Dreambooth Stable Diffusion
1.0.0
用於在vast.ai上跑步
用於在Google Colab上運行
用於在本地PC(Windows)上運行
用於在本地PC(Ubuntu)上運行
適應走廊數字的Dreambooth教程到Joepenna的倉庫
在Joepenna的Dreambooth中使用標題

你好!我叫喬·佩納(Joe Penna)。
您可能已經在MysteryguitArman下看過一些我的YouTube視頻。我現在是故事片導演。您可能已經看到北極或儲藏室。
對於我的電影,我需要能夠培訓特定的演員,道具,位置等。因此,我對 @xavierxiao的回購進行了許多更改,以訓練人們的臉。
我無法發布正在拍攝的電影的所有測試,但是當我用自己的臉測試時,我會在Twitter頁面上釋放這些測試 - @mysteryguitarm。
這些測試中有很多是與我的一個夥伴一起完成的 - 來自Corridordigital的Niko。可能是您找到此存儲庫的方式!
我不是真正的編碼員。我只是固執,我不怕谷歌搜索。因此,最終,一些非常聰明的人加入了並一直在做出貢獻。在此存儲庫中,特別是:@djbielejeski @gammagec @mrsaad - 但我們的不和諧中有很多其他!
這不再是我的回購。這是whan-wanna-see-dreambooth-n-sd-sd-working-well's Repo!
現在,如果您想嘗試這樣做...請首先閱讀下面的警告:
讓我們尊重花費多年磨練自己技能的人們的辛勤工作和創造力。
進入技術方面:
該實現並未完全實施Google關於如何保留潛在空間的想法。
似乎沒有一個簡單的方法可以連續訓練兩個主題。修剪之前,您最終將獲得11-12GB文件。
~2gb最好的做法是將令牌更改為名人名稱(注意:令牌,而不是上課- 因此您的提示將是: Chris Evans person )。這是我的妻子接受了完全相同的設置訓練,除了令牌
請注意,Runpod會定期升級其基本Docker映像,這可能導致回購不起作用。 YouTube視頻都沒有最新的視頻,但您仍然可以跟隨它們作為指導。沿著典型的Runpod YouTube視頻/教程進行以下更改:
從“我的豆莢”頁面中
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116註冊Runpod。請隨時在此處使用我的推薦鏈接,這樣我就不必付費(但是您這樣做)。
登錄後,選擇SECURE CLOUD或COMMUNITY CLOUD
確保您找到“高”臨時速度
選擇至少24GB VRAM,例如RTX 3090,RTX 4090或RTX A5000
按照以下這些視頻說明:
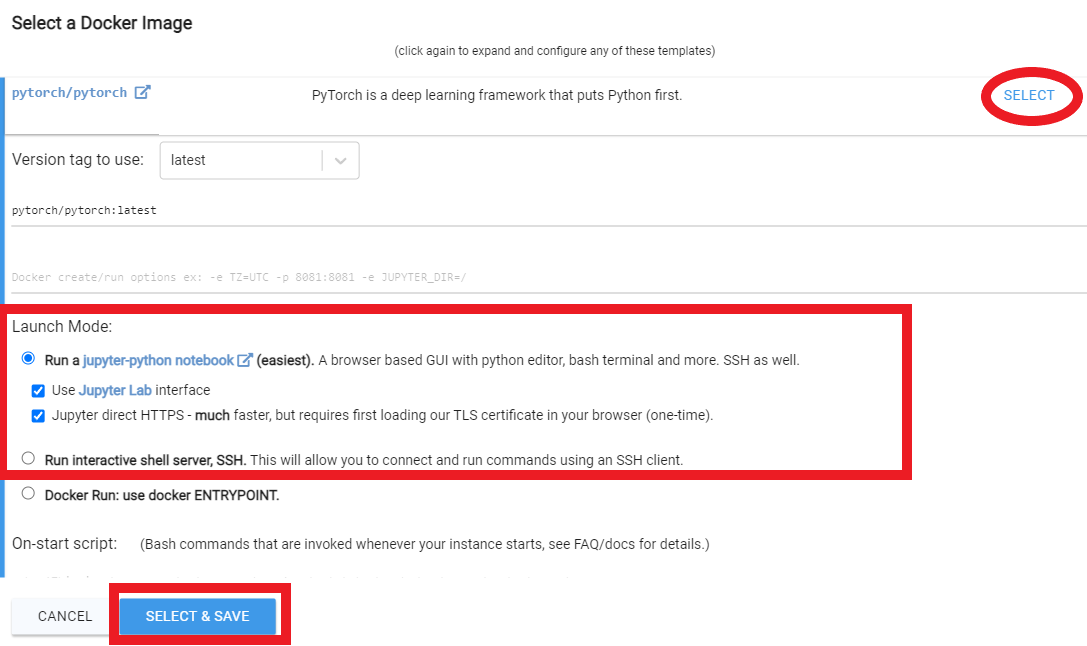
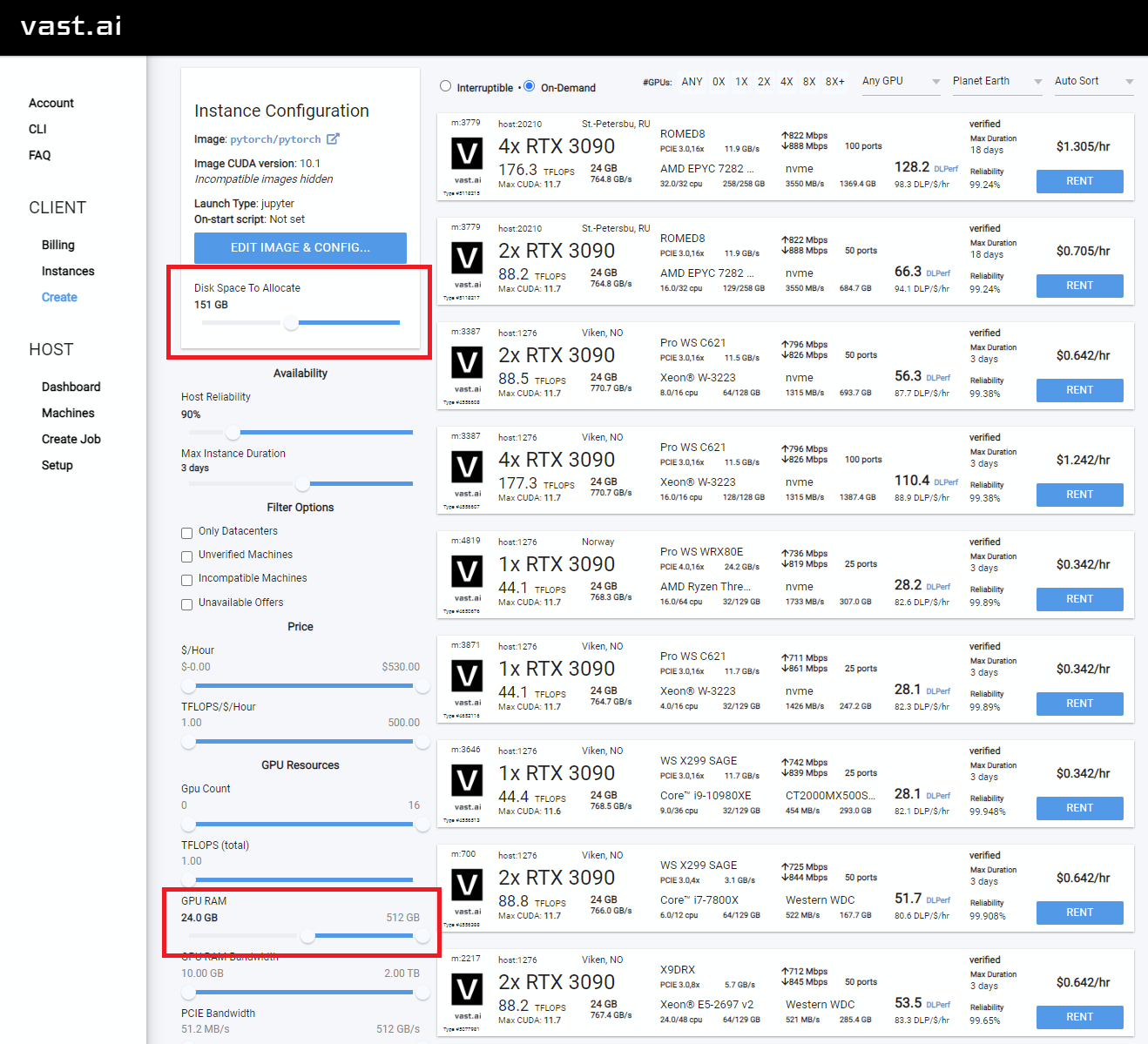
Rent ,然後轉到您的實例頁面,然後單擊“ Open 
Notebook -> Python 3 (您可以通過多種方式執行此操作,但我通常會這樣做) 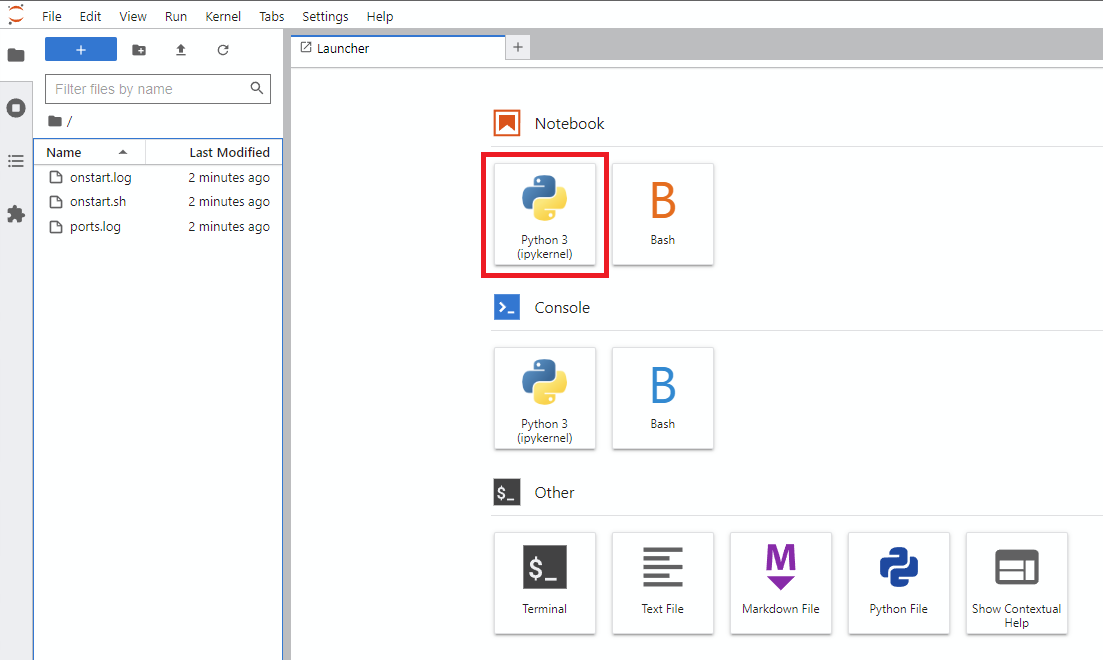
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion目錄,然後打開dreambooth_simple_joepenna.ipynb或dreambooth_runpod_joepenna.ipynb文件
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txtcmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepennacmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers gragments.py
| 命令 | 類型 | 例子 | 描述 |
|---|---|---|---|
--config_file_path | 細繩 | "C:\Users\David\Dreambooth Configs\my-config.json" | 要使用的配置文件的路徑 |
--project_name | 細繩 | "My Project Name" | 該項目的名稱 |
--debug | 布爾 | False | 可選默認為False 。啟用調試記錄 |
--seed | int | 23 | 可選默認值為23 。種子的種子 |
--max_training_steps | int | 3000 | 訓練步驟的數量 |
--token | 細繩 | "owhx" | 您要代表訓練有素的模型的獨特令牌。 |
--token_only | 布爾 | False | 可選默認為False 。僅使用令牌而沒有課程的訓練。 |
--training_model | 細繩 | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | 訓練模型的途徑(model.ckpt) |
--training_images | 細繩 | "D:\stable-diffusion\training_images\24 Images - captioned" | 訓練圖像目錄的途徑 |
--regularization_images | 細繩 | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | 使用正規化圖像的目錄路徑 |
--class_word | 細繩 | "woman" | 將class_word匹配到您要訓練的圖像類別。示例: man , woman , dog或artstyle 。 |
--flip_p | 漂浮 | 0.0 | 可選默認值為0.5 。翻轉百分比。示例:如果設置為0.5 ,將在50%的時間內翻轉(鏡像)您的訓練圖像。這有助於擴展您的數據集,而無需包括更多的培訓圖像。這可能會導致面部訓練的結果更糟,因為大多數人的面孔並不是完全對稱的。 |
--learning_rate | 漂浮 | 1.0e-06 | 可選默認值為1.0e-06 (0.000001)。設置學習率。接受科學符號。 |
--save_every_x_steps | int | 250 | 可選默認值為0 。為每個X步驟保存一個檢查站。在達到max_training_steps時,僅在0時才保存。 |
--gpu | int | 0 | 可選默認值為0 。指定除0以外的GPU用於培訓。當前尚未實施多GPU支持。 |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
支持字幕。這是我們如何實施它們的指南。
假設您的代幣是Effy,您的班級是人,您的數據root是 /訓練:
training_images/img-001.jpg為effy person加上字幕
您可以通過在文件名中的@符號之後添加字幕來自定義字幕。
/training_images/img-001@a photo of effy => a photo of effy
您可以在字幕中使用兩個令牌S大寫s-和C大寫C-來指示主題和類。
/training_images/img-001@S being a good C.jpg => effy being a good person
要創建一個新主題,您只需要為其創建一個文件夾即可。所以:
/training_images/bingo/img-001.jpg => bingo person
該課程保持不變,但是現在主題已經改變。
再次 - 令牌S現在是賓果遊戲:
/training_images/bingo/img-001@S is being silly.jpg bingo is being silly
一個文件夾更深入,您可以更改類: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
毫無啟動者:更深入一個級別,您可以為圖像組標題:/triending_images/effy/person/a a picture of effy person /training_images/effy/person/a picture of/img-001.jpg =>
此存儲庫中的大部分代碼是由Rinon Gal等人撰寫的。 Al,文本反演研究論文的作者。儘管出於MIT團隊和Google的研究人員的尊重,但還增加了有關正規化圖像和先前保存(“ Dreambooth”的想法)的一些想法(“ Dreambooth”的想法),但我正在將此叉命名為: “以前被稱為“回購” Dreambooth“” 。
有關替代實現,請參見下面的“替代選項”。
ground truth (真實的圖片,謹慎:非常美麗的女人) 
下面所有這些圖像的提示相同:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
僅提示您的令牌。即“ Joepenna”,而不是“ Joepenna Person”
如果您在person的joepenna訓練中,模型只能知道您的臉為:
joepenna person
示例提示:
不正確(在joepenna之後失踪person )
portrait photograph of joepenna 35mm film vintage glass
✅這是正確的(在joepenna之後包括person )
portrait photograph of joepenna person 35mm film vintage glass
有時,您可能會得到一個與Joepenna看起來像您一樣的人(尤其是如果您經過了太多步驟訓練),但這僅僅是因為當前的Dreambooth過度訓練的迭代使圖像如此之多,以至於它會流血到那個代幣中。
在訓練期間,馬stable不知道你是一個人。它只是模仿它看到的。
因此,如果這些是您的培訓圖像,則看起來像這樣:
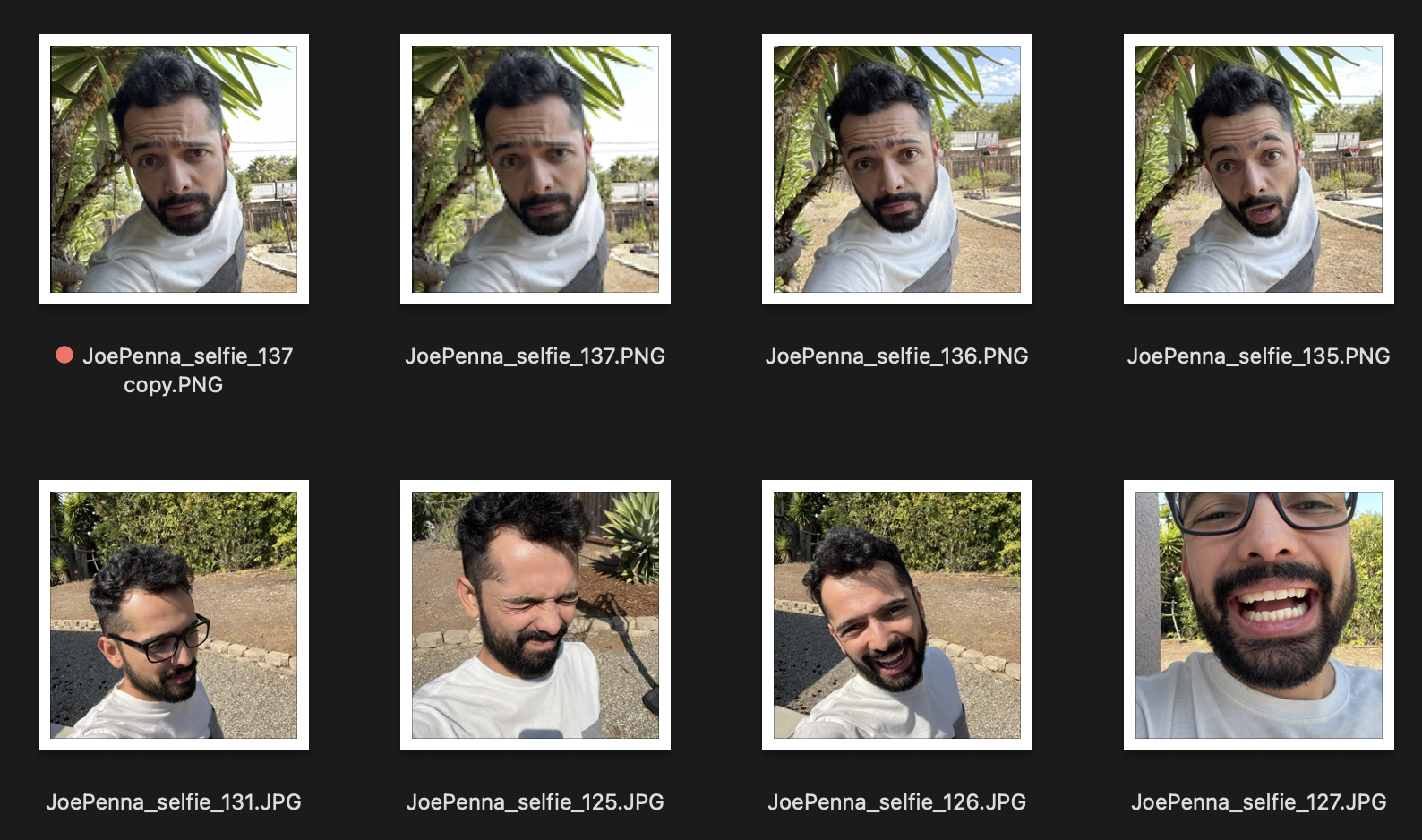
您只會以...的風格,即自拍照片的風格,穿著一件白色和灰色的襯衫,將幾代人的幾代人帶到一棵尖刺的樹旁邊。
相反,這套訓練組好多了:
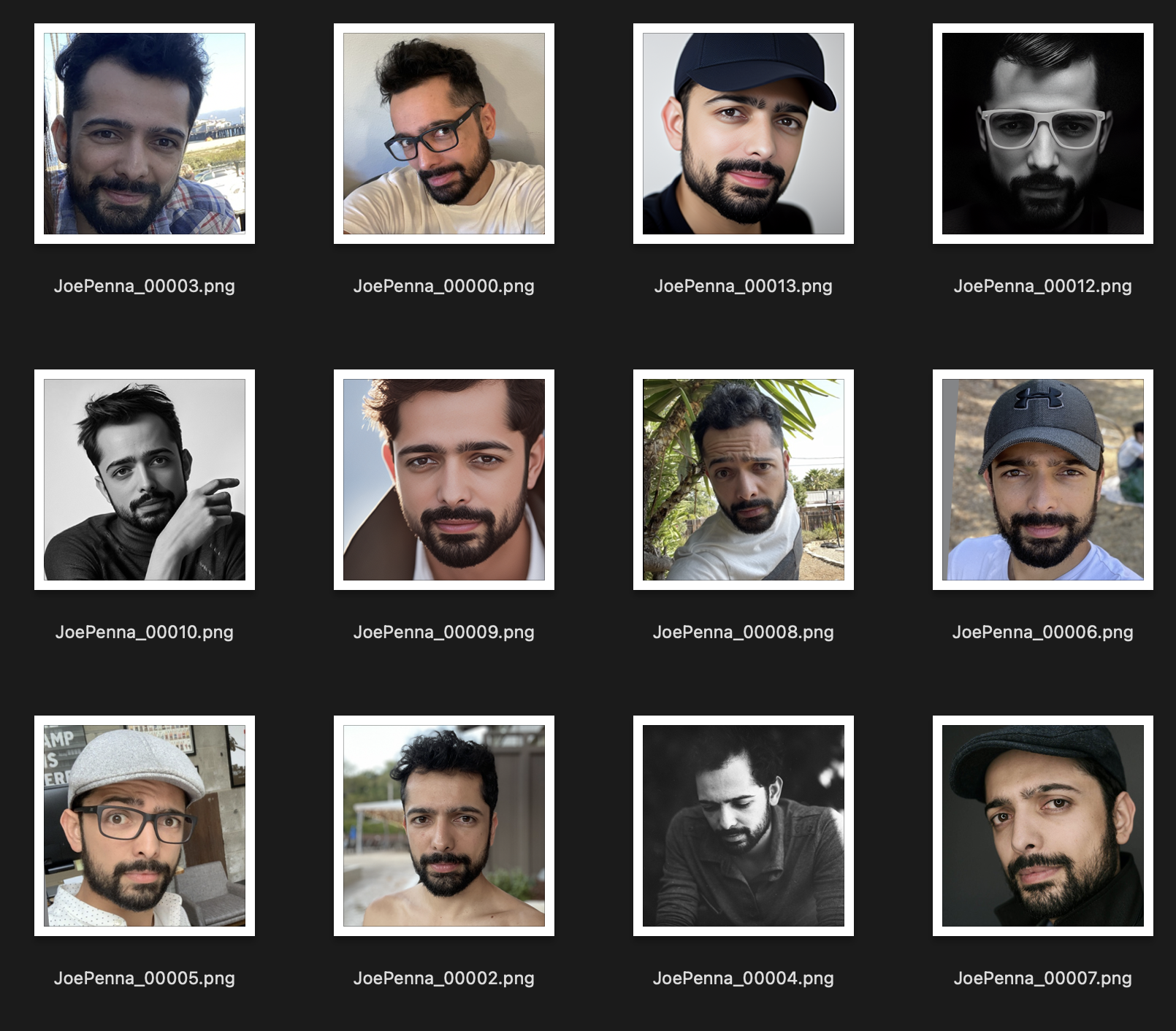
圖像之間唯一一致的是主題。因此,穩定將瀏覽圖像並僅學習您的臉部,這將使其“編輯”為其他樣式。
您確定要提示嗎?
它應該是<token> <class> ,而不僅僅是<token> 。例如:
JoePenna person, portrait photograph, 85mm medium format photo
如果它看起來仍然不像您,那麼您的訓練時間不會足夠長。
好的,原因是:您可能已經訓練了太久了……或者您的圖像太相似了……或者您沒有訓練足夠的圖像。
沒問題。我們可以通過提示來解決這個問題。穩定的擴散對您首先輸入的任何內容都具有很大的優點。因此,請保存以備以稍後:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
你沒有足夠長的時間...
沒問題。我們可以通過提示來解決此問題:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
現在,Dreambooth在擁抱面擴散器方面得到了支持,可以通過穩定的擴散進行訓練。
在這裡嘗試:


