Dreambooth Stable Diffusion
1.0.0
Для бега по vast.ai
Для работы в Google Colab
Для запуска на локальном ПК (Windows)
Для запуска на локальном ПК (Ubuntu)
Адаптирование учебника Dreambooth по коридору Digital к репо joepenna's Repo
Использование подписей в Dreambooth от Joepenna

Привет! Меня зовут Джо Пенна.
Возможно, вы видели несколько моих видео на YouTube при MysteryGuitarman . Сейчас я художественный режиссер. Вы могли бы увидеть Арктику или Стауэй.
Для моих фильмов мне нужно быть в состоянии обучать конкретных актеров, реквизита, мест и т. Д. Итак, я внес несколько изменений в репо @Xavierxiao, чтобы обучать лица людей.
Я не могу выпустить все тесты для фильма, над которым я работаю, но когда я тестирую свое лицо, я выпускаю их на своей странице в Твиттере - @mysteryguitarm.
Многие из этих испытаний были сделаны с моим приятелем - Нико из коридоордигитала. Это может быть то, как вы нашли это репо!
Я не совсем кодировщик. Я просто упрямый, и я не боюсь Googling. Итак, в конце концов, некоторые действительно умные люди присоединились и вносили вклад. В этом репо, в частности: @djbielejeski @gammagec @mrsaad - но так много других в нашем разногласий!
Это больше не мой репо. Это люди, кто-то-капюна-ивица-Dreambooth-On-SD-Working-Well's!
Теперь, если вы хотите попробовать это сделать ... пожалуйста, сначала прочитайте предупреждения ниже:
Давайте уважаем тяжелую работу и творчество людей, которые провели годы, оттачивая свои навыки.
На техническую сторону:
Эта реализация не полностью реализует идеи Google о том, как сохранить скрытое пространство.
Похоже, что нет простого способа последовательно обучать двух предметов. Перед обрезкой вы получите 11-12GB файла.
~2gb Лучшая практика состоит в том, чтобы изменить токен на имя знаменитости ( примечание: токен, а не класс - поэтому ваша подсказка будет чем -то вроде: Chris Evans person ). Вот моя жена, обучающаяся с теми же настройками, за исключением токена
Примечание Runpod периодически обновляет их базовое изображение Docker, которое может привести к тому, что репо не работает. Ни одно из видео на YouTube не обновлена, но вы все равно можете следовать за ними в качестве руководства. Следуйте по типичным видео/учебникам на YouTube на YouTube, со следующими изменениями:
Изнутри страницы моих стручков,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Зарегистрируйтесь на Runpod. Не стесняйтесь использовать мою реферальную ссылку здесь, чтобы мне не приходилось платить за это (но вы это делаете).
После входа в систему выберите SECURE CLOUD или COMMUNITY CLOUD
Убедитесь, что вы нашли «высокую» скорость межвета, чтобы не тратить время и деньги на медленные загрузки
Выберите что -нибудь с по крайней мере 24 ГБ VRAM, например RTX 3090, RTX 4090 или RTX A5000
Следуйте этим видео инструкциям ниже:
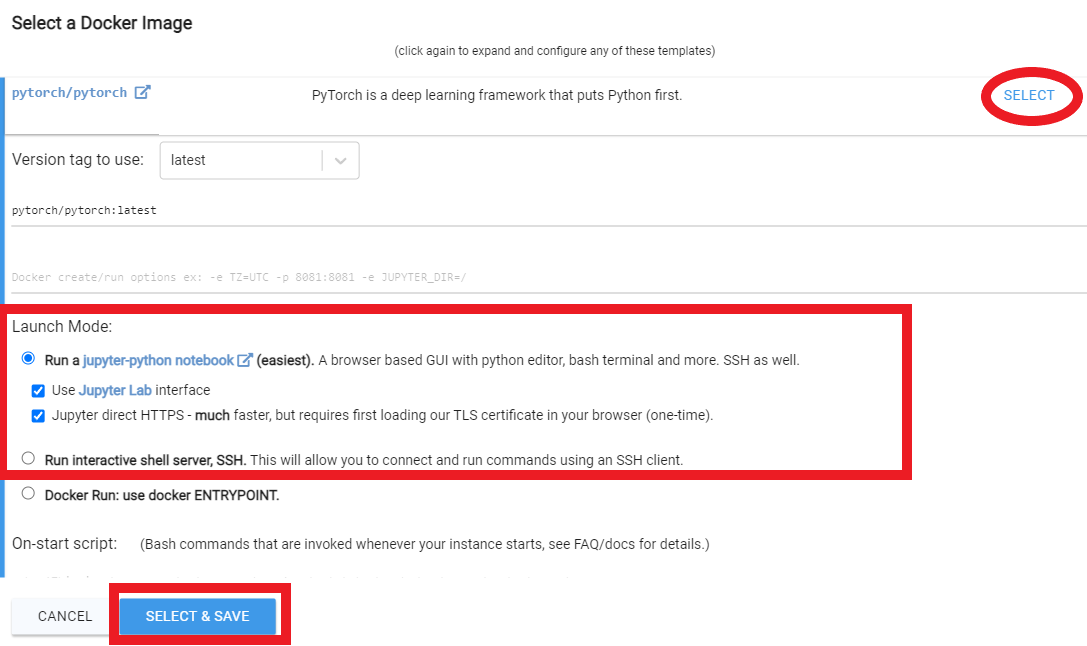
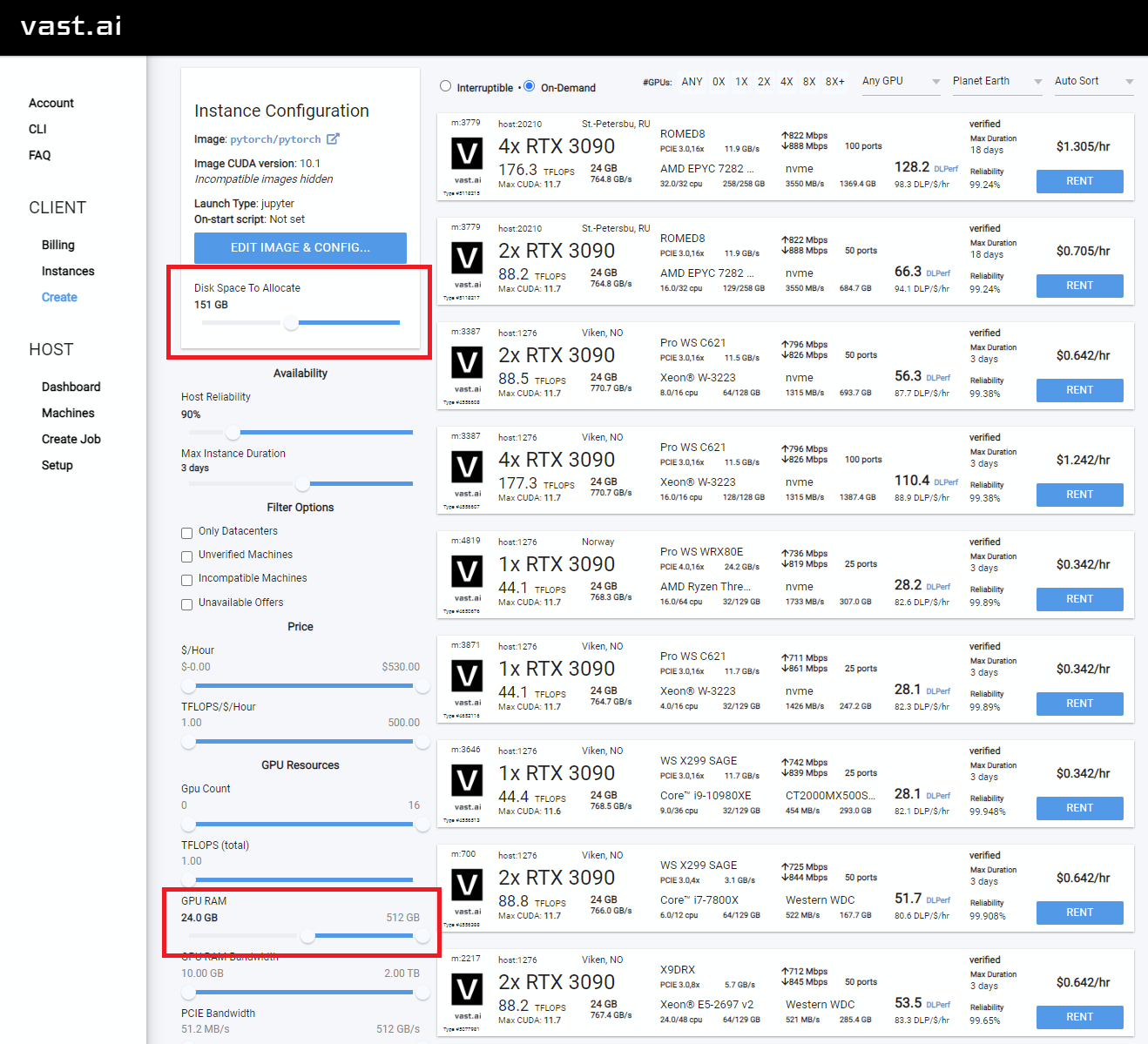
Rent , затем перейдите на страницу экземпляров и нажмите Open 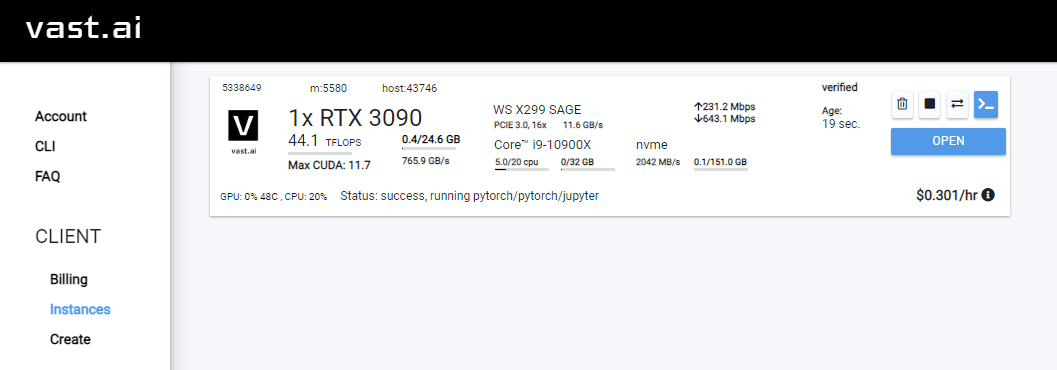
Notebook -> Python 3 (вы можете сделать это следующий шаг несколько способов, но я обычно делаю это) 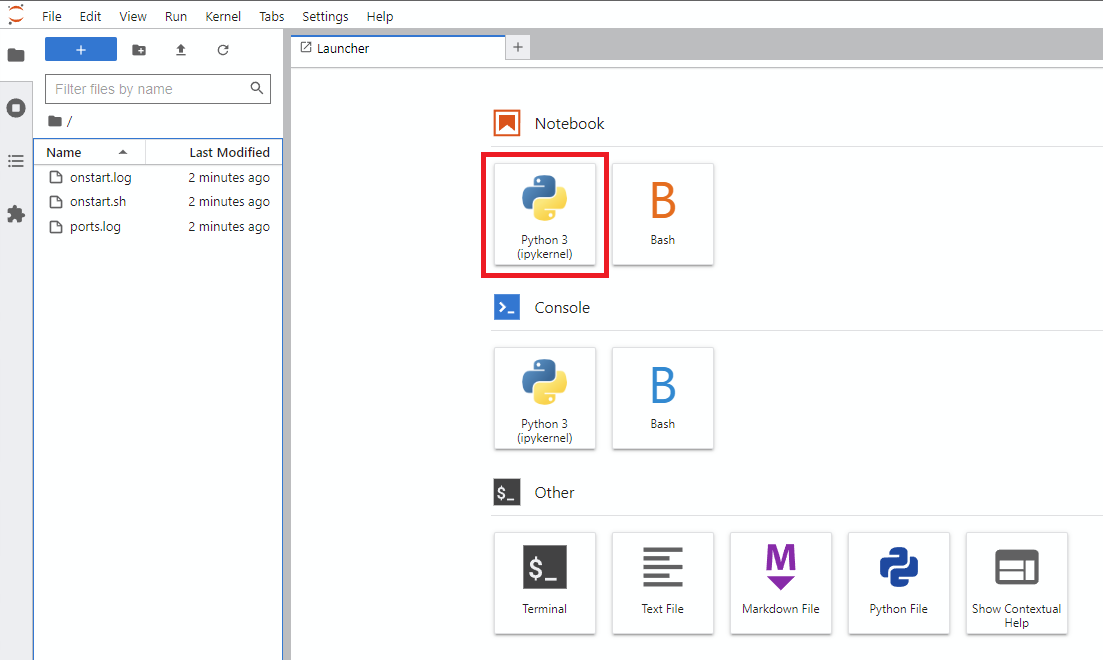
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion слева и откройте dreambooth_simple_joepenna.ipynb или dreambooth_runpod_joepenna.ipynb файл 
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
Dreambooth_helpers arguments.py
| Командование | Тип | Пример | Описание |
|---|---|---|---|
--config_file_path | нить | "C:\Users\David\Dreambooth Configs\my-config.json" | Путь к файлу конфигурации для использования |
--project_name | нить | "My Project Name" | Название проекта |
--debug | буль | False | Необязательные значения по умолчанию на False . Включить журнал отладки |
--seed | инт | 23 | Необязательные значения по умолчанию до 23 . Семя для SEED_EVERYTHING |
--max_training_steps | инт | 3000 | Количество учебных шагов для запуска |
--token | нить | "owhx" | Уникальный токен, который вы хотите представить свою обученную модель. |
--token_only | буль | False | Необязательные значения по умолчанию на False . Тренируйте только с использованием токена и без класса. |
--training_model | нить | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Путь к модели для обучения (model.ckpt) |
--training_images | нить | "D:\stable-diffusion\training_images\24 Images - captioned" | Справочник по пути к обучению изображений |
--regularization_images | нить | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Путь к каталогу с изображениями регуляризации |
--class_word | нить | "woman" | Сопоставьте Class_word с категорией изображений, которые вы хотите тренировать. Пример: man , woman , dog или artstyle . |
--flip_p | плавать | 0.0 | Необязательные значения по умолчанию до 0.5 . Перевернутый процент. Пример: если установить на 0.5 , перевернете (зеркало) ваши тренировочные изображения в 50% случаев. Это помогает расширить ваш набор данных без необходимости включать больше учебных изображений. Это может привести к худшим результатам для обучения лица, поскольку лица большинства людей не являются совершенно симметричными. |
--learning_rate | плавать | 1.0e-06 | Необязательные значения по умолчанию до 1.0e-06 (0,000001). Установите скорость обучения. Принимает научную нотацию. |
--save_every_x_steps | инт | 250 | Необязательные значения по умолчанию к 0 . Сохраняет контрольно -пропускной пункт каждые x шаги. В 0 сохраняется только в конце обучения, когда достигнут max_training_steps . |
--gpu | инт | 0 | Необязательные значения по умолчанию к 0 . Укажите графический процессор, отличный от 0, чтобы использовать для обучения. Поддержка с несколькими GPU в настоящее время не реализована. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Подписи поддерживаются. Вот руководство о том, как мы их реализовали.
Допустим, ваш токен эффект, а ваш класс - это человек, ваш корень данных - это /обучение:
training_images/img-001.jpg подписан на effy person
Вы можете настроить подпись, добавив его после символа @ в имени файла.
/training_images/img-001@a photo of effy => a photo of effy
Вы можете использовать два токена в своих подписных S -прописных S - и C - Overscare C - для указания субъекта и класса.
/training_images/img-001@S being a good C.jpg => effy being a good person
Чтобы создать новый предмет, вам просто нужно создать для нее папку. Так:
/training_images/bingo/img-001.jpg => bingo person
Класс остается прежним, но теперь субъект изменился.
Опять же - токен S теперь бинго:
/training_images/bingo/img-001@S is being silly.jpg bingo is being silly
Одна папка глубже, и вы можете изменить класс: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
Нет, Kicker: на один уровень глубже, и вы можете подписать группу изображений: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
Большая часть кода в этом репо была написана Rinon Gal et. Аль, авторы исследовательской работы текстовой инверсии. Хотя было добавлено несколько идей о регуляризации изображений и предварительного сохранения потерь (идеи из «Dreambooth»), из уважения как к команде MIT, так и исследователям Google, я переименую эту вилку: «Репо, ранее известное как» Dreambooth "" .
Для альтернативной реализации см. «Альтернативный вариант» ниже.
ground truth (настоящая картина, осторожность: очень красивая женщина) 
Такая же подсказка для всех этих изображений ниже:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Подсказка только с вашим токеном. т.е. "joepenna" вместо "joepenna person"
Если вы тренировались с joepenna под классным person , модель должна знать только ваше лицо как:
joepenna person
Пример подсказки:
Неправильно (пропал без person следуя joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ Это правильно ( person включен после joepenna )
portrait photograph of joepenna person 35mm film vintage glass
Иногда вы можете получить кого -то, кто выглядит как вы с Joepenna (особенно, если вы тренировались для слишком многих шагов), но это только потому, что эта текущая итерация Dreambooth Overtrains, что токен настолько сильно кровоточил в этот токен.
Во время обучения стабиль не знает, что вы человек. Это просто имитирует то, что он видит.
Итак, если это ваши учебные изображения, выглядят так:
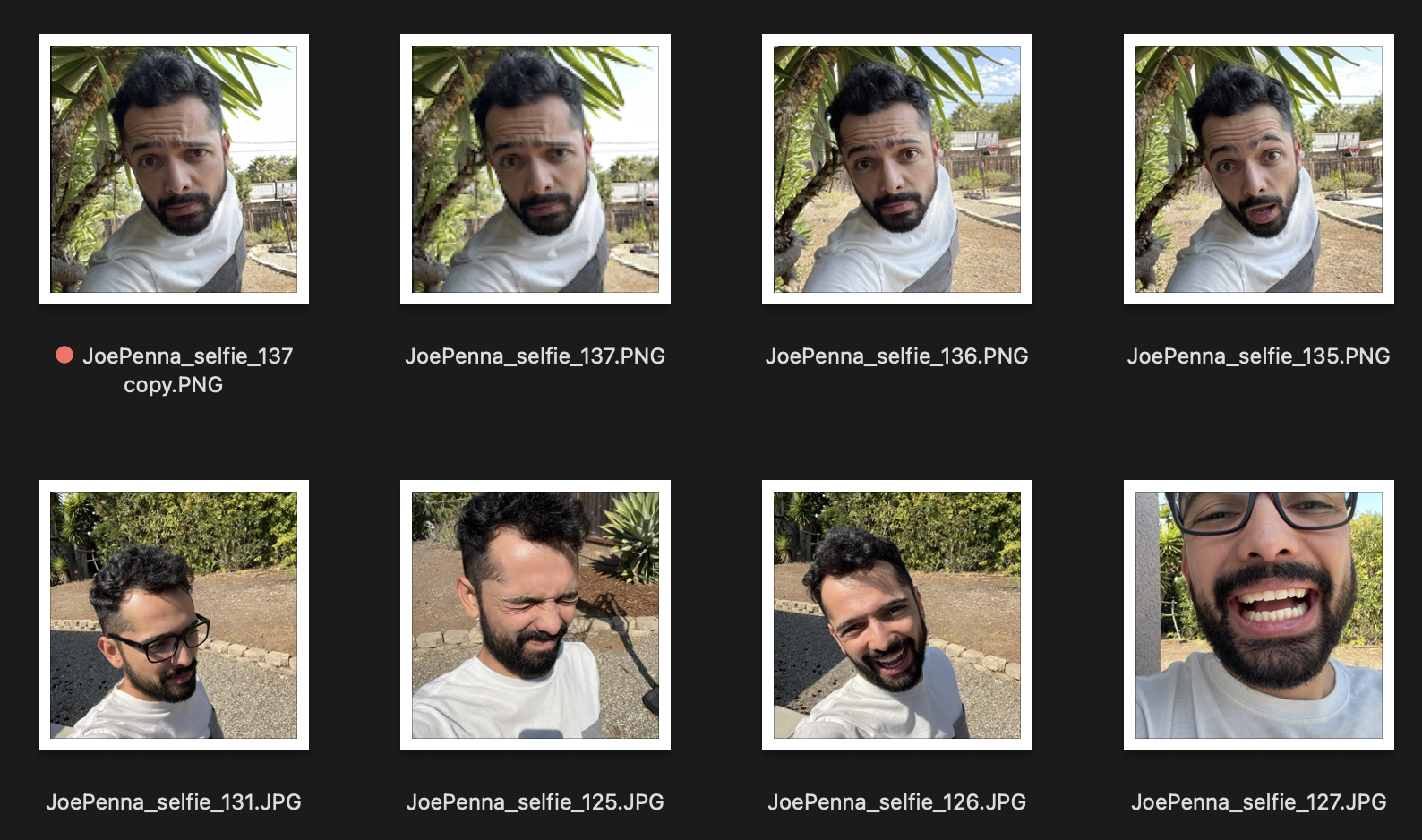
Вы только получите поколения вас на улице рядом с колючее дерево, одетая в белую и серую рубашку, в стиле ... ну, селфи-фотография.
Вместо этого этот тренировочный набор намного лучше:
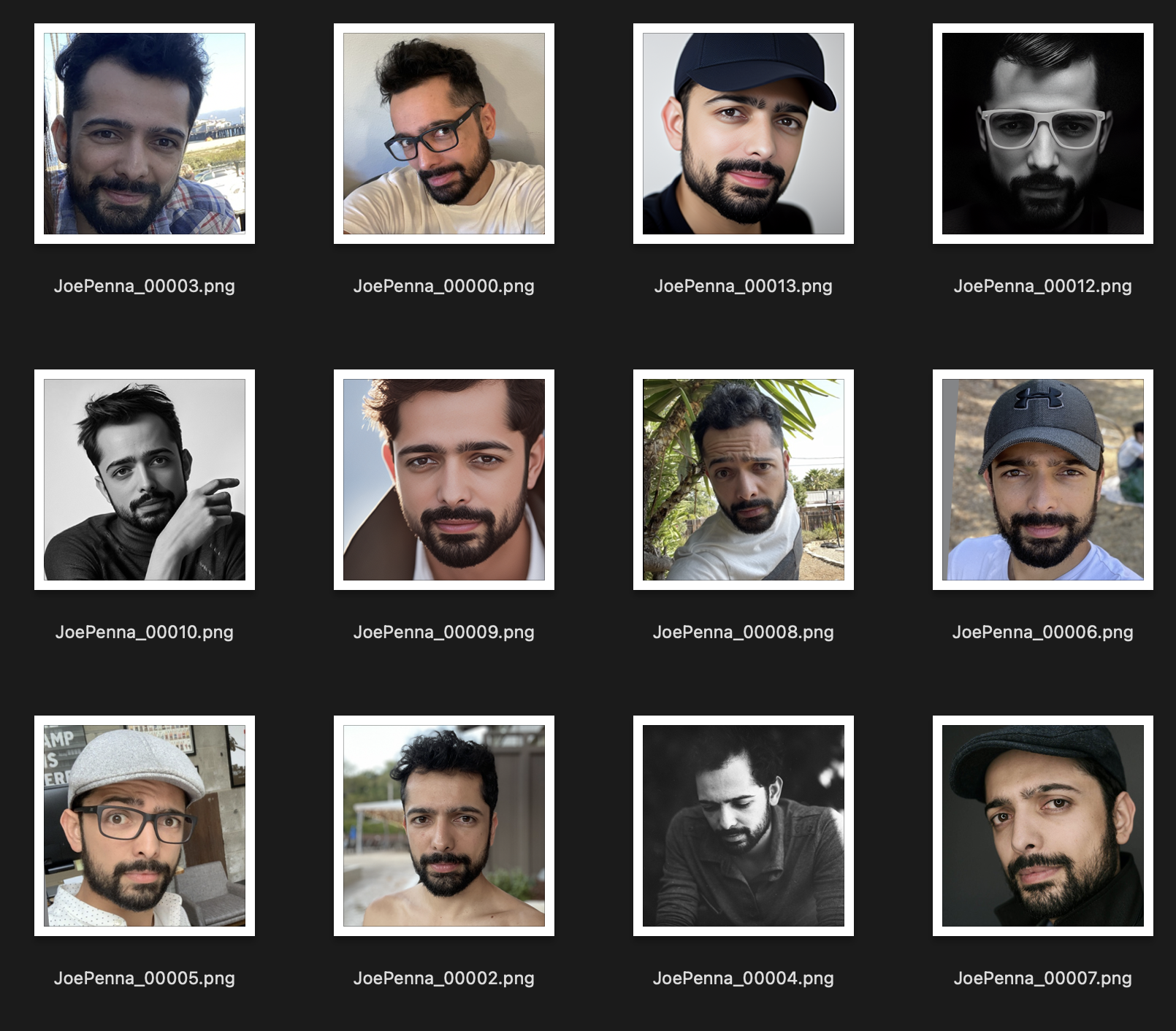
Единственная вещь, которая согласована между изображениями, - это предмет. Таким образом, стабильный будет просмотреть изображения и изучать только ваше лицо, что сделает «редактирование» его в другие стили.
Вы уверены, что побуждаете это правильно?
Это должно быть <token> <class> , а не только <token> . Например:
JoePenna person, portrait photograph, 85mm medium format photo
Если это все еще не похоже на вас, вы не тренировались достаточно долго.
Хорошо, несколько причин, почему: вы, возможно, тренировались слишком долго ... или ваши изображения были слишком похожи ... или вы не тренировались с достаточным количеством изображений.
Без проблем. Мы можем исправить это с помощью подсказки. Стабильная диффузия ставит много заслуг в то, что вы вводите в первую очередь. Так что сохраните его на потом:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
Ты не тренировался достаточно долго ...
Без проблем. Мы можем исправить это с помощью подсказки:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
Dreambooth теперь поддерживается в диффузорах HuggingFace для обучения со стабильной диффузией.
Попробуйте это здесь:


