Dreambooth Stable Diffusion
1.0.0
สำหรับการวิ่งบน Vast.ai
สำหรับการทำงานบน Google Colab
สำหรับการทำงานบนพีซีในพื้นที่ (Windows)
สำหรับการทำงานบนพีซีในพื้นที่ (Ubuntu)
ปรับการสอน Dreambooth ของ Corridor Digital กับ repo ของ Joepenna
การใช้คำอธิบายภาพใน Dreambooth ของ Joepenna

สวัสดี! ฉันชื่อโจเพนน่า
คุณอาจเคยเห็นวิดีโอ YouTube บางรายการของฉันภายใต้ Mysteryguitarman ตอนนี้ฉันเป็นผู้กำกับภาพยนตร์สารคดี คุณอาจเคยเห็น Arctic หรือ Stowaway
สำหรับภาพยนตร์ของฉันฉันต้องสามารถฝึกอบรมนักแสดงอุปกรณ์ประกอบฉากสถานที่และอื่น ๆ ได้ดังนั้นฉันจึงทำการเปลี่ยนแปลงมากมายกับ repo ของ @Xavierxiao เพื่อฝึกฝนใบหน้าของผู้คน
ฉันไม่สามารถเปิดตัวการทดสอบทั้งหมดสำหรับภาพยนตร์ที่ฉันกำลังทำอยู่ แต่เมื่อฉันทดสอบด้วยใบหน้าของตัวเองฉันจะปล่อยสิ่งเหล่านั้นในหน้า Twitter ของฉัน - @mysteryguitarm
การทดสอบเหล่านี้จำนวนมากได้ทำกับเพื่อนของฉัน - Niko จาก Corridordigital อาจเป็นวิธีที่คุณพบ repo นี้!
ฉันไม่ได้เป็นนักเขียน ฉันแค่ดื้อรั้นและฉันไม่กลัว googling ดังนั้นในที่สุดบางคนที่ฉลาดจริง ๆ เข้าร่วมและมีส่วนร่วม ใน repo นี้โดยเฉพาะ: @djbielejeski @gammagec @mrsaad –– แต่คนอื่น ๆ อีกมากมายในความไม่ลงรอยกันของเรา!
นี่ไม่ใช่ repo ของฉันอีกต่อไป นี่คือผู้คน-who-wanna-see-dreambooth-on-sd-working-well's repo!
ตอนนี้ถ้าคุณต้องการลองทำสิ่งนี้ ... โปรดอ่านคำเตือนด้านล่างก่อน:
ขอเคารพการทำงานอย่างหนักและความคิดสร้างสรรค์ของผู้คนที่ใช้เวลาหลายปีในการฝึกฝนทักษะของพวกเขา
เข้าสู่ด้านเทคนิค:
การใช้งานนี้ไม่ได้ใช้ความคิดของ Google อย่างเต็มที่เกี่ยวกับวิธีการรักษาพื้นที่แฝง
ดูเหมือนจะไม่มีวิธีที่ง่ายในการฝึกฝนสองวิชาติดต่อกัน คุณจะจบลงด้วยไฟล์ 11-12GB ก่อนตัดแต่ง
~2gb แนวปฏิบัติที่ดีที่สุดคือการเปลี่ยน โทเค็น เป็นชื่อคนดัง ( หมายเหตุ: โทเค็นไม่ใช่ชั้นเรียน - ดังนั้นพรอมต์ของคุณจะเป็นเช่น: Chris Evans person ) นี่คือภรรยาของฉันได้รับการฝึกฝนด้วยการตั้งค่าเดียวกันยกเว้นโทเค็น
หมายเหตุ Runpod อัพเกรดอิมเมจฐานฐานของพวกเขาเป็นระยะซึ่งสามารถนำไปสู่ repo ไม่ทำงาน ไม่มีวิดีโอ YouTube ที่ทันสมัย แต่คุณยังสามารถติดตามได้เป็นแนวทาง ทำตามวิดีโอ/บทช่วยสอน RunPod ทั่วไปโดยมีการเปลี่ยนแปลงต่อไปนี้:
จากภายในหน้าฝักของฉัน
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116ลงทะเบียนสำหรับ Runpod อย่าลังเลที่จะใช้ลิงค์อ้างอิงของฉันที่นี่เพื่อที่ฉันจะได้ไม่ต้องจ่ายเงิน (แต่คุณทำ)
หลังจากเข้าสู่ระบบแล้วเลือกค SECURE CLOUD หรือ COMMUNITY CLOUD
ตรวจสอบให้แน่ใจว่าคุณพบความเร็วระหว่าง "สูง" ดังนั้นคุณจึงไม่เสียเวลาและเงินในการดาวน์โหลดช้า
เลือกบางอย่างที่มีอย่าง น้อย 24GB VRAM เช่น RTX 3090, RTX 4090 หรือ RTX A5000
ทำตามคำแนะนำวิดีโอเหล่านี้ด้านล่าง:
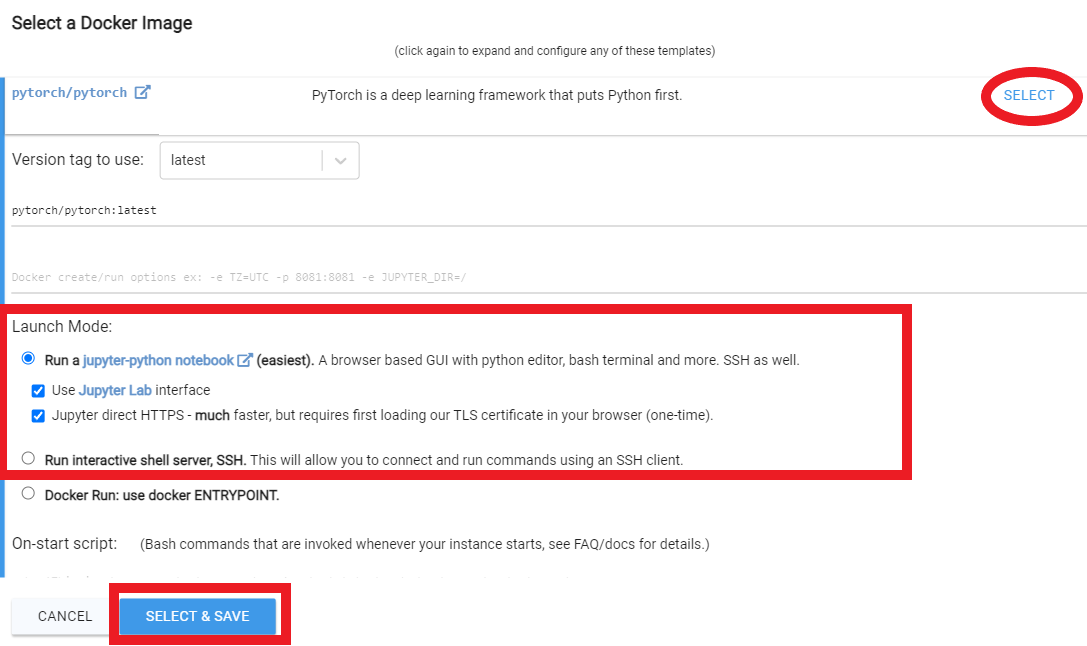
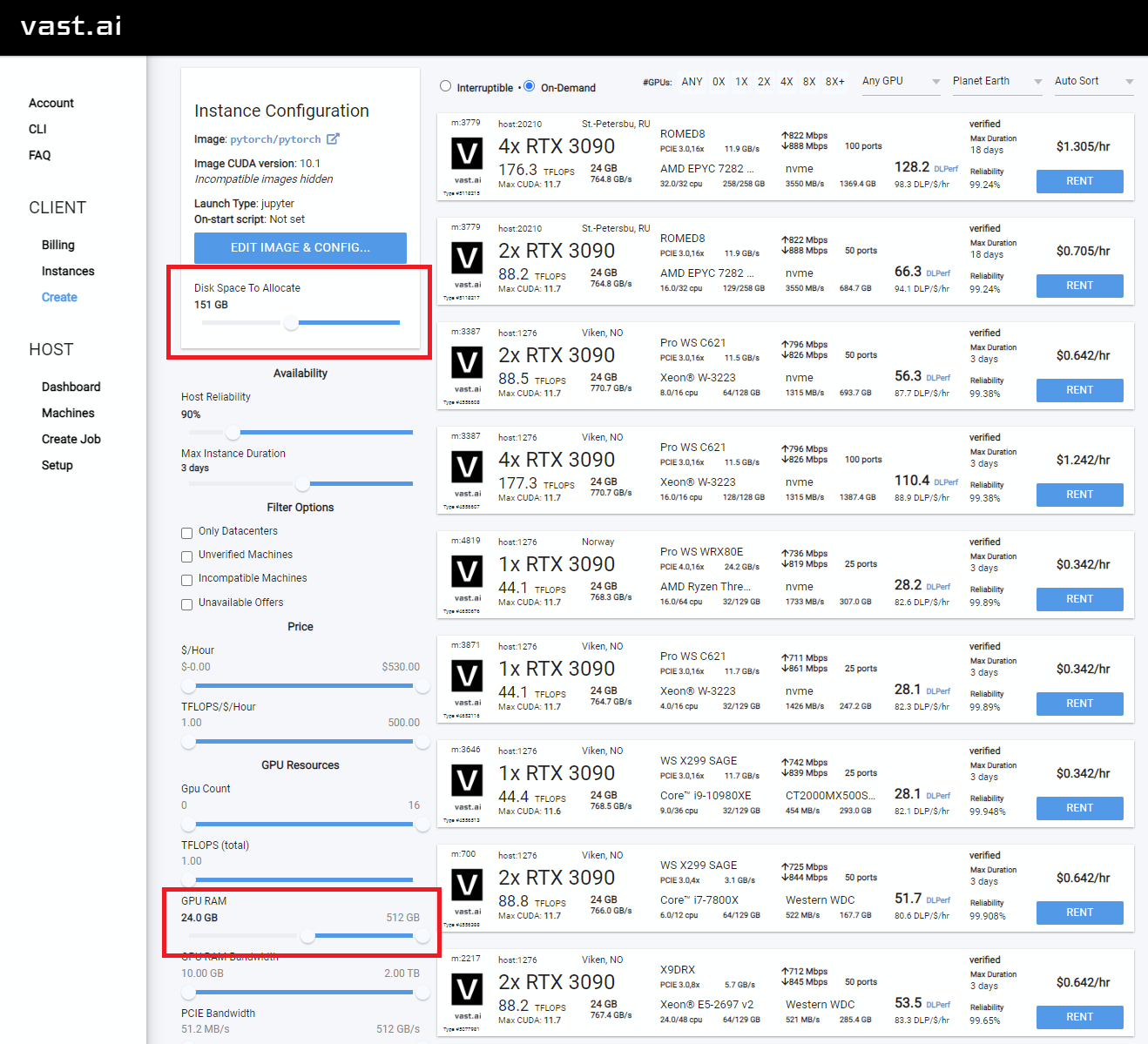
Rent จากนั้นตรงไปที่หน้าอินสแตนซ์ของคุณแล้วคลิก Open 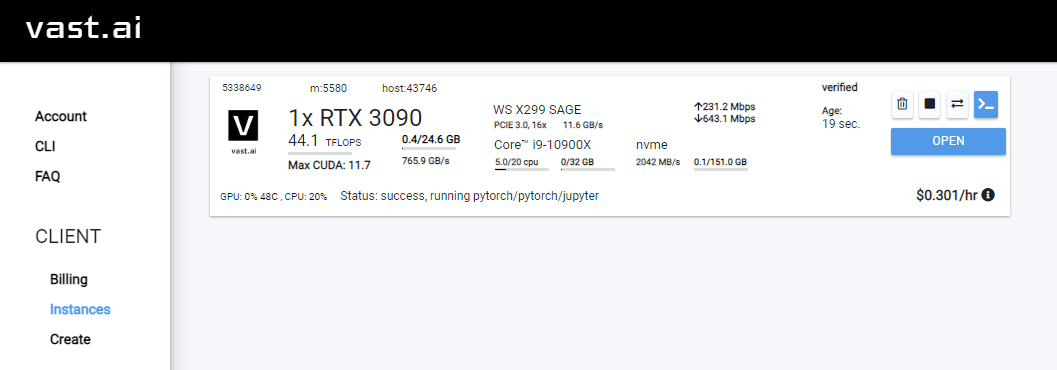
Notebook -> Python 3 (คุณสามารถทำขั้นตอนต่อไปได้หลายวิธี แต่โดยทั่วไปฉันทำสิ่งนี้) 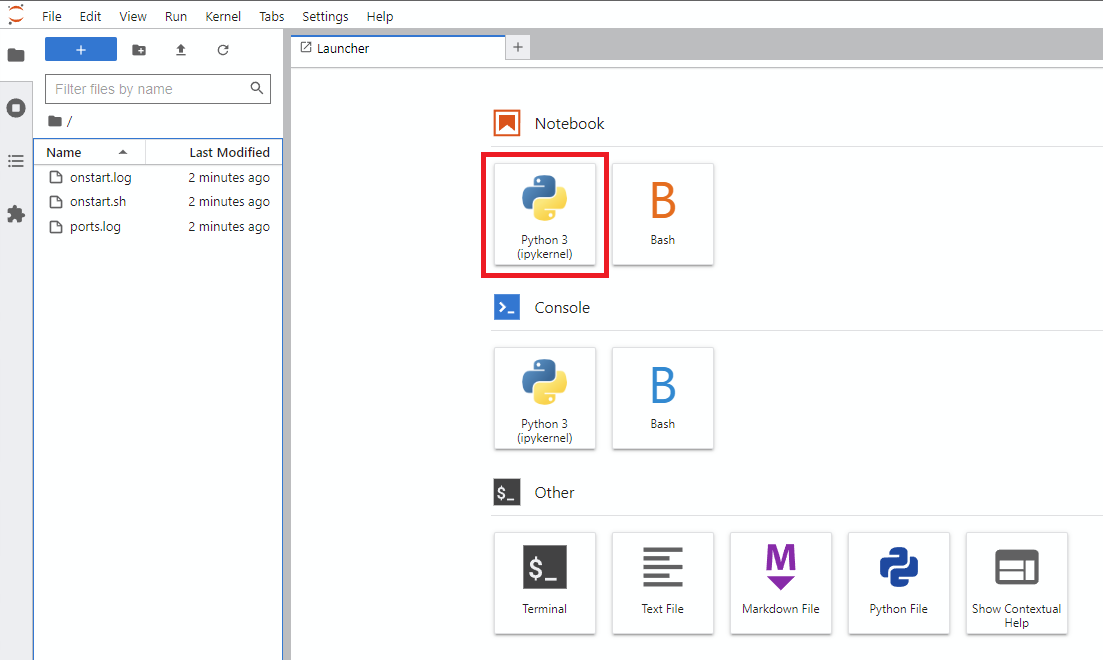
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 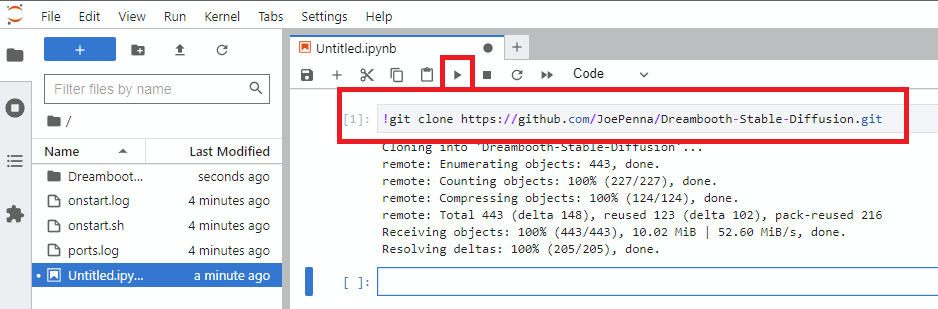
Dreambooth-Stable-Diffusion ใหม่ทางด้านซ้ายและเปิดทั้ง dreambooth_simple_joepenna.ipynb หรือ dreambooth_runpod_joepenna.ipynb 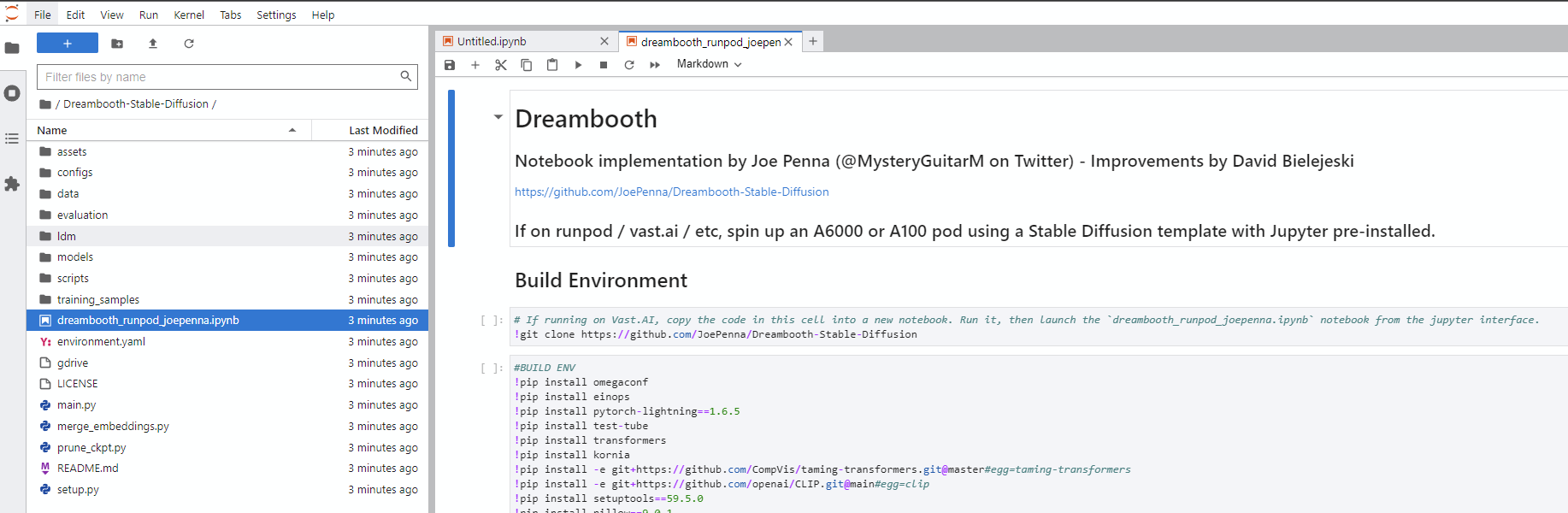
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers arguments.py
| สั่งการ | พิมพ์ | ตัวอย่าง | คำอธิบาย |
|---|---|---|---|
--config_file_path | สาย | "C:\Users\David\Dreambooth Configs\my-config.json" | พา ธ ไฟล์การกำหนดค่าที่จะใช้ |
--project_name | สาย | "My Project Name" | ชื่อโครงการ |
--debug | บูล | False | ตัวเลือก ค่าเริ่มต้นเป็น False เปิดใช้งานการบันทึกการดีบัก |
--seed | int | 23 | ตัวเลือก ค่าเริ่มต้นเป็น 23 เมล็ดพันธุ์สำหรับ seed_everything |
--max_training_steps | int | 3000 | จำนวนขั้นตอนการฝึกอบรมในการดำเนินการ |
--token | สาย | "owhx" | โทเค็นที่ไม่เหมือนใครที่คุณต้องการเป็นตัวแทนของโมเดลที่ผ่านการฝึกอบรมของคุณ |
--token_only | บูล | False | ตัวเลือก ค่าเริ่มต้นเป็น False ฝึกเฉพาะโดยใช้โทเค็นและไม่มีชั้นเรียน |
--training_model | สาย | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Path to Model to Train (model.ckpt) |
--training_images | สาย | "D:\stable-diffusion\training_images\24 Images - captioned" | เส้นทางสู่การฝึกอบรมไดเรกทอรีภาพ |
--regularization_images | สาย | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | เส้นทางสู่ไดเรกทอรีด้วยภาพการทำให้เป็นมาตรฐาน |
--class_word | สาย | "woman" | จับคู่ class_word กับหมวดหมู่ของภาพที่คุณต้องการฝึกอบรม ตัวอย่าง: man woman dog หรือ artstyle |
--flip_p | ลอย | 0.0 | ตัวเลือก ค่าเริ่มต้นเป็น 0.5 เปอร์เซ็นต์พลิก ตัวอย่าง: หากตั้งค่าเป็น 0.5 จะพลิก (กระจก) ภาพการฝึกอบรมของคุณ 50% ของเวลา สิ่งนี้จะช่วยขยายชุดข้อมูลของคุณโดยไม่จำเป็นต้องรวมภาพการฝึกอบรมเพิ่มเติม สิ่งนี้สามารถนำไปสู่ผลลัพธ์ที่แย่ลงสำหรับการฝึกอบรมใบหน้าเนื่องจากใบหน้าของคนส่วนใหญ่ไม่สมมาตรอย่างสมบูรณ์แบบ |
--learning_rate | ลอย | 1.0e-06 | ตัวเลือก ค่าเริ่มต้นเป็น 1.0e-06 (0.000001) กำหนดอัตราการเรียนรู้ ยอมรับสัญลักษณ์ทางวิทยาศาสตร์ |
--save_every_x_steps | int | 250 | ตัวเลือก ค่าเริ่มต้นเป็น 0 บันทึกจุดตรวจสอบทุกขั้นตอน ที่ 0 จะบันทึกไว้ในตอนท้ายของการฝึกอบรมเมื่อถึง max_training_steps |
--gpu | int | 0 | ตัวเลือก ค่าเริ่มต้นเป็น 0 ระบุ GPU อื่นที่ไม่ใช่ 0 เพื่อใช้สำหรับการฝึกอบรม การสนับสนุนหลาย GPU ไม่ได้ใช้งานในปัจจุบัน |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
รองรับคำบรรยายภาพ นี่คือคำแนะนำเกี่ยวกับวิธีที่เรานำไปใช้
สมมติว่าโทเค็นของคุณมีประสิทธิภาพและชั้นเรียนของคุณคือบุคคลรากข้อมูลของคุณคือ /รถไฟแล้ว:
training_images/img-001.jpg ถูกบรรยายด้วย effy person
คุณสามารถปรับแต่งคำบรรยายภาพได้โดยเพิ่มหลังจากสัญลักษณ์ @ ในชื่อไฟล์
/training_images/img-001@a photo of effy => a photo of effy
คุณสามารถใช้โทเค็นสองตัวในคำอธิบายภาพของคุณ S - Uppercase S - และ C - Uppercase C - เพื่อระบุหัวเรื่องและคลาส
/training_images/img-001@S being a good C.jpg => effy being a good person
ในการสร้างหัวเรื่องใหม่คุณเพียงแค่ต้องสร้างโฟลเดอร์สำหรับมัน ดังนั้น:
/training_images/bingo/img-001.jpg => bingo person
ชั้นเรียนยังคงเหมือนเดิม แต่ตอนนี้เรื่องเปลี่ยนไป
อีกครั้ง - ตอนนี้โทเค็นคือบิงโก:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
หนึ่งโฟลเดอร์ลึกกว่าและคุณสามารถเปลี่ยนคลาส: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
ไม่มีนักเตะมา: ลึกกว่าหนึ่งระดับและคุณสามารถคำบรรยายภาพกลุ่มของภาพ: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
รหัสส่วนใหญ่ใน repo นี้เขียนโดย Rinon Gal ET อัลผู้เขียนรายงานการวิจัยผกผันที่เป็นข้อความ แม้ว่าจะมีความคิดเล็กน้อยเกี่ยวกับภาพการทำให้เป็นมาตรฐานและการเก็บรักษาความสูญเสียก่อน (ความคิดจาก "Dreambooth") ถูกเพิ่มเข้ามาโดยไม่เคารพทั้งทีม MIT และนักวิจัยของ Google แต่ฉันกำลังเปลี่ยนชื่อนี้เป็น: "Repo เดิมชื่อ" Dreambooth ""
สำหรับการใช้งานทางเลือกโปรดดู "ตัวเลือกทางเลือก" ด้านล่าง
The ground truth (ภาพจริงข้อควรระวัง: ผู้หญิงที่สวยมาก) 
พรอมต์เดียวกันสำหรับภาพเหล่านี้ทั้งหมดด้านล่าง:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
พร้อมกับโทเค็นของคุณ เช่น "Joepenna" แทนที่จะเป็น "joepenna person"
หากคุณได้รับการฝึกฝนกับ joepenna ภายใต้ person เรียนโมเดลควรรู้ว่าใบหน้าของคุณเป็น:
joepenna person
ตัวอย่างการแจ้ง:
ไม่ถูกต้อง ( person ที่หายไปตาม joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅สิ่งนี้ถูกต้อง (รวมถึง person หลังจาก joepenna )
portrait photograph of joepenna person 35mm film vintage glass
บางครั้งคุณอาจได้รับคนที่ดูเหมือนคุณกับ Joepenna (โดยเฉพาะอย่างยิ่งถ้าคุณได้รับการฝึกฝนมามากเกินไป) แต่นั่นเป็นเพียงเพราะการทำซ้ำในปัจจุบันของ Dreambooth ทำให้โทเค็นนั้นมากเกินไปจนทำให้เกิดโทเค็นนั้น
ในขณะที่การฝึกอบรมเสถียรไม่ทราบว่าคุณเป็นคน มันจะเลียนแบบสิ่งที่เห็น
ดังนั้นหากภาพการฝึกของคุณเป็นแบบนี้:
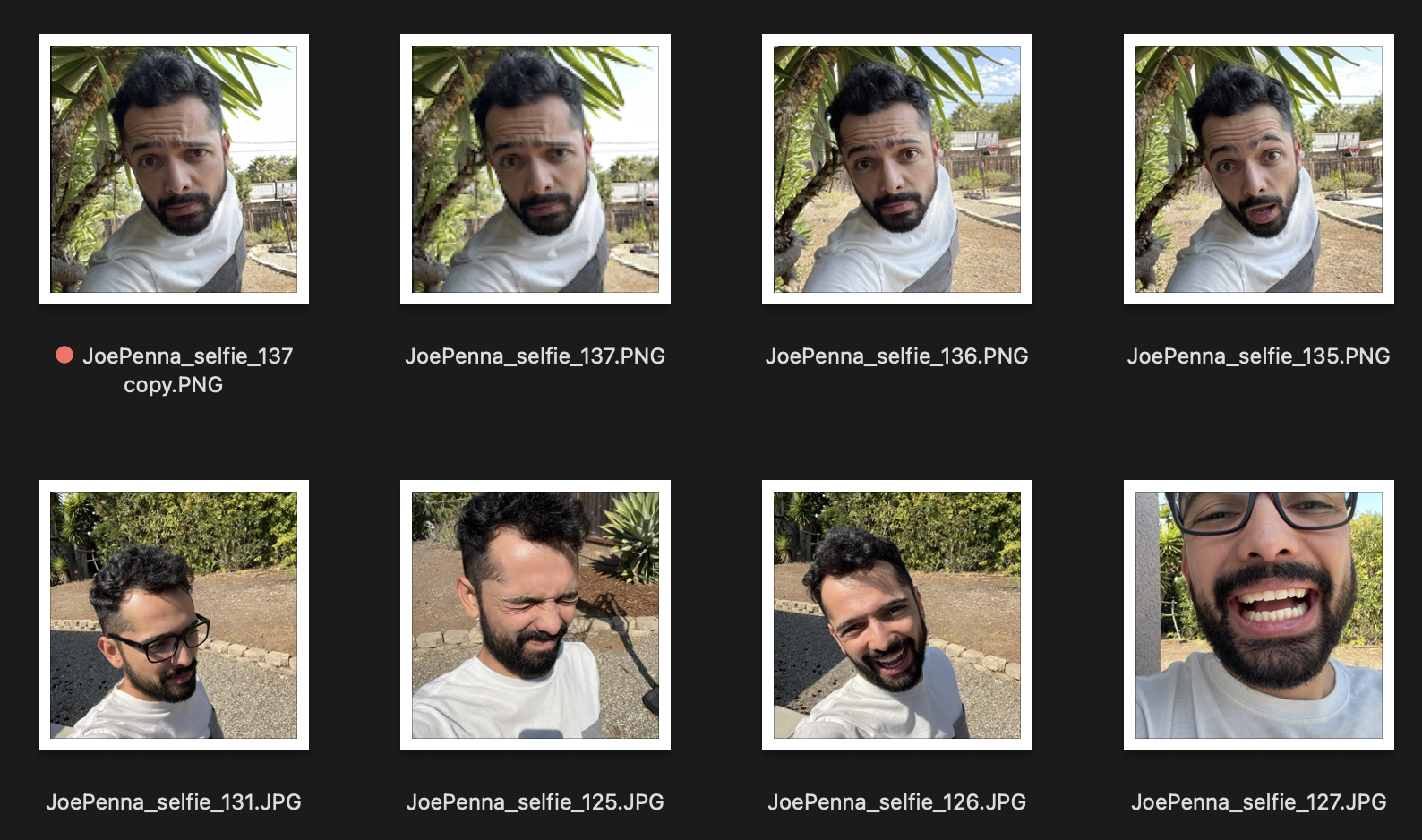
คุณจะได้รับสิ่งชั่วร้ายของคุณข้างนอกถัดจากต้นไม้แหลมคมสวมเสื้อเชิ้ตสีขาวและสีเทาในรูปแบบของ ... ถ่ายภาพเซลฟี่
ชุดการฝึกอบรมนี้ดีกว่ามาก:
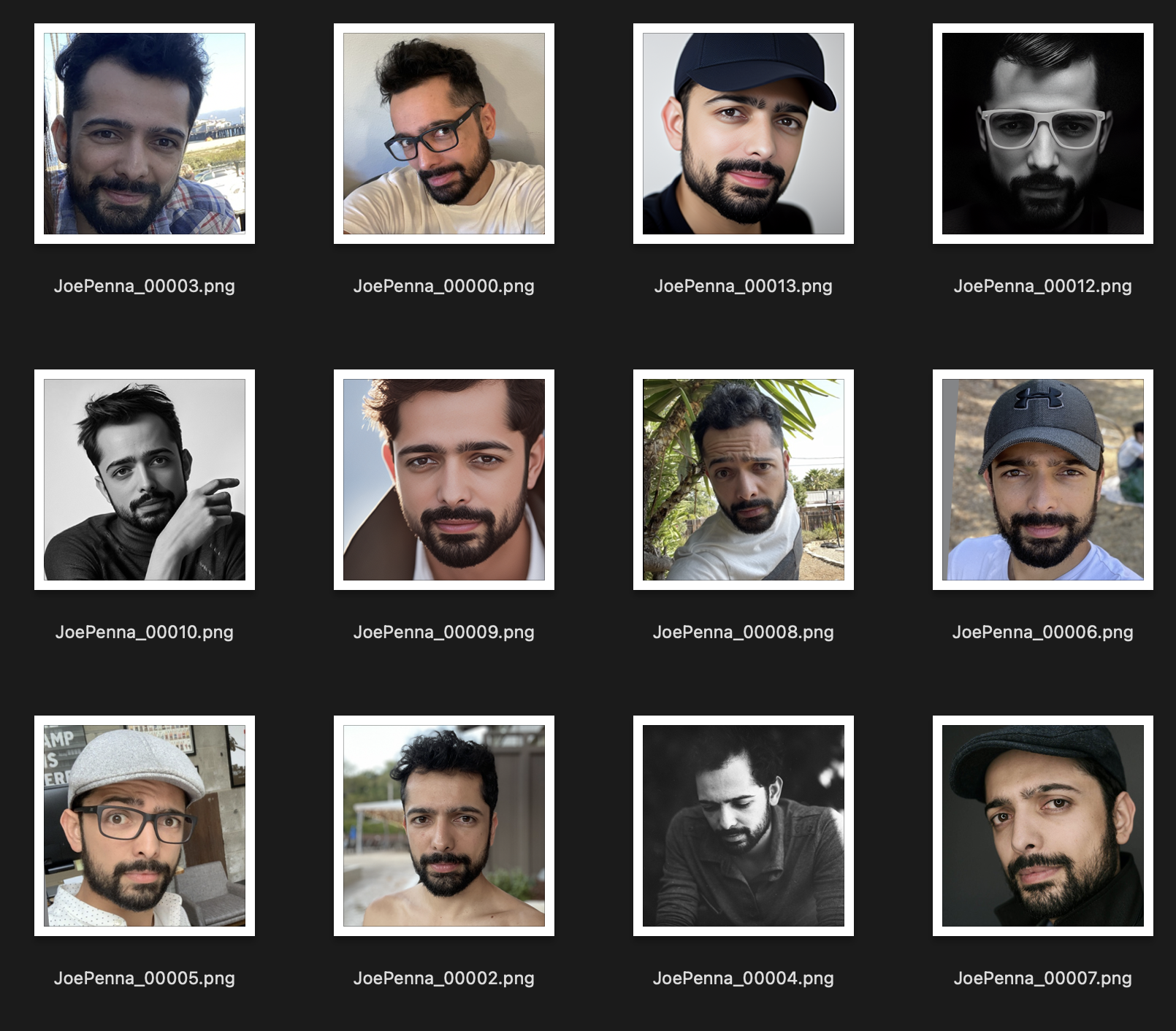
สิ่งเดียวที่สอดคล้องกันระหว่างภาพคือเรื่อง ดังนั้นความเสถียรจะมองผ่านภาพและเรียนรู้เฉพาะใบหน้าของคุณซึ่งจะทำให้ "แก้ไข" เป็นรูปแบบอื่น ๆ ที่เป็นไปได้
แน่ใจหรือว่าคุณแจ้งให้ทราบใช่ไหม?
มันควรจะเป็น <token> <class> ไม่ใช่แค่ <token> ตัวอย่างเช่น:
JoePenna person, portrait photograph, 85mm medium format photo
ถ้ามันยังดูไม่เหมือนคุณคุณก็ไม่ได้ฝึกฝนนานพอ
โอเคเหตุผลบางประการที่ว่าทำไม: คุณอาจได้รับการฝึกฝนมานานเกินไป ... หรือภาพของคุณคล้ายกันมากเกินไป ... หรือคุณไม่ได้ฝึกด้วยภาพที่เพียงพอ
ไม่มีปัญหา. เราสามารถแก้ไขได้ด้วยพรอมต์ การแพร่กระจายที่มั่นคงทำให้คุณต้องทำอะไรมากมายกับสิ่งที่คุณพิมพ์ก่อน ดังนั้นบันทึกไว้ในภายหลัง:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
คุณไม่ได้ฝึกฝนนานพอ ...
ไม่มีปัญหา. เราสามารถแก้ไขได้ด้วยพรอมต์:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
ตอนนี้ Dreambooth ได้รับการสนับสนุนใน huggingface diffusers สำหรับการฝึกอบรมด้วยการแพร่กระจายที่มั่นคง
ลองใช้ที่นี่:


