Dreambooth Stable Diffusion
1.0.0
Para correr em vast.ai
Para correr no Google Colab
Para executar em um PC local (Windows)
Para executar em um PC local (Ubuntu)
Adaptando o tutorial Dreambooth do Corredor Digital para o repositório de Joepenna
Usando legendas no Dreambooth de Joepenna

Oi! Meu nome é Joe Penna.
Você pode ter visto alguns meus vídeos do YouTube em Mysteryguitarman . Agora sou um diretor de longa -metragem. Você pode ter visto o Ártico ou o Stowaway.
Para meus filmes, preciso poder treinar atores, adereços, locais, etc. Então, fiz várias mudanças no repositório de @Xavierxiao para treinar o rosto das pessoas.
Não posso lançar todos os testes para o filme em que estou trabalhando, mas quando testo com meu próprio rosto, ligo -os na minha página do Twitter - @MySteryGuitarArm.
Muitos desses testes foram feitos com um amigo meu - Niko da Corridordigital. Pode ser como você encontrou este repositório!
Eu não sou realmente um codificador. Eu sou apenas teimoso e não tenho medo de pesquisar no Google. Então, eventualmente, algumas pessoas realmente inteligentes se juntaram e têm contribuído. Neste repositório, especificamente: @djbielejeski @gammagec @mrsaad - mas tantos outros em nossa discórdia!
Este não é mais o meu repositório. Este é o povo-que-wanna-veja-dreambooth-on-sd working-well's Repo!
Agora, se você quiser tentar fazer isso ... por favor, leia os avisos abaixo primeiro:
Vamos respeitar o trabalho duro e a criatividade das pessoas que passaram anos aprimorando suas habilidades.
No lado técnico:
Esta implementação não implementa totalmente as idéias do Google sobre como preservar o espaço latente.
Não parece haver uma maneira fácil de treinar dois assuntos consecutivamente. Você acabará com um arquivo 11-12GB antes da poda.
~2gb A melhor prática é alterar o token para um nome de celebridade ( note: token, não classe - então seu prompt seria algo como: Chris Evans person ). Aqui está minha esposa treinou exatamente as mesmas configurações, exceto o token
Nota Runpod Atualize periodicamente sua imagem básica do Docker, que pode levar ao Repo não funcionar. Nenhum dos vídeos do YouTube está atualizado, mas você ainda pode segui -los como um guia. Siga os vídeos/tutoriais típicos do Runpod YouTube, com as seguintes alterações:
De dentro da página My Pods,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Inscreva -se no Runpod. Sinta -se à vontade para usar meu link de referência aqui, para que eu não precise pagar por isso (mas você o faz).
Após o login, selecione SECURE CLOUD ou COMMUNITY CLOUD
Certifique -se de encontrar uma velocidade "alta" do interior para não perder tempo e dinheiro em downloads lentos
Selecione algo com pelo menos 24 GB de VRAM como RTX 3090, RTX 4090 ou RTX A5000
Siga estas instruções de vídeo abaixo:
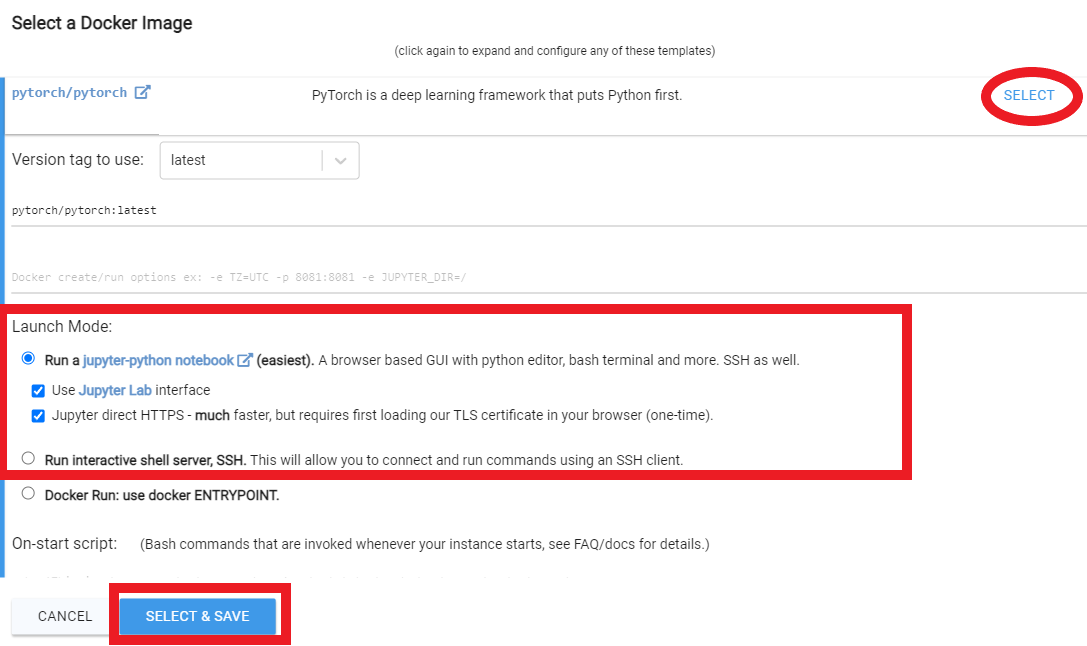
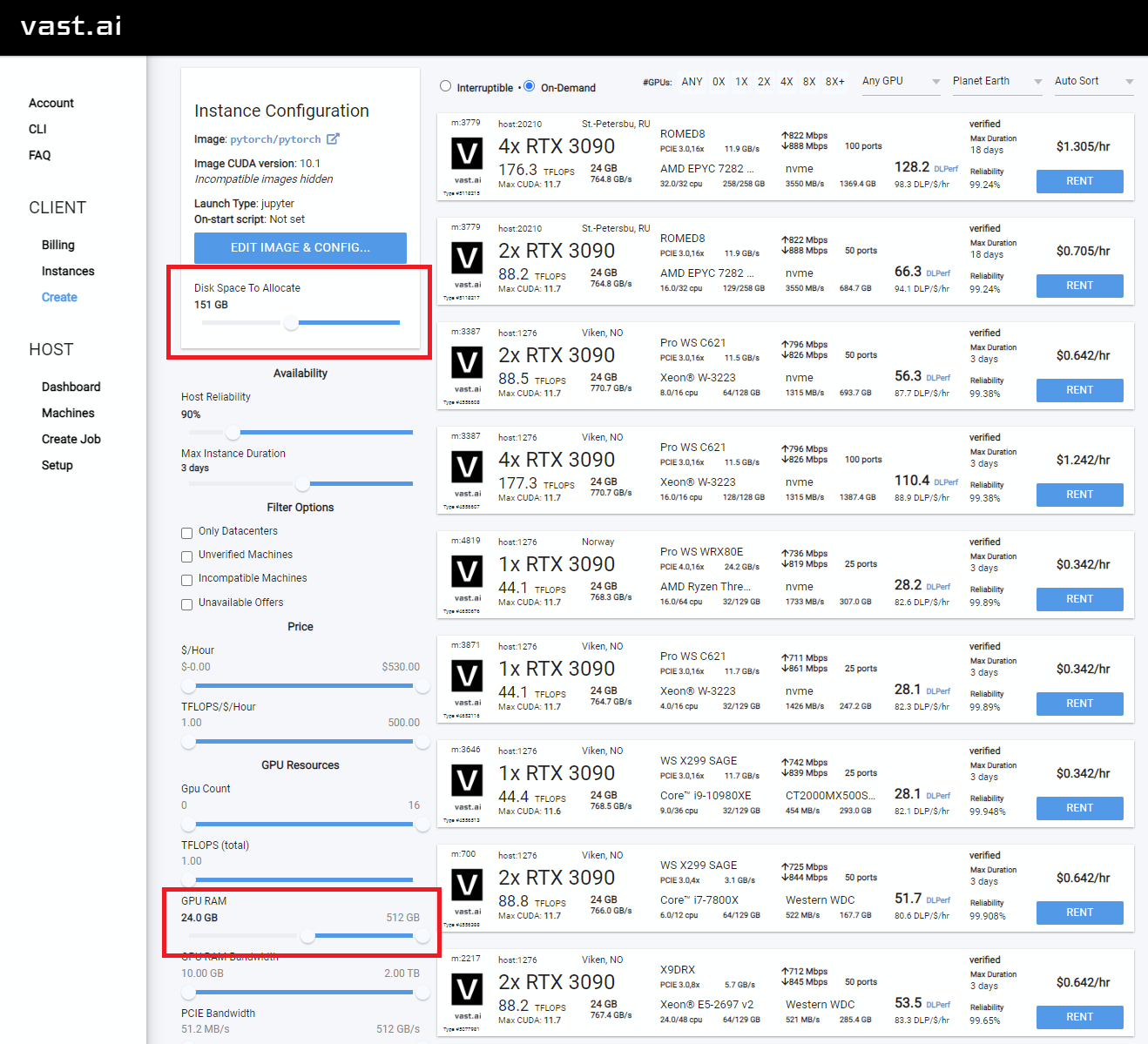
Rent , depois vá para sua página de instâncias e clique em Open 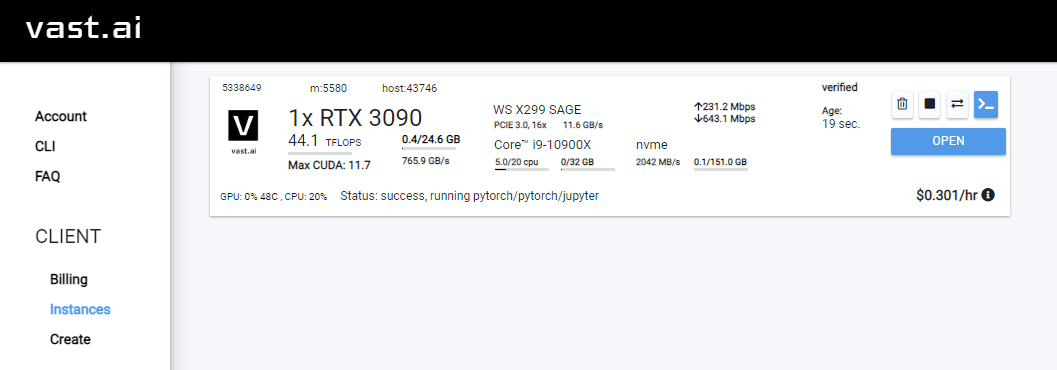
Notebook -> Python 3 (você pode fazer isso na próxima etapa de várias maneiras, mas eu normalmente faço isso) 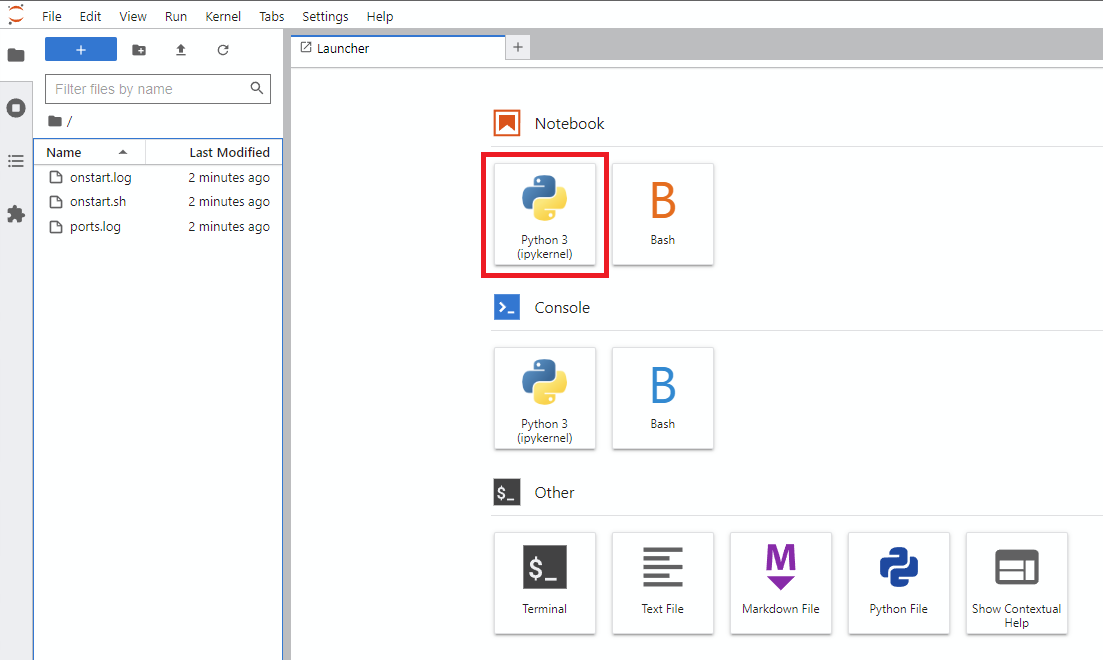
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion à esquerda e abra o arquivo dreambooth_simple_joepenna.ipynb ou dreambooth_runpod_joepenna.ipynb 
cmd abertoC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
Dreambooth_helpers argumentos.py
| Comando | Tipo | Exemplo | Descrição |
|---|---|---|---|
--config_file_path | corda | "C:\Users\David\Dreambooth Configs\my-config.json" | O caminho do arquivo de configuração para usar |
--project_name | corda | "My Project Name" | Nome do projeto |
--debug | bool | False | Padrões opcionais para False . Ativar log de depuração |
--seed | int | 23 | Padrões opcionais para 23 . Semente para semente_everything |
--max_training_steps | int | 3000 | Número de etapas de treinamento para executar |
--token | corda | "owhx" | Token exclusivo Você deseja representar seu modelo treinado. |
--token_only | bool | False | Padrões opcionais para False . Treine apenas usando o token e nenhuma classe. |
--training_model | corda | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Caminho para modelo para treinar (Model.ckpt) |
--training_images | corda | "D:\stable-diffusion\training_images\24 Images - captioned" | Caminho para o treinamento do diretório de imagens |
--regularization_images | corda | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Caminho para diretório com imagens de regularização |
--class_word | corda | "woman" | Combine o Class_word com a categoria de imagens que você deseja treinar. Exemplo: man , woman , dog ou artstyle . |
--flip_p | flutuador | 0.0 | Padrões opcionais para 0.5 . Porcentagem de flip. Exemplo: se definido como 0.5 , virará (espelhará) suas imagens de treinamento 50% do tempo. Isso ajuda a expandir seu conjunto de dados sem precisar incluir mais imagens de treinamento. Isso pode levar a resultados piores para o treinamento de rosto, pois os rostos da maioria das pessoas não são perfeitamente simétricos. |
--learning_rate | flutuador | 1.0e-06 | Padrões opcionais para 1.0e-06 (0,000001). Defina a taxa de aprendizado. Aceita notação científica. |
--save_every_x_steps | int | 250 | Padrões opcionais para 0 . Economiza um ponto de verificação a cada x etapas. AS 0 Salva apenas no final do treinamento quando max_training_steps é alcançado. |
--gpu | int | 0 | Padrões opcionais para 0 . Especifique uma GPU diferente de 0 a ser usada para treinamento. O suporte a multi-GPU não é implementado no momento. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Legendas são suportadas. Aqui está o guia sobre como os implementamos.
Digamos que seu token é efy e sua classe é pessoa, sua raiz de dados é /trem então:
training_images/img-001.jpg é legenda com effy person
Você pode personalizar a legenda adicionando -o após um símbolo @ no nome do arquivo.
/training_images/img-001@a photo of effy => a photo of effy
Você pode usar dois tokens em suas legendas S - SPERCASE S - e C - OUPERCASE C - para indicar sujeito e classe.
/training_images/img-001@S being a good C.jpg => effy being a good person
Para criar um novo assunto, você só precisa criar uma pasta para ele. Então:
/training_images/bingo/img-001.jpg => bingo person
A classe permanece a mesma, mas agora o assunto mudou.
Novamente - o token s agora é bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
Uma pasta mais profunda e você pode alterar a classe: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
Não vem o kicker: um nível mais profundo e você pode legendar o grupo de imagens: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
A maior parte do código neste repo foi escrita por Rinon Gal et. Al, os autores do artigo de pesquisa de inversão textual. Embora algumas idéias sobre imagens de regularização e preservação de perdas anteriores (idéias de "Dreambooth") tenham sido adicionadas, por respeito à equipe do MIT e aos pesquisadores do Google, estou renomeando esse garfo para: "O repo anteriormente conhecido como" Dreambooth "" .
Para uma implementação alternativa, consulte "Opção alternativa" abaixo.
A ground truth (imagem real, cautela: mulher muito bonita) 
Mesmo aviso para todas essas imagens abaixo:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Solicitando apenas com seu token. ou seja, "Joepenna" em vez de "Joepenna Pessoa"
Se você treinou com joepenna sob a person da classe, o modelo só deve conhecer seu rosto como:
joepenna person
Exemplo de aviso:
Incorreto ( person desaparecida seguindo joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ Isso está certo ( person está incluída após joepenna )
portrait photograph of joepenna person 35mm film vintage glass
Às vezes, você pode conseguir alguém que meio que se parece com você com Joepenna (especialmente se você treinou para muitos passos), mas isso é apenas porque essa iteração atual de Dreambooth Treerave que o token tanto que sangra nesse token.
Durante o treinamento, estável não sabe que você é uma pessoa. Só vai imitar o que vê.
Então, se essas são suas imagens de treinamento, se parecem:
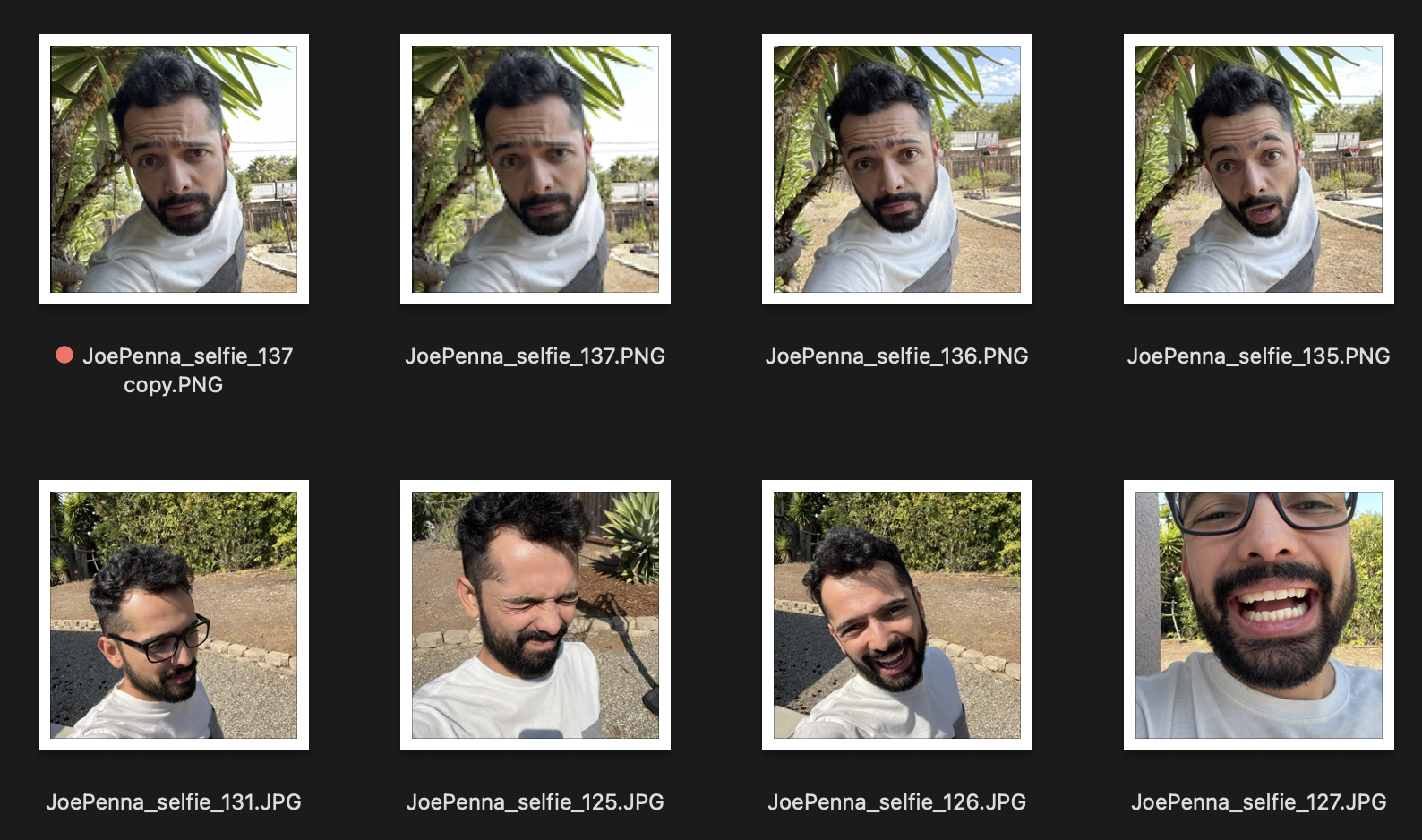
Você só vai conseguir gerações de você do lado de fora ao lado de uma árvore espetada, vestindo uma camisa branca e cinza, no estilo de ... bem, fotografia de selfie.
Em vez disso, esse conjunto de treinamento é muito melhor:
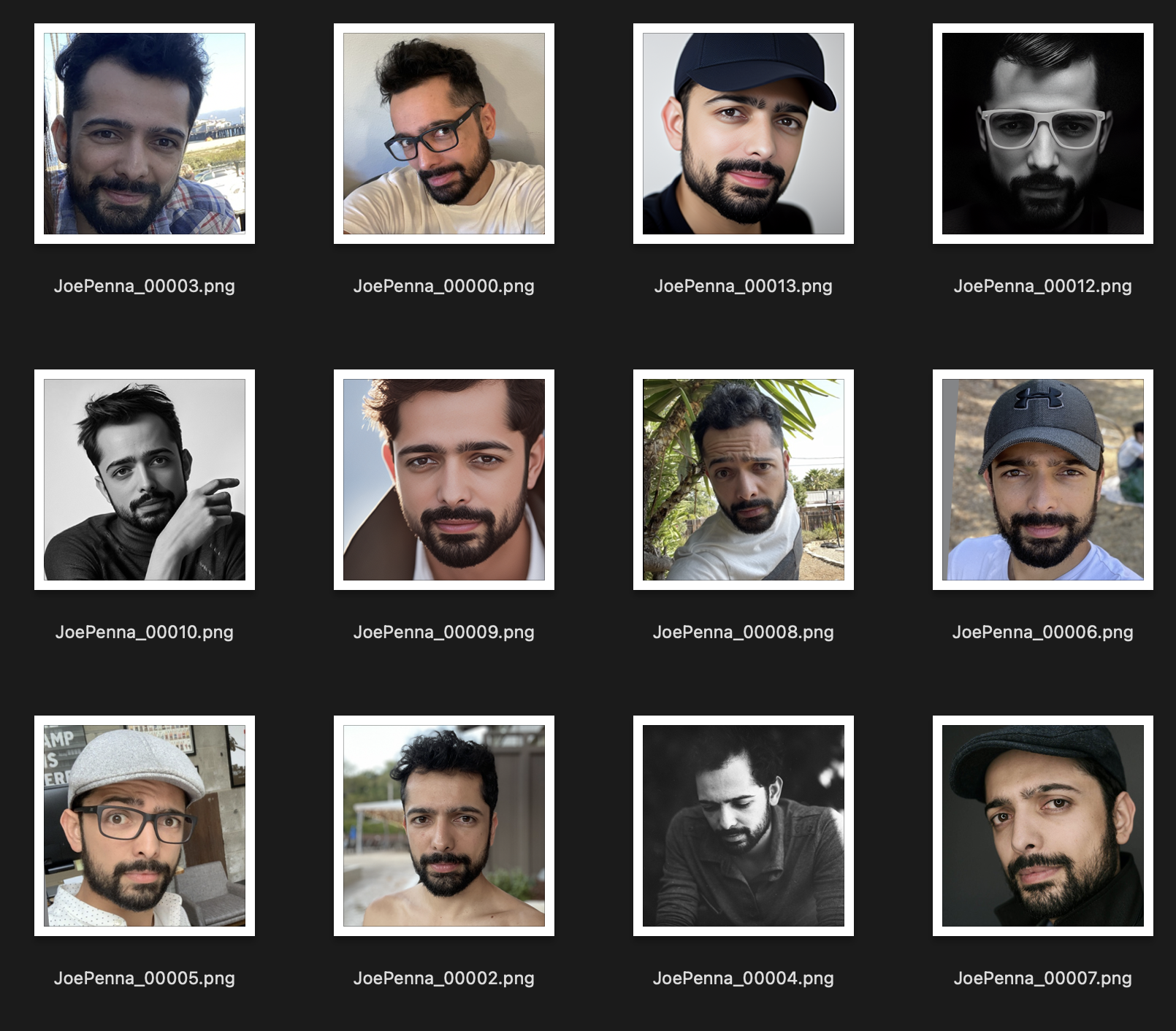
A única coisa que é consistente entre as imagens é o assunto. Portanto, estável examinará as imagens e aprenderá apenas o seu rosto, o que tornará possível "editar" em outros estilos.
Tem certeza de que está solicitando certo?
Deve ser <token> <class> , não apenas <token> . Por exemplo:
JoePenna person, portrait photograph, 85mm medium format photo
Se ainda não se parece com você, você não treinou o suficiente.
Ok, algumas razões: você pode ter treinado muito tempo ... ou suas imagens eram muito semelhantes ... ou você não treinou com imagens suficientes.
Sem problemas. Podemos consertar isso com o prompt. A difusão estável coloca muito mérito para o que você digitar primeiro. Portanto, salve para mais tarde:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
Você não treinou o suficiente ...
Sem problemas. Podemos consertar isso com o prompt:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
O Dreambooth agora é suportado em difusores Huggingface para treinamento com difusão estável.
Experimente aqui:


