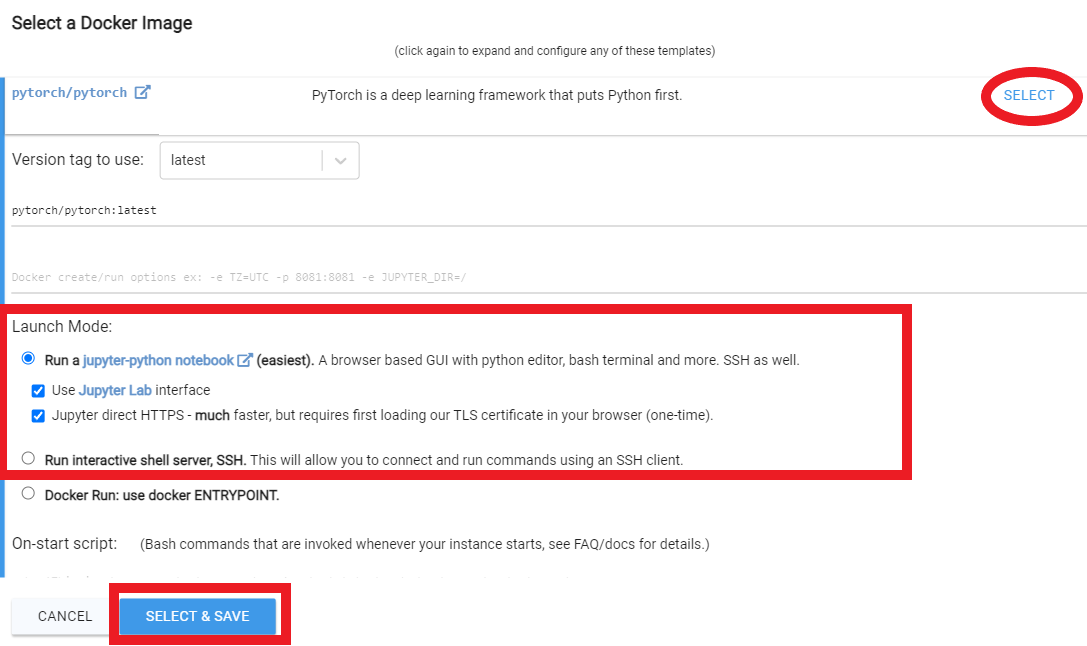
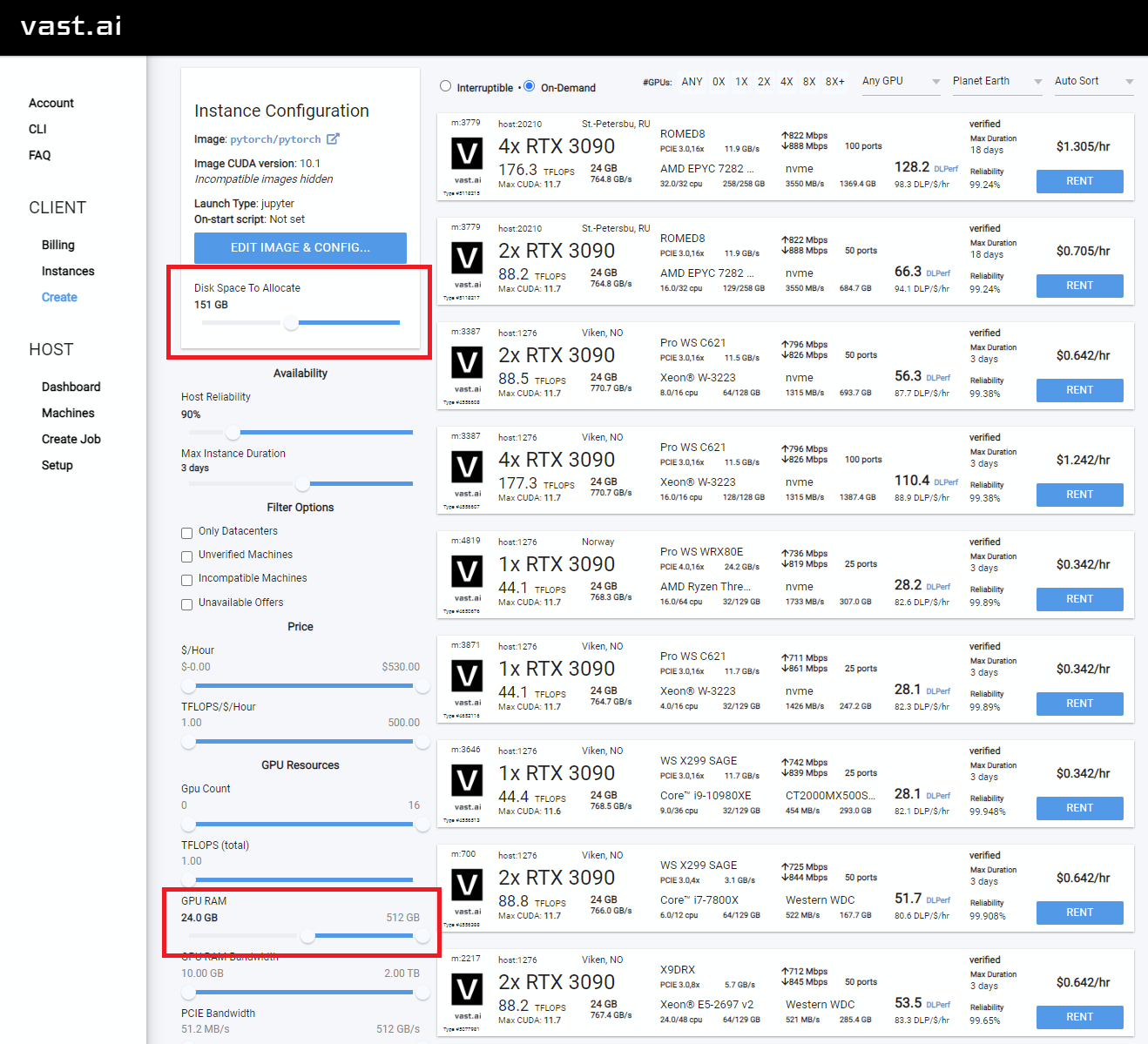
Rent . Gehen Sie dann zu Ihrer Instanzen und klicken Sie auf Open 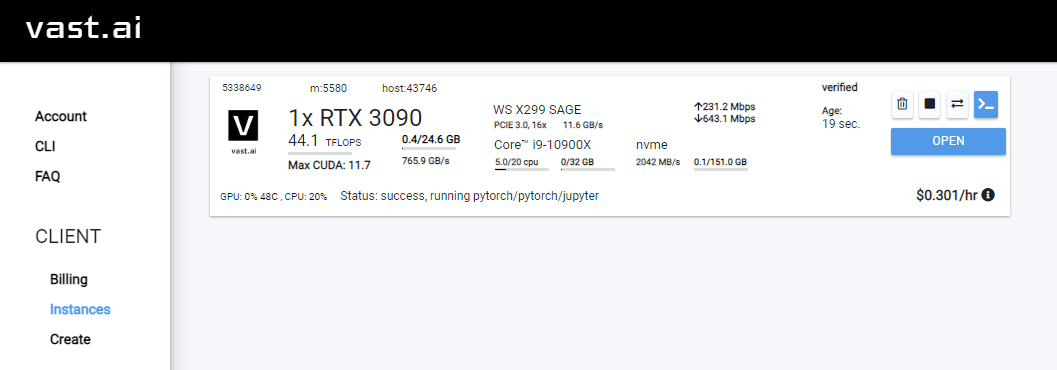
Notebook -> Python 3 (Sie können diesen nächsten Schritt auf verschiedene Weise ausführen, aber ich mache dies normalerweise) 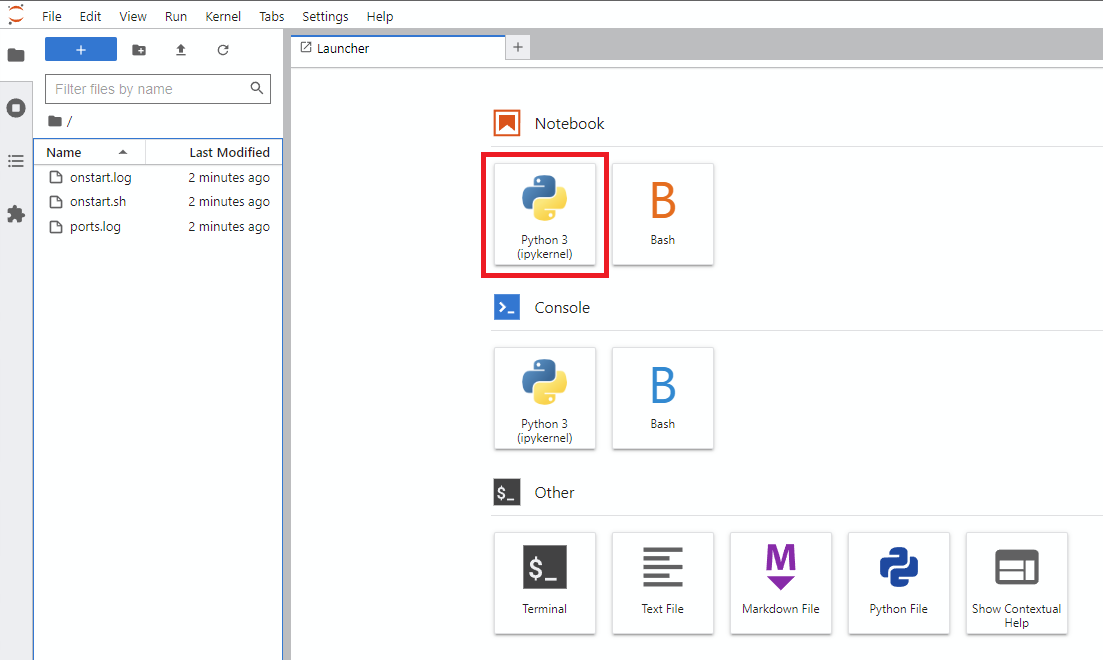
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 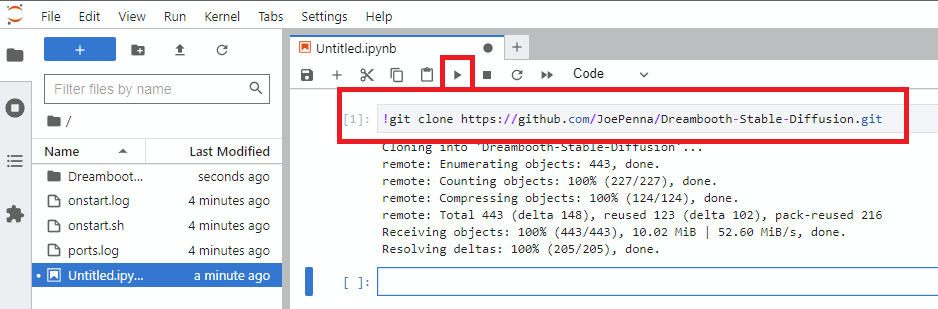
dreambooth_runpod_joepenna.ipynb in das neue Dreambooth-Stable-Diffusion dreambooth_simple_joepenna.ipynb auf der linken 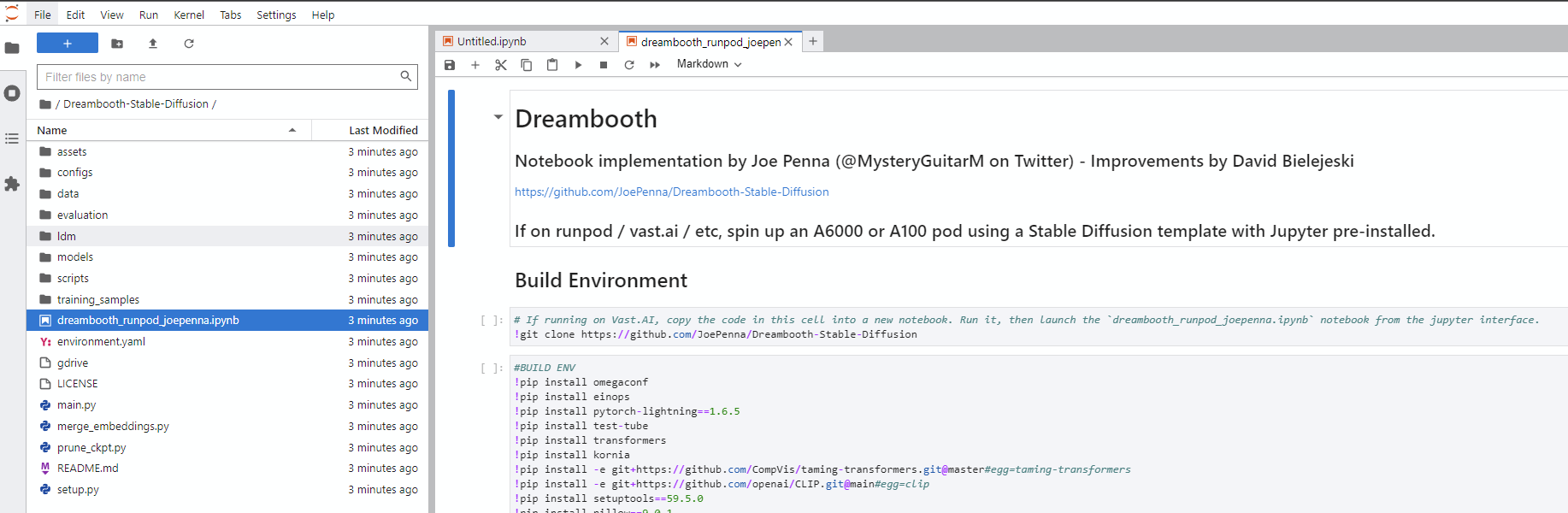
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
DREAMBOOTH_HELPERS Argumente.py
| Befehl | Typ | Beispiel | Beschreibung |
|---|---|---|---|
--config_file_path | Saite | "C:\Users\David\Dreambooth Configs\my-config.json" | Der Pfad der zu verwendenden Konfigurationsdatei |
--project_name | Saite | "My Project Name" | Name des Projekts |
--debug | bool | False | Optionale Standardeinstellungen zu False . Aktivieren Sie die Debug -Protokollierung |
--seed | int | 23 | Optionale Standardeinstellungen bis 23 . Samen für Samen |
--max_training_steps | int | 3000 | Anzahl der Trainingsschritte zum Ausführen |
--token | Saite | "owhx" | Einzigartige Token Sie möchten Ihr geschulter Modell darstellen. |
--token_only | bool | False | Optionale Standardeinstellungen zu False . Trainieren nur mit dem token und keine Klasse. |
--training_model | Saite | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Weg zum Modell zu trainieren (modell.ckpt) |
--training_images | Saite | "D:\stable-diffusion\training_images\24 Images - captioned" | Pfad zum Trainingsbilderverzeichnis |
--regularization_images | Saite | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Pfad zum Verzeichnis mit Regularisierungsbildern |
--class_word | Saite | "woman" | Übereinstimmen class_Word mit der Kategorie der Bilder, die Sie trainieren möchten. Beispiel: man , woman , dog oder artstyle . |
--flip_p | schweben | 0.0 | Optionale Standardeinstellung auf 0.5 . Flip -Prozentsatz. Beispiel: Wenn Sie auf 0.5 eingestellt sind, werden Ihre Trainingsbilder in 50% der Fälle (Spiegel) umdrehen (Spiegel). Dies hilft, Ihren Datensatz zu erweitern, ohne mehr Trainingsbilder aufzunehmen. Dies kann zu schlechteren Ergebnissen für das Gesichtstraining führen, da die Gesichter der meisten Menschen nicht perfekt symmetrisch sind. |
--learning_rate | schweben | 1.0e-06 | Optionale Standardeinstellungen auf 1.0e-06 (0,000001). Setzen Sie die Lernrate. Akzeptiert wissenschaftliche Notation. |
--save_every_x_steps | int | 250 | Optionale Standardeinstellungen auf 0 . Speichert alle X -Schritte einen Checkpoint. Bei 0 spart nur am Ende des Trainings, wenn max_training_steps erreicht ist. |
--gpu | int | 0 | Optionale Standardeinstellungen auf 0 . Geben Sie eine andere GPU als 0 an, um sie für das Training zu verwenden. Der Multi-GPU-Support wird derzeit nicht implementiert. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Bildunterschriften werden unterstützt. Hier ist die Anleitung, wie wir sie implementiert haben.
Nehmen wir an, Ihr Token ist effy und Ihre Klasse ist eine Person, Ihre Datenwurzel ist dann: Dann:
training_images/img-001.jpg wird mit effy person überschriftet
Sie können die Bildunterschriften anpassen, indem Sie sie nach einem @ -Symbol im Dateinamen hinzufügen.
/training_images/img-001@a photo of effy => a photo of effy
Sie können zwei Token in Ihren Bildunterschriften C S
/training_images/img-001@S being a good C.jpg => effy being a good person
Um ein neues Thema zu erstellen, müssen Sie nur einen Ordner dafür erstellen. Also:
/training_images/bingo/img-001.jpg => bingo person
Die Klasse bleibt gleich, aber jetzt hat sich das Thema geändert.
Wieder - das Token S ist jetzt Bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
Ein Ordner tiefer und Sie können die Klasse ändern: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
Nein kommt der Kicker: Eine Ebene tiefer und Sie können die Gruppe von Bildern beschreiben: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
Der Großteil des Code in diesem Repo wurde von Rinon Gal et. Al, die Autoren des Textinversionsforschungsarbeits. Obwohl einige Vorstellungen von Regularisierungsbildern und Vorbehandlung vor dem Verlust (Ideen von "Dreambooth") aus Respekt sowohl für das MIT -Team als auch für die Google -Forscher hinzugefügt wurden, benenne ich diese Gabel um: "Das Repo, das früher bekannt als" bekannt war " Dreambooth "" .
Eine alternative Implementierung finden Sie im Folgenden "Alternative Option".
Die ground truth (echtes Bild, Vorsicht: sehr schöne Frau) 
Gleiche Aufforderung für all diese Bilder unten:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Aufforderung mit nur deinem Token. dh "Joepenna" anstelle von "Joepenna Person"
Wenn Sie mit joepenna unter der person trainiert haben, sollte das Modell Ihr Gesicht nur als:
joepenna person
Beispielaufforderungen:
Falsch (vermisste person nach joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ Dies ist richtig ( person ist nach joepenna enthalten)
portrait photograph of joepenna person 35mm film vintage glass
Sie könnten manchmal jemanden bekommen, der mit Joepenna wie Sie aussieht (besonders wenn Sie für zu viele Schritte trainiert haben), aber das liegt nur daran, dass diese aktuelle Iteration von Dreambooth das Token so sehr überträgt, dass es in dieses Token einblutet.
Während des Trainings weiß Stable nicht, dass Sie eine Person sind. Es wird nur nachahmen, was es sieht.
Wenn dies Ihre Trainingsbilder sind, sehen sie also so aus:
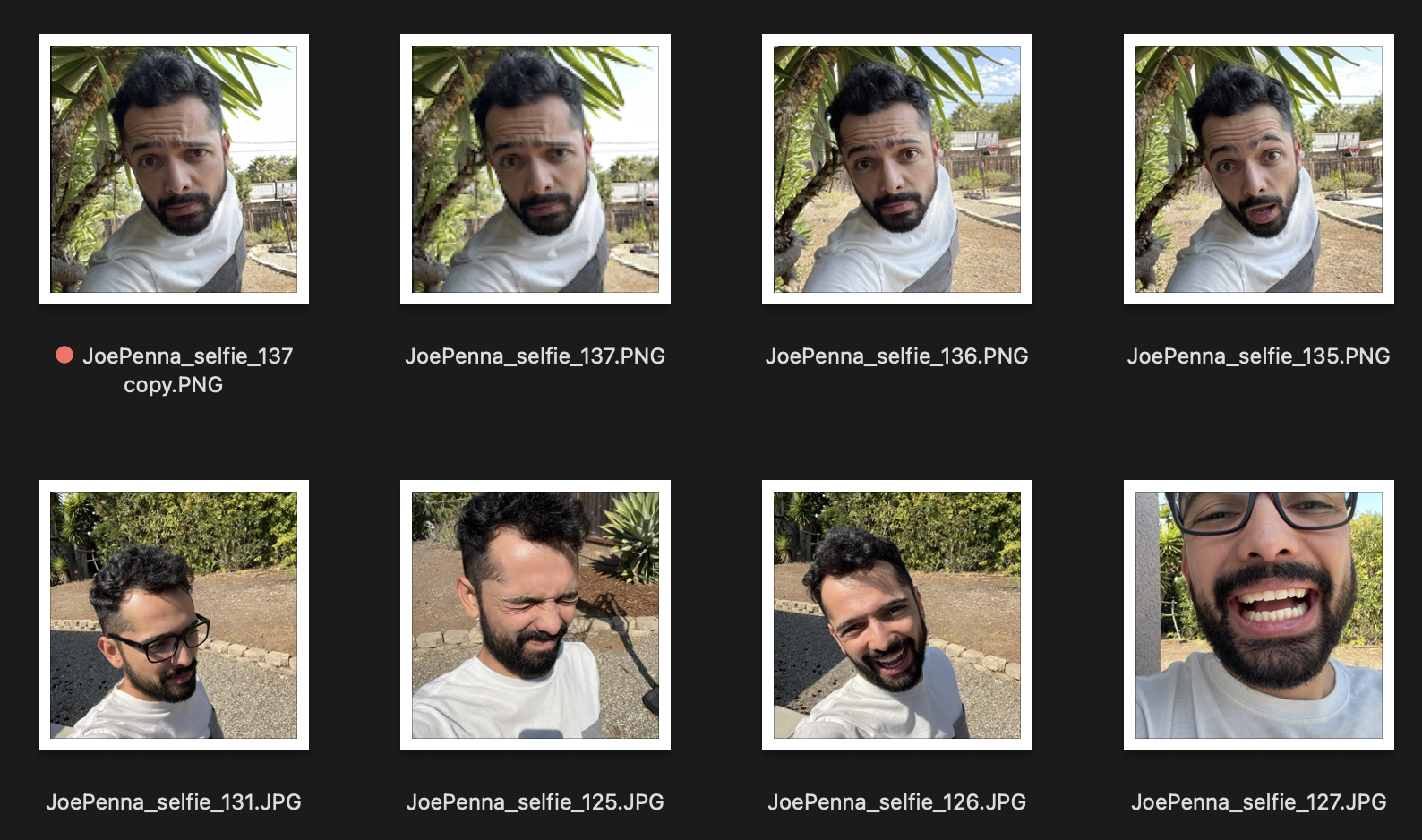
Sie werden nur Generationen von Ihnen draußen neben einem stacheligen Baum bekommen und ein weiß-graues Hemd im Stil von ... naja, Selfie-Foto tragen.
Stattdessen ist dieses Trainingssatz viel besser:
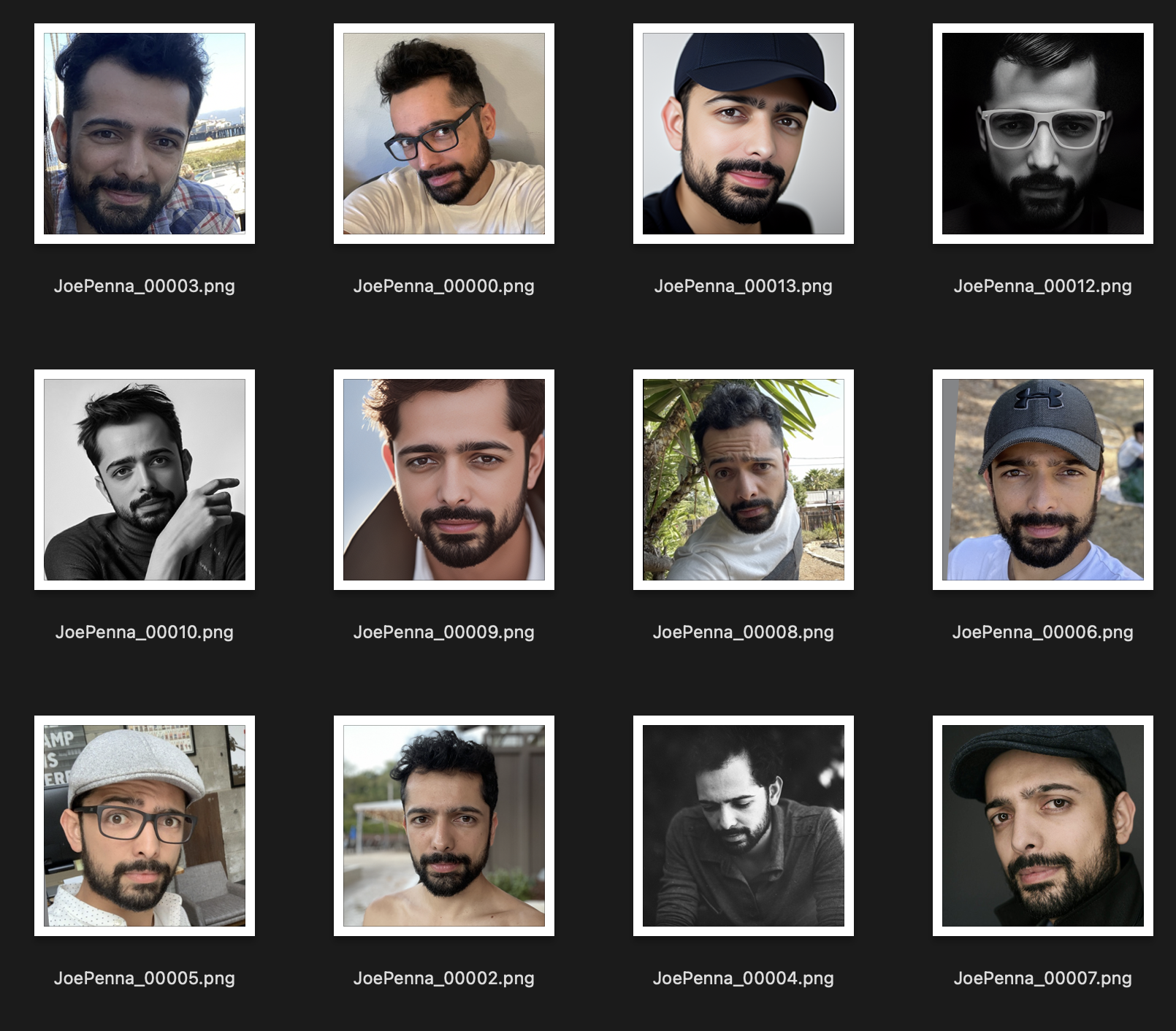
Das einzige, was zwischen den Bildern konsistent ist, ist das Thema. Daher wird stabil durch die Bilder schauen und nur Ihr Gesicht lernen, was das "Bearbeiten" in andere Stile ermöglicht.
Bist du sicher, dass du es richtig forderst?
Es sollte <token> <class> sein, nicht nur <token> . Zum Beispiel:
JoePenna person, portrait photograph, 85mm medium format photo
Wenn es immer noch nicht wie Sie aussieht, haben Sie nicht lange genug trainiert.
Okay, ein paar Gründe, warum: Sie haben vielleicht zu lange trainiert ... oder Ihre Bilder waren zu ähnlich ... oder Sie haben nicht mit genügend Bildern trainiert.
Kein Problem. Wir können das mit der Eingabeaufforderung beheben. Die stabile Diffusion bringt dem, was Sie zuerst tippen, viel Verdienst ein. Speichern Sie es also für später:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
Du hast nicht lange genug trainiert ...
Kein Problem. Wir können das mit der Eingabeaufforderung beheben:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
Dreambooth wird jetzt bei der Ausbildung mit stabiler Diffusion unterstützt.
Probieren Sie es hier aus:


