Dreambooth Stable Diffusion
1.0.0
Por correr en vasto.
Para correr en Google Colab
Para ejecutar una PC local (Windows)
Para ejecutar una PC local (Ubuntu)
Adaptando el tutorial Dreambooth de Corridor Digital al repositorio de Joepenna
Usar subtítulos en Dreambooth de Joepenna

¡Hola! Mi nombre es Joe Penna.
Es posible que hayas visto algunos videos de YouTube mía bajo Mysteryguitarman . Ahora soy director de largometrajes. Es posible que haya visto el Ártico o Stowaway.
Para mis películas, necesito poder capacitar a actores específicos, accesorios, ubicaciones, etc. Entonces, hice un montón de cambios en el repositorio de @Xavierxiao para entrenar las caras de las personas.
No puedo lanzar todas las pruebas para la película en la que estoy trabajando, pero cuando pruebo con mi propia cara, las publico en mi página de Twitter: @myteryguitarm.
Muchas de estas pruebas se realizaron con un amigo mío: Niko de Corridordigital. ¡Puede ser cómo encontraste este repositorio!
Realmente no soy un codificador. Soy terco y no tengo miedo de buscar en Google. Entonces, eventualmente, algunas personas realmente inteligentes se unieron y han estado contribuyendo. En este repositorio, específicamente: @djbielejeski @gammagec @mrsaad –– ¡pero muchos otros en nuestra discordia!
Este ya no es mi repositorio. ¡Este es el repositorio de las personas que who-wanna-see-dreambooth-on-sd-working-well!
Ahora, si quieres intentar hacer esto ... Lea las advertencias a continuación primero:
Respetemos el arduo trabajo y la creatividad de las personas que han pasado años perfeccionando sus habilidades.
En el lado técnico:
Esta implementación no implementa completamente las ideas de Google sobre cómo preservar el espacio latente.
No parece haber una manera fácil de entrenar a dos sujetos consecutivamente. Terminará con un archivo 11-12GB antes de podar.
~2gb La mejor práctica es cambiar el token a un nombre de celebridades ( nota: token, no clase , por lo que su mensaje sería algo así como: Chris Evans person ). Aquí está mi esposa entrenada con exactamente el mismo entorno, excepto por el token
Nota Runpod actualiza periódicamente su imagen base Docker que puede llevar a que el repositorio no funcione. Ninguno de los videos de YouTube está actualizado, pero aún puede seguirlos como guía. Siga los típicos videos/tutoriales de YouTube de Runpod, con los siguientes cambios:
Desde dentro de la página de mis vainas,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Regístrese en Runpod. Siéntase libre de usar mi enlace de referencia aquí, para que no tenga que pagarlo (pero usted lo hace).
Después de iniciar sesión, seleccione SECURE CLOUD o COMMUNITY CLOUD
Asegúrese de encontrar una velocidad de interento "alta" para que no esté perdiendo el tiempo y el dinero en descargas lentas
Seleccione algo con al menos 24 GB de VRAM como RTX 3090, RTX 4090 o RTX A5000
Siga estas instrucciones de video a continuación:
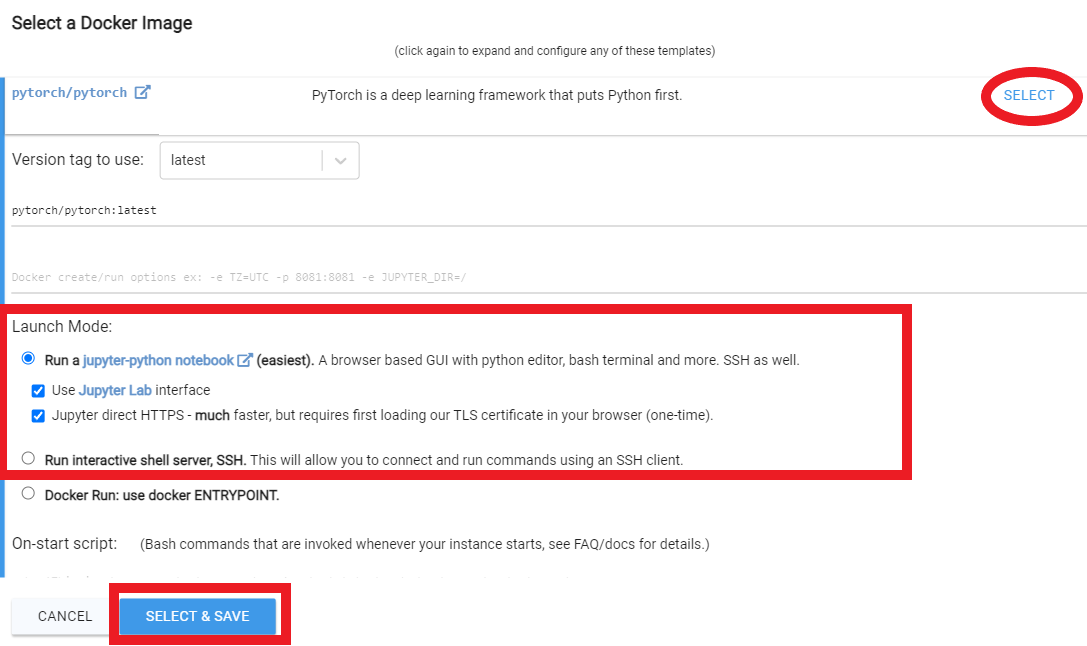
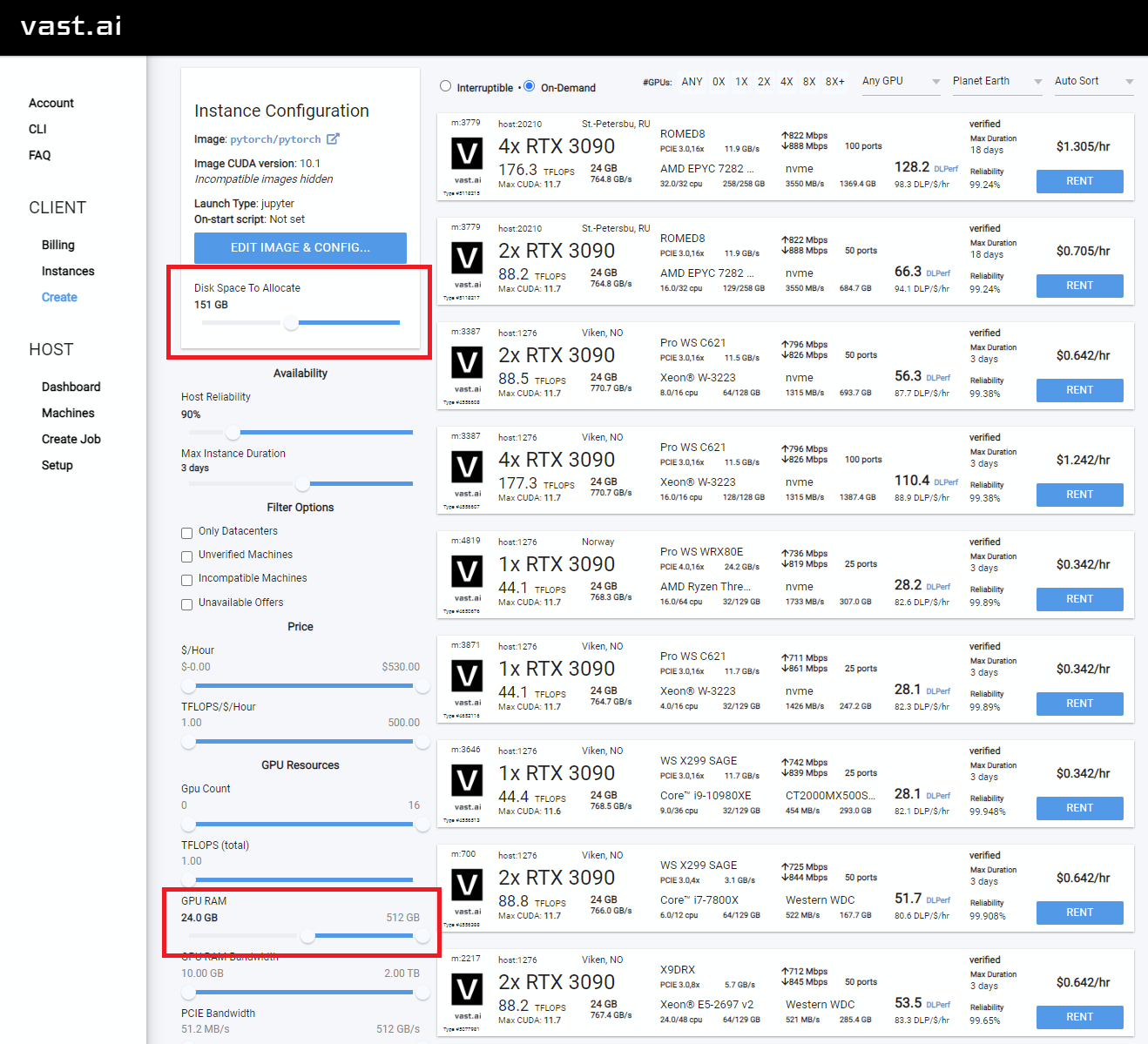
Rent , luego diríjase a su página de instancias y haga clic Open 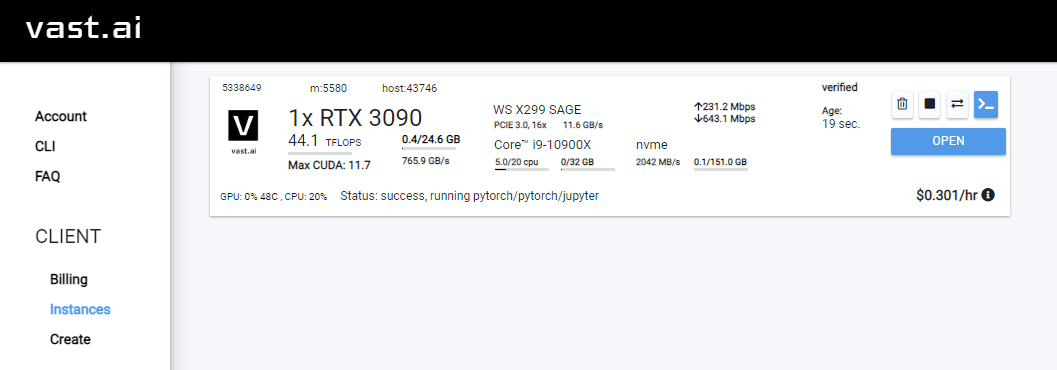
Notebook -> Python 3 (puede hacer este siguiente paso de varias maneras, pero normalmente hago esto) 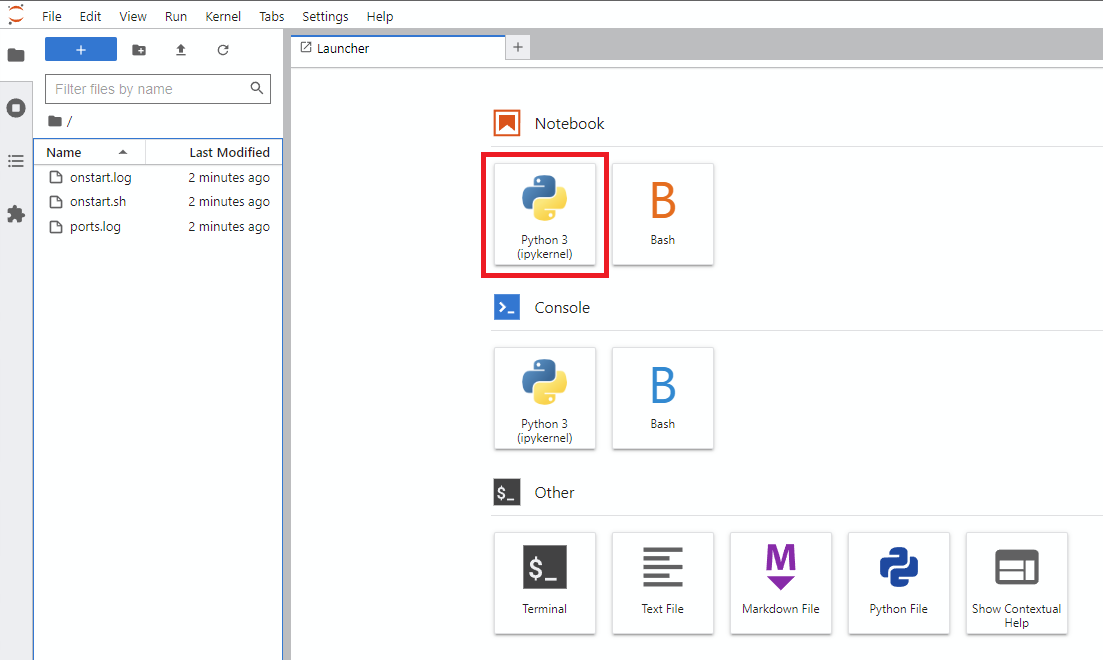
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion a la izquierda y abra el archivo dreambooth_simple_joepenna.ipynb o dreambooth_runpod_joepenna.ipynb 
cmd abiertoC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers arguments.py
| Dominio | Tipo | Ejemplo | Descripción |
|---|---|---|---|
--config_file_path | cadena | "C:\Users\David\Dreambooth Configs\my-config.json" | La ruta el archivo de configuración para usar |
--project_name | cadena | "My Project Name" | Nombre del proyecto |
--debug | bool | False | El valor predeterminado opcional a False . Habilitar el registro de depuración |
--seed | intencionalmente | 23 | Valores predeterminados opcionales a 23 . Semilla para semilla_everything |
--max_training_steps | intencionalmente | 3000 | Número de pasos de entrenamiento para funcionar |
--token | cadena | "owhx" | Token único que desea representar a su modelo capacitado. |
--token_only | bool | False | El valor predeterminado opcional a False . Entrena solo usando el token y sin clase. |
--training_model | cadena | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Ruta al modelo a entrenar (model.ckpt) |
--training_images | cadena | "D:\stable-diffusion\training_images\24 Images - captioned" | Directorio de imágenes de camino hacia el entrenamiento |
--regularization_images | cadena | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Camino hacia el directorio con imágenes de regularización |
--class_word | cadena | "woman" | Haga coincidir class_word con la categoría de imágenes que desea entrenar. Ejemplo: man , woman , dog o artstyle . |
--flip_p | flotar | 0.0 | Opcional predeterminados a 0.5 . Porcentaje de flip. Ejemplo: si se establece en 0.5 , volteará (reflejará) sus imágenes de entrenamiento el 50% del tiempo. Esto ayuda a expandir su conjunto de datos sin necesidad de incluir más imágenes de capacitación. Esto puede conducir a peores resultados para el entrenamiento facial ya que las caras de la mayoría de las personas no son perfectamente simétricas. |
--learning_rate | flotar | 1.0e-06 | El valor predeterminado opcional a 1.0e-06 (0.000001). Establezca la tasa de aprendizaje. Acepta notación científica. |
--save_every_x_steps | intencionalmente | 250 | Valores predeterminados opcionales a 0 . Guarda un punto de control cada X pasos. En 0 solo guarda al final del entrenamiento cuando se alcanza max_training_steps . |
--gpu | intencionalmente | 0 | Valores predeterminados opcionales a 0 . Especifique una GPU que no sea 0 para usar para el entrenamiento. El soporte multi-GPU no se implementa actualmente. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Se admiten subtítulos. Aquí está la guía sobre cómo los implementamos.
Digamos que su token es Effy y su clase es persona, su raíz de datos es /entrena entonces:
training_images/img-001.jpg está subtitulado con effy person
Puede personalizar el subtítulos agregándolo después de un símbolo @ en el nombre de archivo.
/training_images/img-001@a photo of effy => a photo of effy
Puede usar dos tokens en sus subtítulos S - mayúsculas S - y C - C -mayúsculas C - para indicar sujeto y clase.
/training_images/img-001@S being a good C.jpg => effy being a good person
Para crear un nuevo tema, solo necesita crear una carpeta para ello. Entonces:
/training_images/bingo/img-001.jpg => bingo person
La clase permanece igual, pero ahora el tema ha cambiado.
De nuevo, el token S ahora es bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
Una carpeta más profunda y puede cambiar la clase: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
No Come The Kicker: One Level más profundo y puede subtitular un grupo de imágenes: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
La mayoría del código en este repositorio fue escrito por Rinon Gal et. Al, los autores del documento de investigación de inversión textual. Aunque se agregaron algunas ideas sobre imágenes de regularización y preservación previa de pérdidas (ideas de "Dreambooth"), por respeto tanto al equipo del MIT como a los investigadores de Google, estoy renombrando esta bifurcación para: "El repositorio anteriormente conocido como" Dreambooth "" .
Para una implementación alternativa, consulte "Opción alternativa" a continuación.
La ground truth (imagen real, precaución: mujer muy hermosa) 
El mismo mensaje para todas estas imágenes a continuación:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Solicitando solo tu token. es decir, "Joepenna" en lugar de "Joepenna Person"
Si entrenó con joepenna bajo la person de la clase, el modelo solo debe conocer su cara como:
joepenna person
Ejemplo de indicaciones:
Incorrecto ( person desaparecida después de joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ Esto es correcto ( person está incluida después de joepenna )
portrait photograph of joepenna person 35mm film vintage glass
A veces puede obtener a alguien que se parezca a usted con Joepenna (especialmente si entrenó para demasiados pasos), pero eso es solo porque esta iteración actual de Dreambooth sobrevierte que token tanto que desanece en esa ficha.
Mientras entrenaba, Stable no sabe que eres una persona. Solo va a imitar lo que ve.
Entonces, si estas son sus imágenes de entrenamiento, se ven así:
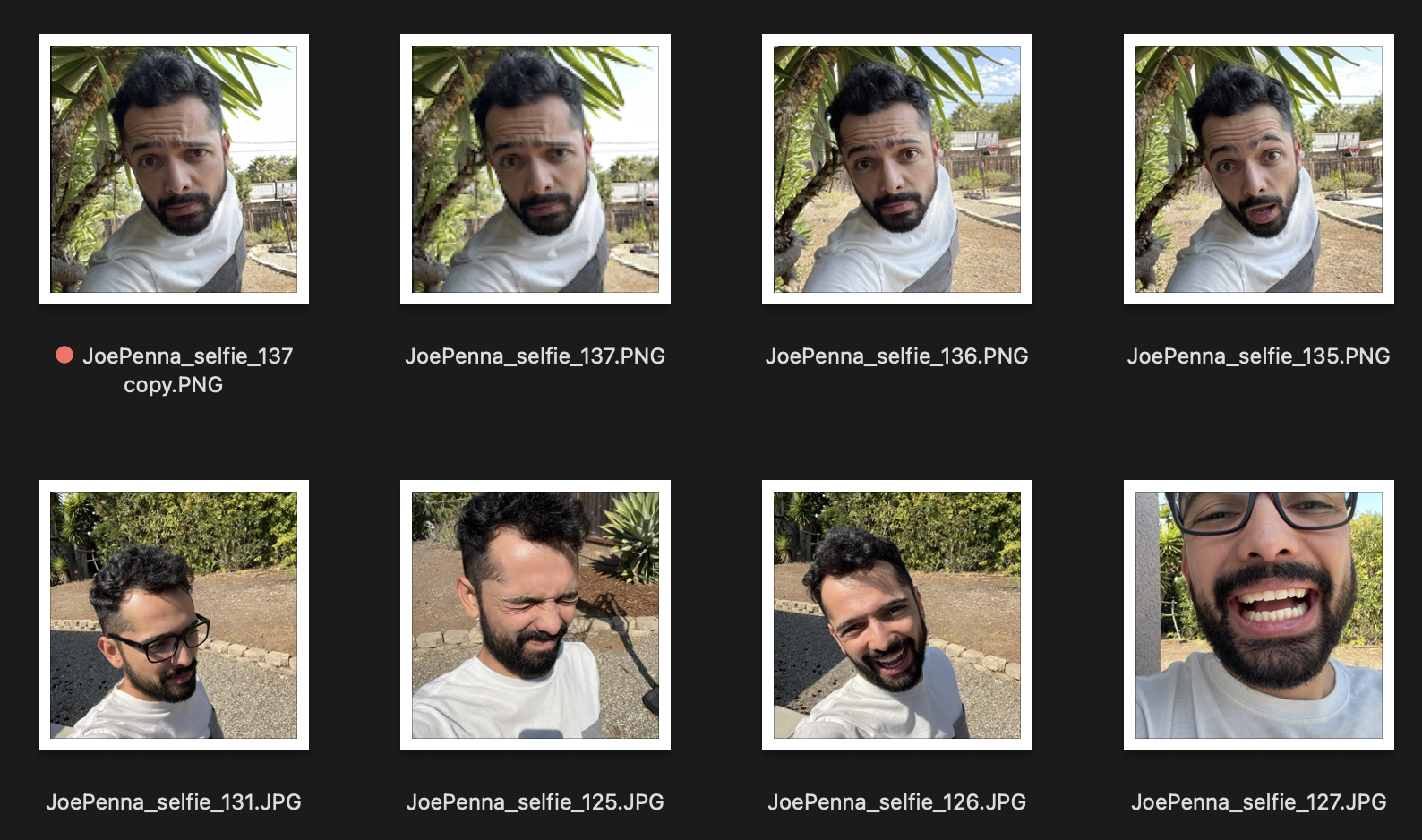
Solo obtendrás generaciones de ti afuera al lado de un árbol puntiagudo, con una camisa blanca y gris, al estilo de ... bueno, fotografía selfie.
En cambio, este conjunto de entrenamiento es mucho mejor:
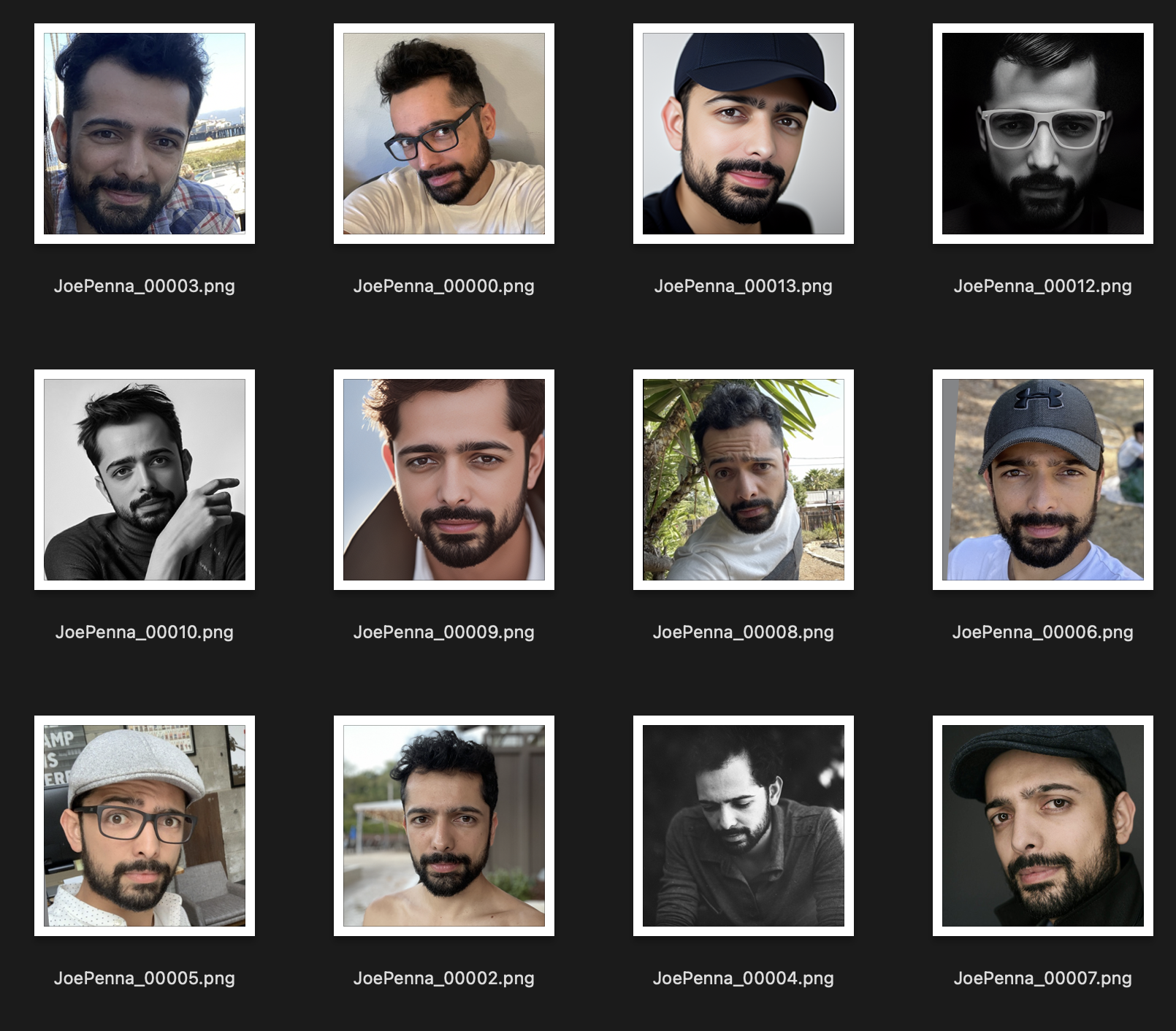
Lo único que es consistente entre las imágenes es el tema. Por lo tanto, Stable mirará a través de las imágenes y aprenderá solo su cara, lo que hará posible "editarlo" en otros estilos.
¿Estás seguro de que lo estás indicando bien?
Debe ser <token> <class> , no solo <token> . Por ejemplo:
JoePenna person, portrait photograph, 85mm medium format photo
Si todavía no se parece a usted, no entrenaste lo suficiente.
De acuerdo, algunas razones por las cuales: podrías haber entrenado demasiado tiempo ... o tus imágenes fueron demasiado similares ... o no entrenaste con suficientes imágenes.
Ningún problema. Podemos arreglar eso con el aviso. La difusión estable pone mucho mérito a lo que escriba primero. Así que guárdelo para más tarde:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
No entrenaste lo suficiente ...
Ningún problema. Podemos arreglar eso con el aviso:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
Dreambooth ahora es compatible con los difusores de Huggingface para entrenar con difusión estable.
Pruébelo aquí:


