Dreambooth Stable Diffusion
1.0.0
vast.aiで実行するため
Google Colabで実行するため
ローカルPC(Windows)で実行するため
ローカルPCで実行するため(ubuntu)
Corridor DigitalのDreamboothチュートリアルをJoepennaのレポに適応させます
JoepennaのDreamboothのキャプションを使用します

こんにちは!私の名前はジョーペンナです。
Mysterguitarmanの下で私のYouTubeビデオをいくつか見たことがあるかもしれません。私は今長編映画監督です。あなたは北極圏やstowawayを見たことがあるかもしれません。
私の映画では、特定の俳優、小道具、場所などを訓練できる必要があります。そのため、人々の顔を訓練するために @Xavierxiaoのリポジトリにたくさんの変更を加えました。
取り組んでいる映画のすべてのテストをリリースすることはできませんが、自分の顔でテストすると、Twitterページ@mysteryguitarmでそれらをリリースします。
これらのテストの多くは、CorridordigitalのNikoである私の仲間で行われました。このレポを見つけた方法かもしれません!
私は本当にコーダーではありません。私はただ頑固で、グーグルを恐れていません。そのため、最終的には、本当に賢い人々が参加し、貢献してきました。このレポでは、具体的には:@djbielejeski @gammagec @mrsaad - しかし、他の多くの人が私たちの不一致です!
これはもう私のレポではありません。これは、Who-Who-wanna-see-see-dreambooth-on-sdworking-wellのレポです!
さて、これをやろうとしている場合は...以下の警告を最初に読んでください。
スキルを磨くために何年も費やしてきた人々の努力と創造性を尊重しましょう。
技術的な側面:
この実装では、潜在スペースを維持する方法に関するGoogleのアイデアを完全に実装していません。
2つの被験者を連続して訓練する簡単な方法はないようです。剪定前に11-12GBファイルになります。
~2gbに押し下げるプルナーがありますベストプラクティスは、トークンを有名人の名前に変更することです(注:トークン、クラスではなく、プロンプト: Chris Evans personのようなものになります)。これがトークンを除いて、まったく同じ設定で訓練された私の妻です
Runpodは、レポが機能しないことにつながる可能性のあるベースDockerイメージを定期的にアップグレードします。 YouTubeビデオはどれも最新ではありませんが、ガイドとしてフォローすることができます。典型的なRunpod YouTubeビデオ/チュートリアルをフォローしてください。
My Podsページ内から、
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Runpodにサインアップします。ここで私の紹介リンクを自由に使用してください。
ログインした後、 SECURE CLOUDまたはCOMMUNITY CLOUDいずれかを選択します
ゆっくりしたダウンロードで時間とお金を無駄にしないように、「高い」間に間に、速度を見つけるようにしてください
RTX 3090、RTX 4090、RTX A5000などの少なくとも24GB VRAMを選択します
以下に次のようなビデオの指示に従ってください。
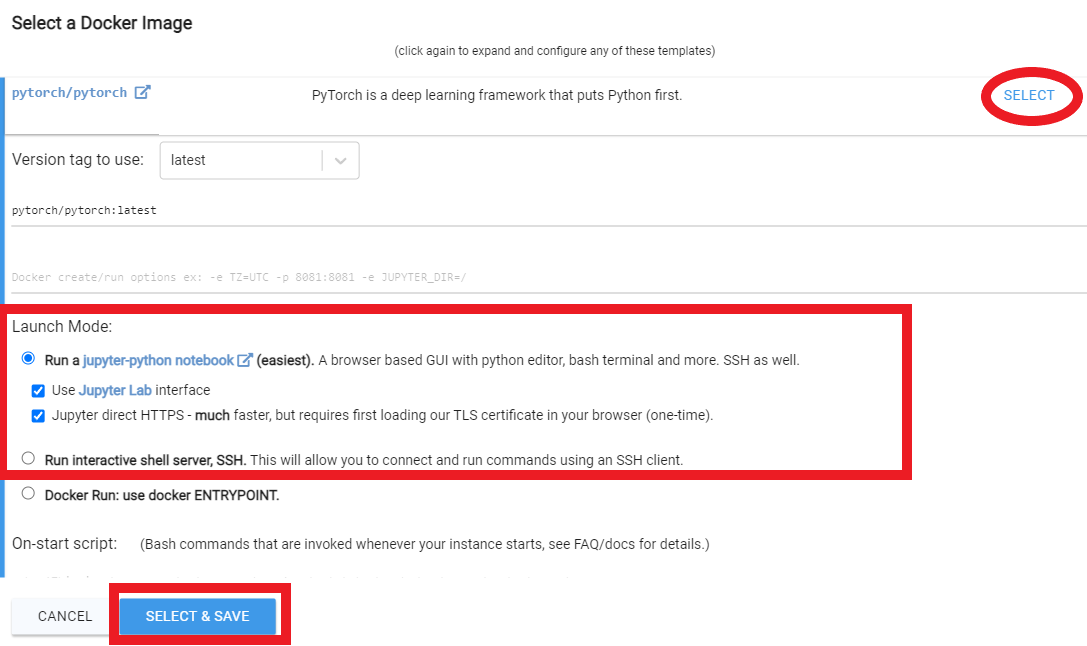
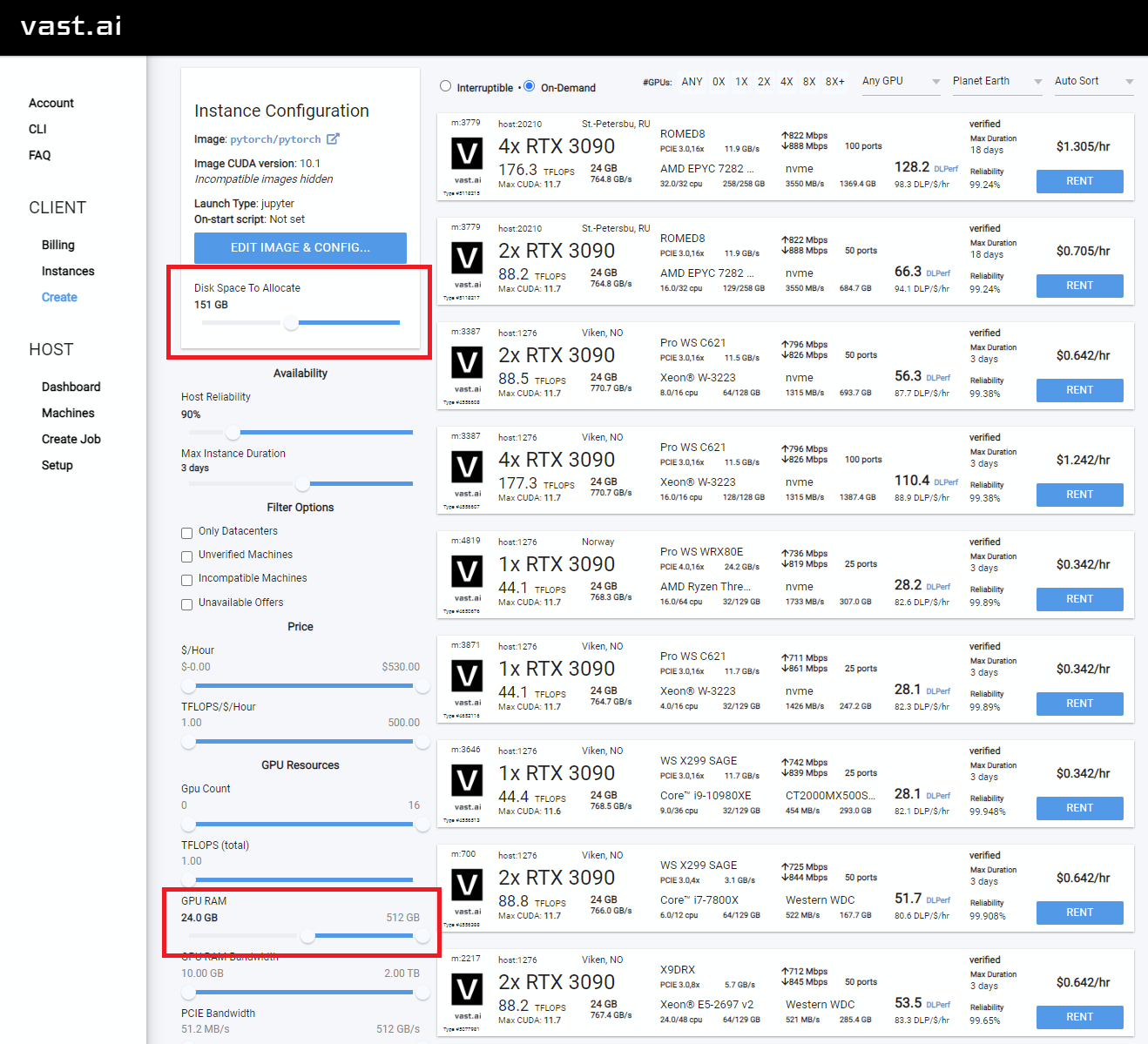
Rentをクリックし、[インスタンス]ページに移動してOpenクリックします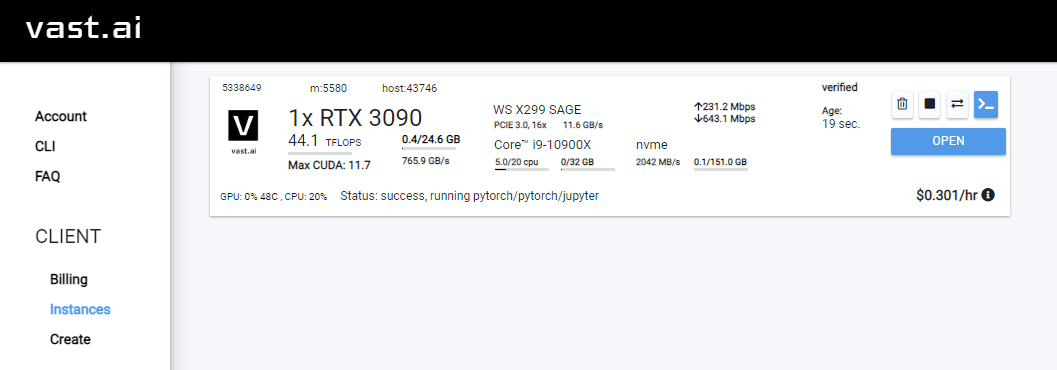
Notebook -> Python 3をクリックします(次のステップをいくつかの方法で行うことができますが、通常はこれを行います) 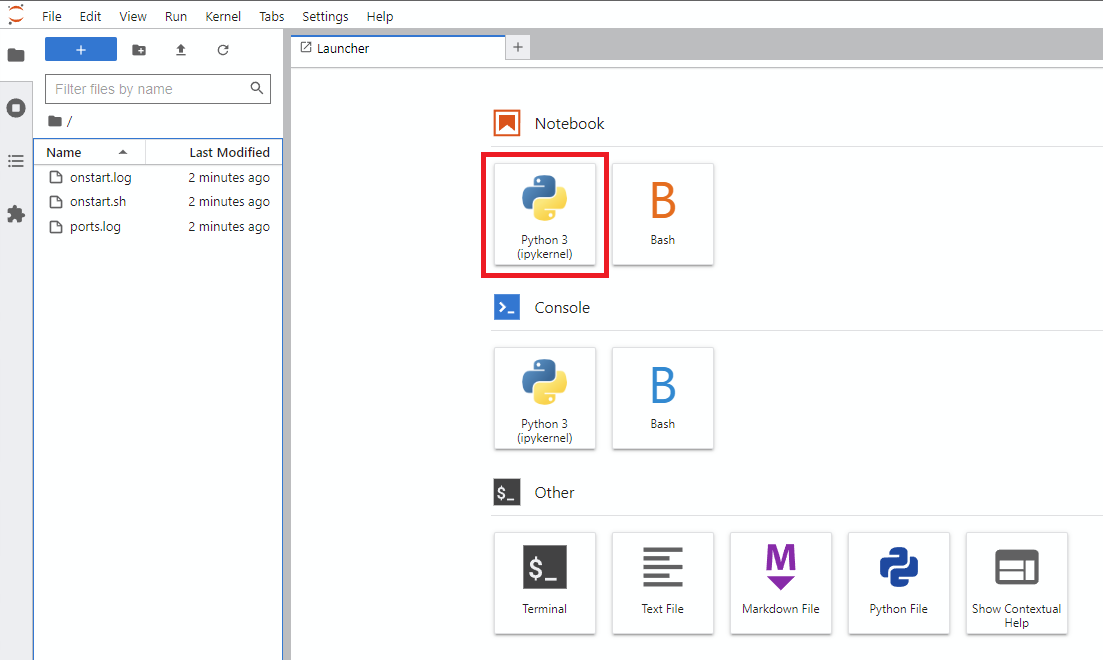
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrunをクリックします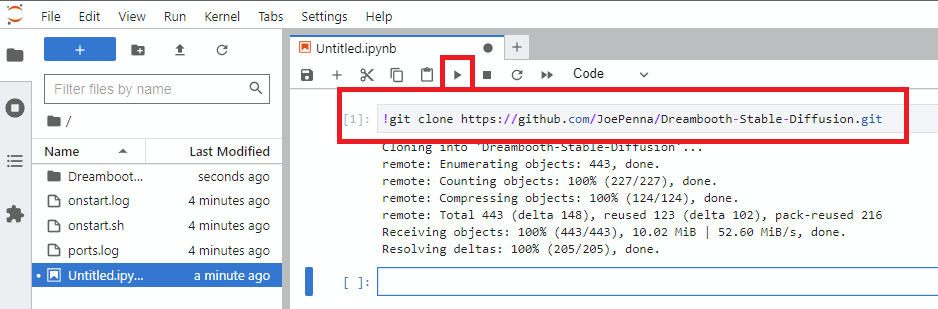
Dreambooth-Stable-Diffusionディレクトリに移動し、 dreambooth_simple_joepenna.ipynbまたはdreambooth_runpod_joepenna.ipynbファイルのいずれかを開きます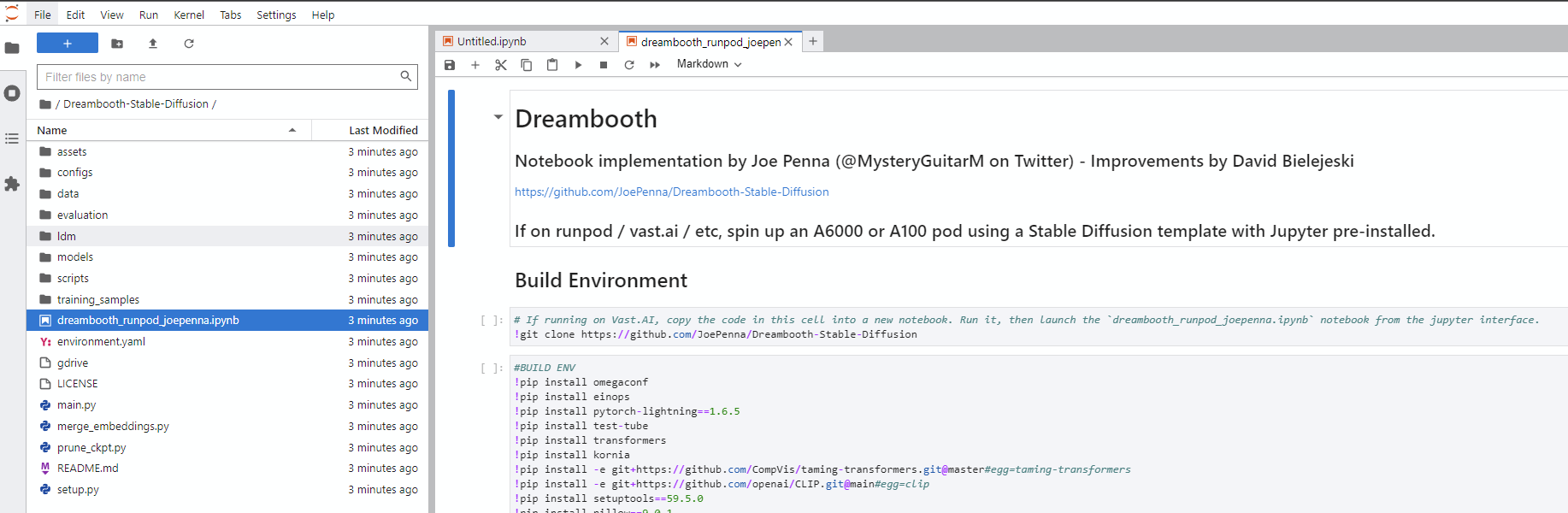
cmdを開きますC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txtcmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepennacmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers arguments.py
| 指示 | タイプ | 例 | 説明 |
|---|---|---|---|
--config_file_path | 弦 | "C:\Users\David\Dreambooth Configs\my-config.json" | 構成ファイルを使用するパス |
--project_name | 弦 | "My Project Name" | プロジェクトの名前 |
--debug | ブール | False | オプションのデフォルトはFalseです。デバッグロギングを有効にします |
--seed | int | 23 | オプションのデフォルトは23です。 Seed_Everythingのシード |
--max_training_steps | int | 3000 | 実行するためのトレーニング手順の数 |
--token | 弦 | "owhx" | 訓練されたモデルを表現したいユニークなトークン。 |
--token_only | ブール | False | オプションのデフォルトはFalseです。トークンとクラスなしのみを使用してトレーニングします。 |
--training_model | 弦 | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | モデルへのトレーニングへのパス(model.ckpt) |
--training_images | 弦 | "D:\stable-diffusion\training_images\24 Images - captioned" | 画像のトレーニングへのパスディレクトリ |
--regularization_images | 弦 | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | 正規化画像を備えたディレクトリへのパス |
--class_word | 弦 | "woman" | class_wordをトレーニングしたい画像のカテゴリに一致させます。例: man 、 woman 、 dog 、またはartstyle 。 |
--flip_p | フロート | 0.0 | オプションのデフォルトは0.5です。フリップパーセンテージ。例: 0.5に設定すると、トレーニング画像が50%の時間をフリップ(ミラー)します。これにより、より多くのトレーニング画像を含める必要なく、データセットを拡張することができます。ほとんどの人の顔は完全に対称的ではないため、これはフェイストレーニングの結果が悪化する可能性があります。 |
--learning_rate | フロート | 1.0e-06 | オプションのデフォルトは1.0e-06 (0.000001)です。学習率を設定します。科学的表記を受け入れます。 |
--save_every_x_steps | int | 250 | オプションのデフォルトは0です。 xステップごとにチェックポイントを保存します。 0では、 max_training_stepsに到達したときにトレーニングの終了時にのみ保存します。 |
--gpu | int | 0 | オプションのデフォルトは0です。トレーニングに使用するには、0以外のGPUを指定します。マルチGPUサポートは現在実装されていません。 |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
キャプションがサポートされています。これらの実装方法に関するガイドは次のとおりです。
あなたのトークンが効果であり、あなたのクラスは人であり、あなたのデータルートは /トレーニングであるとしましょう。
training_images/img-001.jpgは、 effy personでキャプションを付けられています
ファイル名の@シンボルの後に追加することで、キャプションをカスタマイズできます。
/training_images/img-001@a photo of effy => a photo of effy
キャプションS大文字とC大文字C-の2つのトークンを使用して、サブジェクトとクラスを示します。
/training_images/img-001@S being a good C.jpg => effy being a good personあること
新しいサブジェクトを作成するには、フォルダーを作成するだけです。それで:
/training_images/bingo/img-001.jpg => bingo person
クラスは同じままですが、今では被験者が変わっています。
繰り返します - トークンSは今ビンゴです:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
1つのフォルダーがより深く、クラスを変更できます: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
キッカーが来ます:1つのレベルの深く、あなたは画像のグループをキャプションできます: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
このレポのコードの大部分は、Rinon Gal etによって書かれました。 Al、テキストInversion Research Paperの著者。正規化画像と以前の損失の保存(「Dreambooth」のアイデア)についてのいくつかのアイデアが追加されましたが、MITチームとGoogleの研究者の両方に敬意を表して、私はこのフォークに「以前は知られていたレポ」に名前を変更しました。 DreamBooth "" 。
別の実装については、以下の「代替オプション」を参照してください。
ground truth (本当の写真、注意:非常に美しい女性) 
以下のこれらすべての画像について同じプロンプト:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
トークンだけでプロンプト。つまり、「ジョペンナの人」の代わりに「ジョペンナ」
クラスのpersonの下でjoepennaと訓練した場合、モデルはあなたの顔のみを知っている必要があります。
joepenna person
プロンプトの例:
間違っている( joepenna後のperson不明者)
portrait photograph of joepenna 35mm film vintage glass
✅これは正しい( person joepenna後に含まれている)
portrait photograph of joepenna person 35mm film vintage glass
Joepennaと一緒にあなたのように見える人を獲得することがあります(特に、あまりにも多くのステップで訓練した場合)が、それは、このトークンのこのトレインのこの現在の繰り返しがそのトークンに出血するからです。
トレーニング中、Stableはあなたが人であることを知りません。それが見るものを模倣するだけです。
したがって、これらがあなたのトレーニング画像のように見える場合:
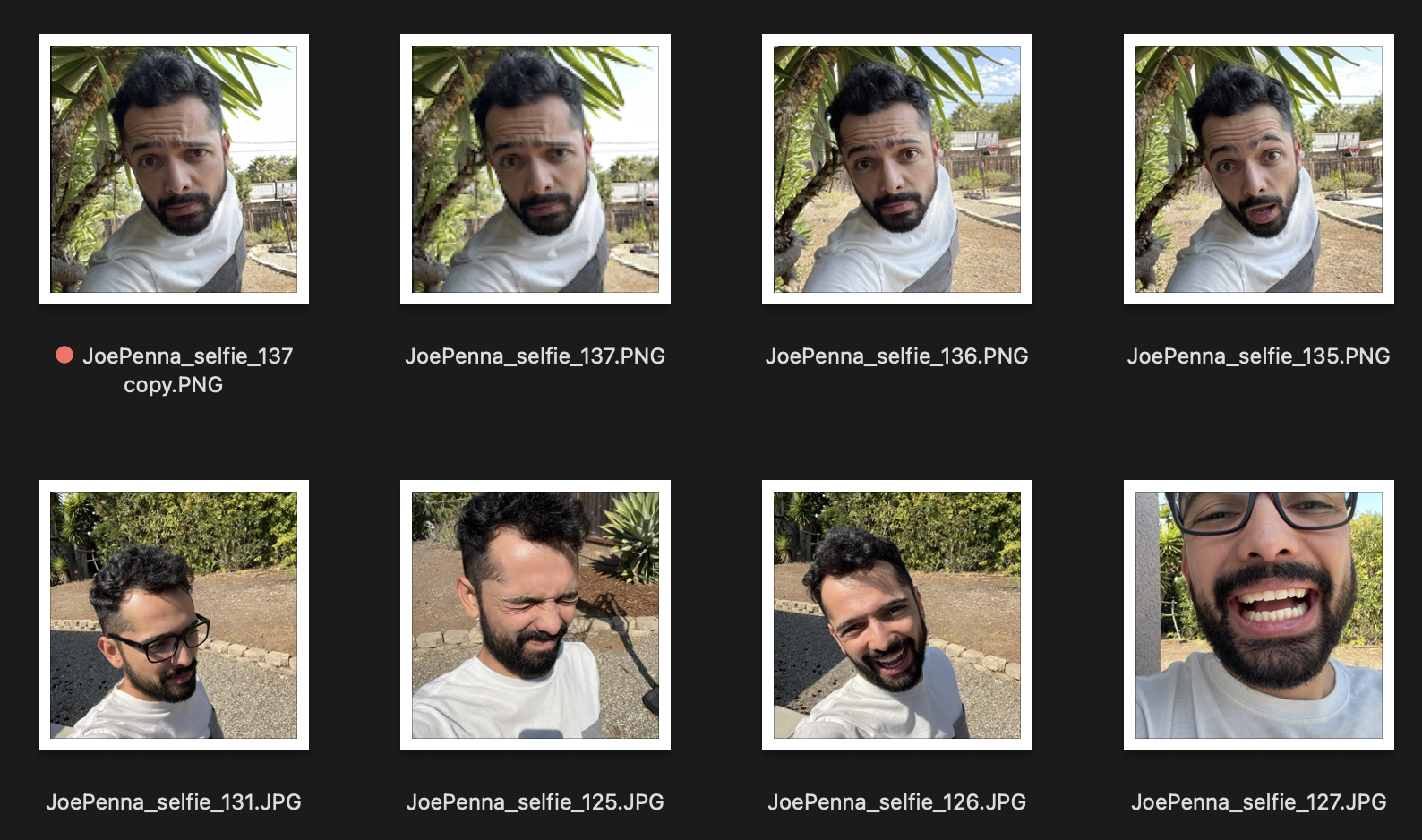
あなたは、白と灰色のシャツを着て、スパイクの木の隣に何世代にもわたってあなたの何世代にもわたって...
代わりに、このトレーニングセットははるかに優れています:
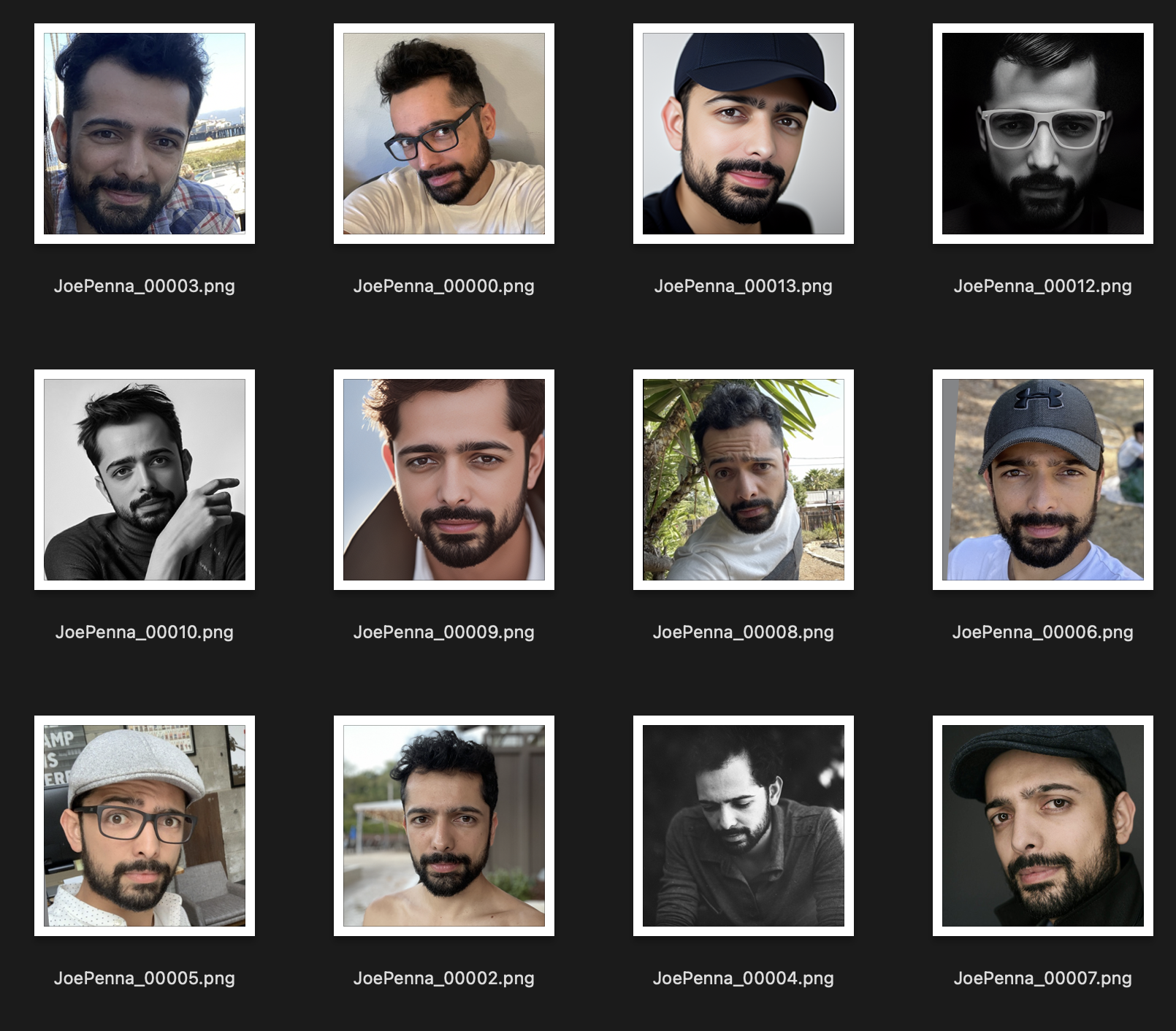
画像間で一貫しているのは主題です。したがって、安定したものは画像を通して見て、顔のみを学習し、それを他のスタイルに「編集」します。
あなたはそれを促していると確信していますか?
<token> <class> <token>ある必要があります。例えば:
JoePenna person, portrait photograph, 85mm medium format photo
それでもあなたのように見えない場合、あなたは十分に長く訓練しませんでした。
さて、いくつかの理由:あなたはあまりにも長く訓練したかもしれません...またはあなたの画像があまりにも似ていたか、あなたは十分な画像で訓練しませんでした。
問題ない。プロンプトでそれを修正できます。安定した拡散は、最初に入力するものに多くのメリットを置きます。したがって、後で保存してください:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
あなたは十分に長く訓練しませんでした...
問題ない。プロンプトでそれを修正できます:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
DreamBoothは、安定した拡散を備えたトレーニングのために、ハグFace Diffusersでサポートされています。
ここで試してみてください:


