Dreambooth Stable Diffusion
1.0.0
Untuk berjalan di luas.ai
Untuk berjalan di google colab
Untuk berjalan di PC lokal (Windows)
Untuk berjalan di PC lokal (Ubuntu)
Tutorial Dreambooth Koridor Digital untuk Repo Joepenna Digital
Menggunakan teks di DreamBooth Joepenna

Hai! Nama saya Joe Penna.
Anda mungkin telah melihat beberapa video YouTube saya di bawah Mysteryguitarman . Saya sekarang menjadi sutradara film fitur. Anda mungkin pernah melihat Arktik atau Stowaway.
Untuk film saya, saya harus dapat melatih aktor, alat peraga, lokasi, dll. Jadi, saya melakukan banyak perubahan pada repo @Xavierxiao untuk melatih wajah orang.
Saya tidak dapat merilis semua tes untuk film yang sedang saya kerjakan, tetapi ketika saya menguji dengan wajah saya sendiri, saya merilisnya di halaman Twitter saya - @mysteryguitarm.
Banyak tes ini dilakukan dengan teman saya - Niko dari Corridordigital. Mungkin bagaimana Anda menemukan repo ini!
Saya bukan seorang pembuat kode. Saya hanya keras kepala, dan saya tidak takut googling. Jadi, pada akhirnya, beberapa orang yang sangat pintar bergabung dan telah berkontribusi. Dalam repo ini, khususnya: @djbielejeski @gammagec @mrsaad –– tetapi begitu banyak orang lain di perselisihan kami!
Ini bukan lagi repo saya. Ini adalah repo orang-who-wanna-see-dreambbooth-on-sd-working-well!
Sekarang, jika Anda ingin mencoba melakukan ini ... silakan baca peringatan di bawah ini terlebih dahulu:
Mari kita hormati kerja keras dan kreativitas orang yang telah menghabiskan waktu bertahun -tahun mengasah keterampilan mereka.
Ke sisi teknis:
Implementasi ini tidak sepenuhnya menerapkan ide -ide Google tentang cara melestarikan ruang laten.
Tampaknya tidak ada cara mudah untuk melatih dua subjek secara berurutan. Anda akan berakhir dengan file 11-12GB sebelum pemangkasan.
~2gb Praktik terbaik adalah mengubah token menjadi nama selebriti ( catatan: token, bukan kelas - jadi prompt Anda akan menjadi sesuatu seperti: Chris Evans person ). Inilah istri saya yang dilatih dengan pengaturan yang sama persis, kecuali token
Catatan Runpod secara berkala meningkatkan gambar Docker dasar mereka yang dapat menyebabkan repo tidak berfungsi. Tidak ada video YouTube yang terbaru tetapi Anda masih dapat mengikutinya sebagai panduan. Ikuti video/tutorial YouTube Runpod yang khas, dengan perubahan berikut:
Dari dalam halaman polong saya,
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116Daftar untuk Runpod. Jangan ragu untuk menggunakan tautan referensi saya di sini, sehingga saya tidak perlu membayarnya (tapi Anda lakukan).
Setelah masuk, pilih SECURE CLOUD atau COMMUNITY CLOUD yang aman
Pastikan Anda menemukan kecepatan interent "tinggi" sehingga Anda tidak membuang -buang waktu dan uang untuk unduhan lambat
Pilih sesuatu dengan setidaknya 24GB VRAM seperti RTX 3090, RTX 4090 atau RTX A5000
Ikuti instruksi video ini di bawah ini:
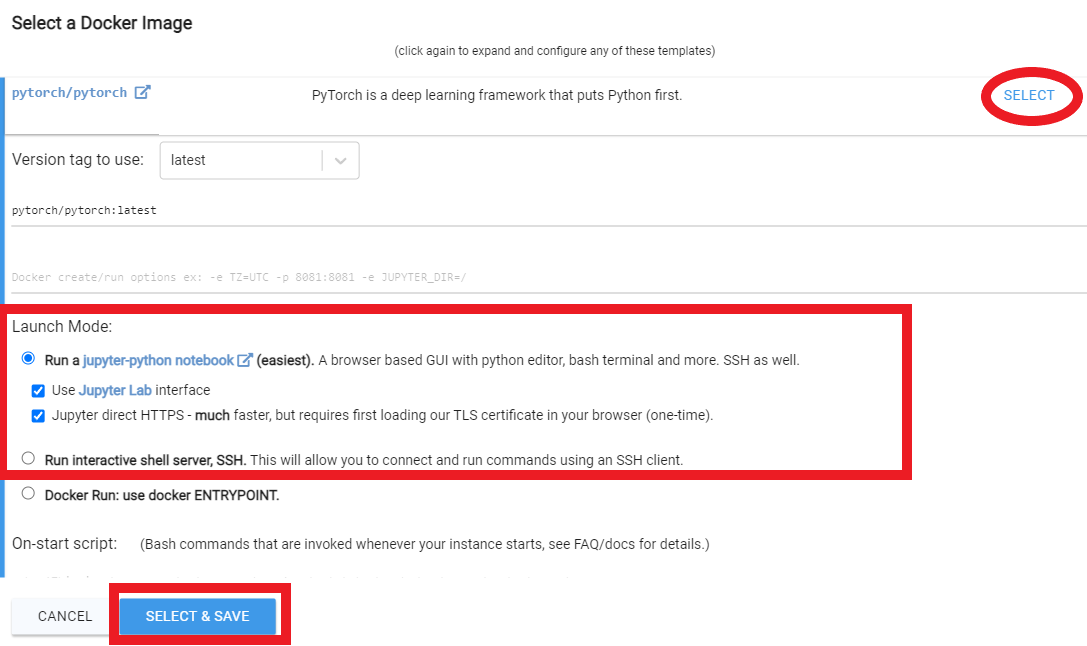
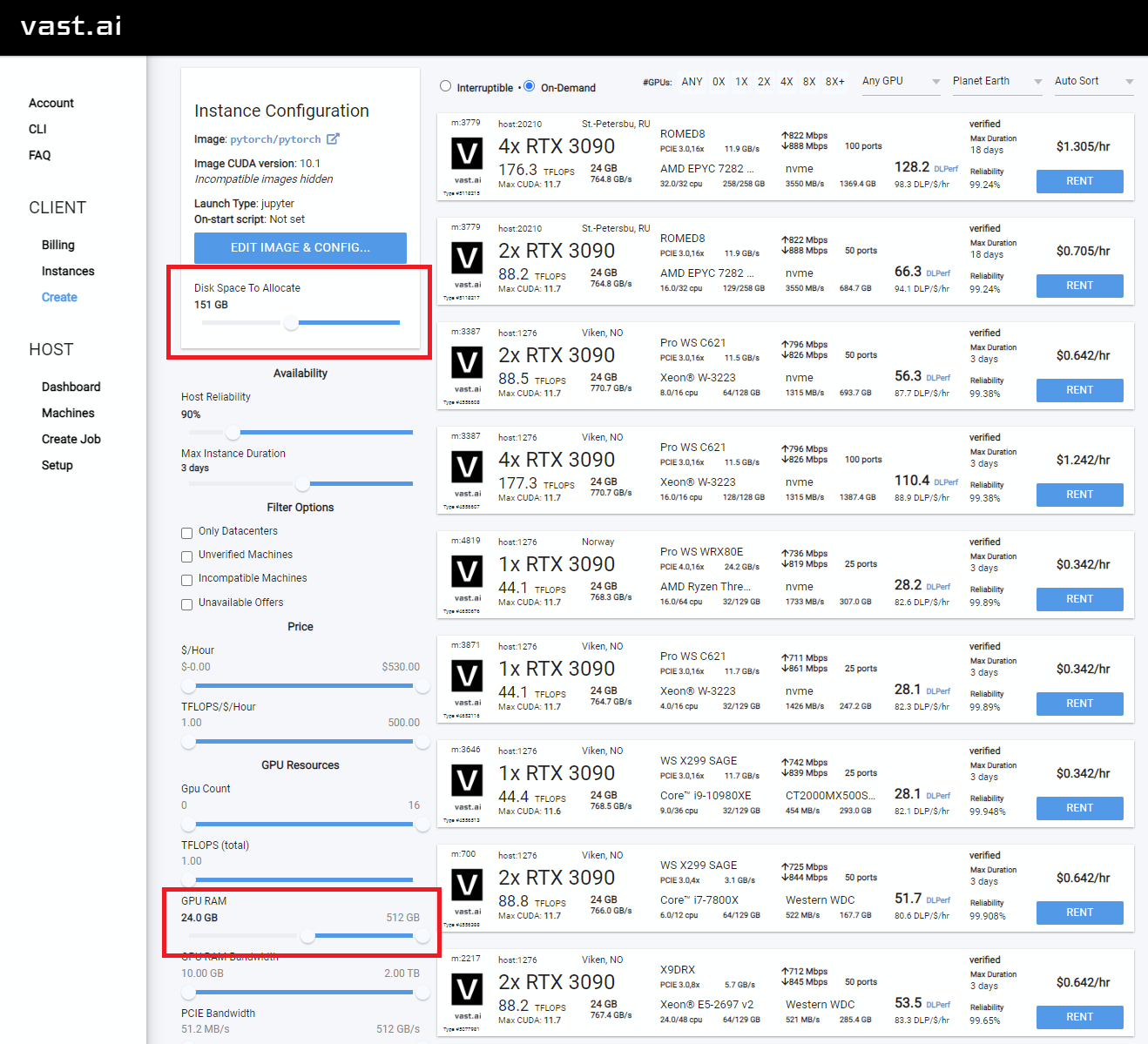
Rent , lalu pergilah ke halaman instance Anda dan klik Open 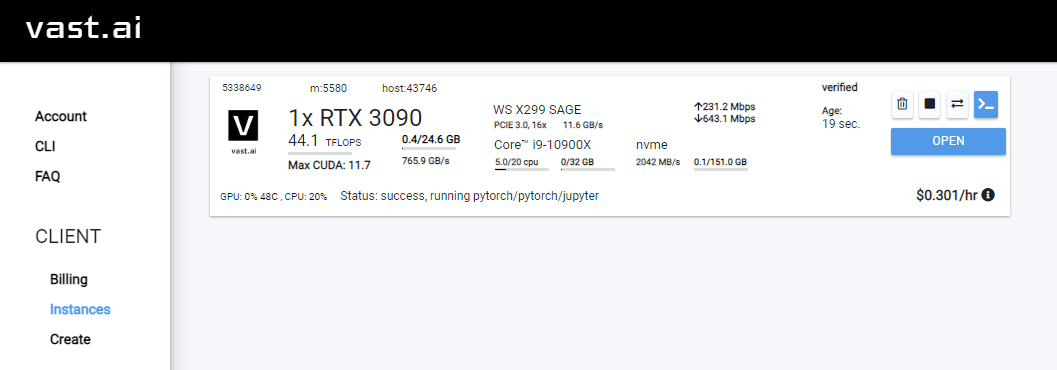
Notebook -> Python 3 (Anda dapat melakukan langkah berikutnya dengan beberapa cara, tetapi saya biasanya melakukan ini) 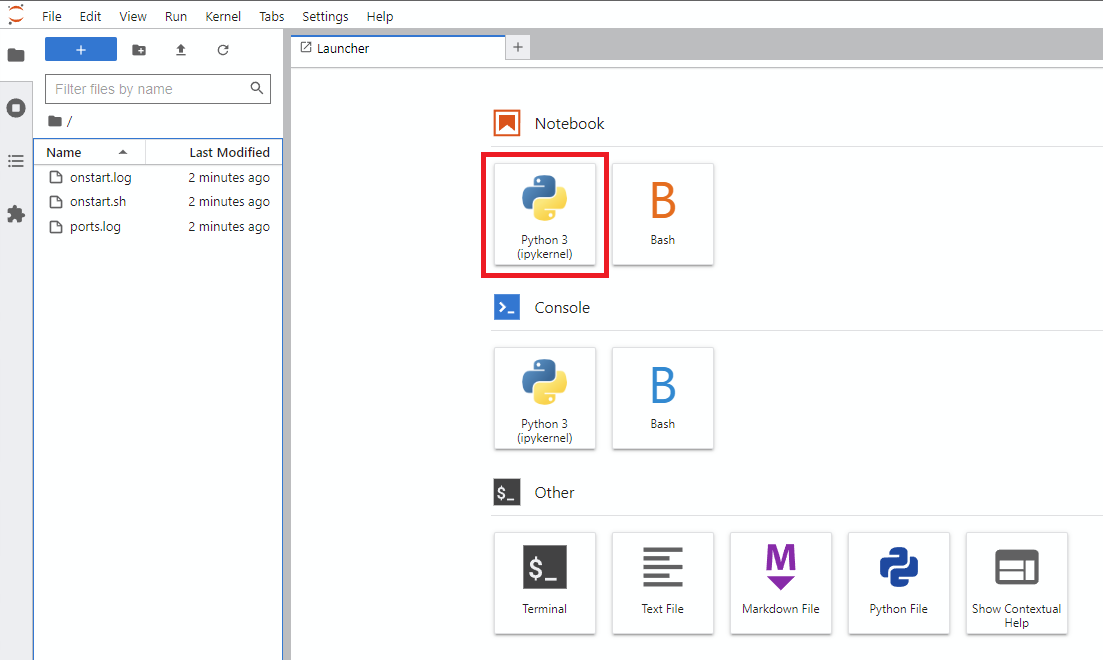
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 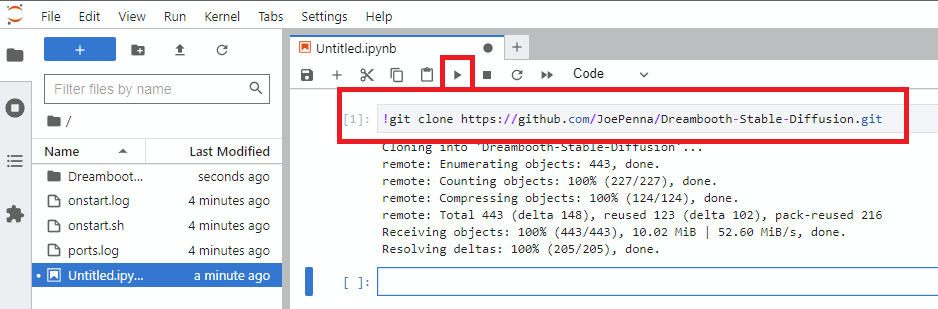
Dreambooth-Stable-Diffusion baru di sebelah kiri dan buka dreambooth_simple_joepenna.ipynb atau dreambooth_runpod_joepenna.ipynb file 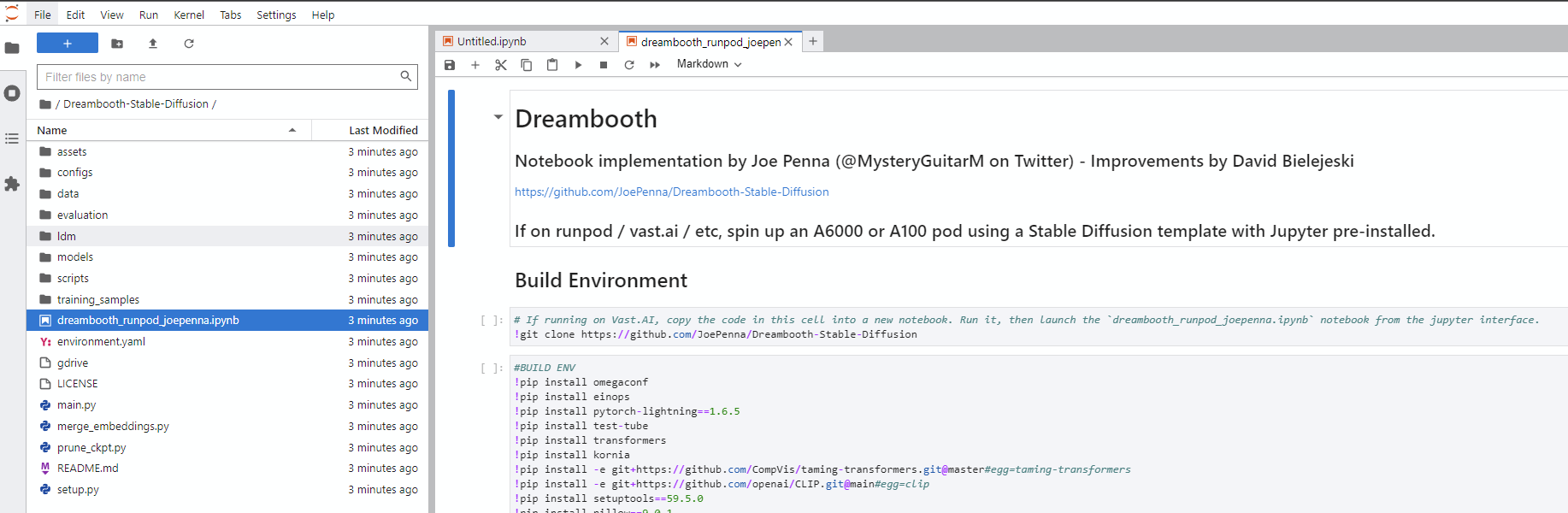
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
DreamBooth_helpers arguments.py
| Memerintah | Jenis | Contoh | Keterangan |
|---|---|---|---|
--config_file_path | rangkaian | "C:\Users\David\Dreambooth Configs\my-config.json" | Jalur file konfigurasi untuk digunakan |
--project_name | rangkaian | "My Project Name" | Nama proyek |
--debug | bool | False | Default opsional ke False . Aktifkan Debug Logging |
--seed | int | 23 | Default opsional menjadi 23 . Benih untuk seed_everything |
--max_training_steps | int | 3000 | Jumlah langkah pelatihan untuk dijalankan |
--token | rangkaian | "owhx" | Token Unik Anda ingin mewakili model terlatih Anda. |
--token_only | bool | False | Default opsional ke False . Latih hanya menggunakan token dan tidak ada kelas. |
--training_model | rangkaian | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | Jalur menuju model untuk melatih (model.ckpt) |
--training_images | rangkaian | "D:\stable-diffusion\training_images\24 Images - captioned" | Jalur ke Direktori Pelatihan Gambar |
--regularization_images | rangkaian | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | Jalur ke direktori dengan gambar regularisasi |
--class_word | rangkaian | "woman" | Cocokkan Class_word dengan kategori gambar yang ingin Anda latih. Contoh: man , woman , dog , atau artstyle . |
--flip_p | mengambang | 0.0 | Default opsional menjadi 0.5 . Persentase flip. Contoh: Jika diatur ke 0.5 , akan membalik (cermin) gambar pelatihan Anda 50% dari waktu. Ini membantu memperluas dataset Anda tanpa perlu memasukkan lebih banyak gambar pelatihan. Ini dapat menyebabkan hasil yang lebih buruk untuk pelatihan wajah karena wajah kebanyakan orang tidak simetris sempurna. |
--learning_rate | mengambang | 1.0e-06 | Default opsional ke 1.0e-06 (0,000001). Tetapkan tingkat pembelajaran. Menerima notasi ilmiah. |
--save_every_x_steps | int | 250 | Default opsional ke 0 . Menyimpan pos pemeriksaan setiap langkah x. Di 0 hanya menghemat di akhir pelatihan ketika max_training_steps tercapai. |
--gpu | int | 0 | Default opsional ke 0 . Tentukan GPU selain 0 untuk digunakan untuk pelatihan. Dukungan multi-GPU saat ini tidak diterapkan. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
Keterangan didukung. Berikut adalah panduan tentang bagaimana kami menerapkannya.
Katakanlah token Anda sangat penting dan kelas Anda adalah orang, root data Anda adalah /kereta lalu:
training_images/img-001.jpg ditulis dengan effy person
Anda dapat menyesuaikan teks dengan menambahkannya setelah simbol @ di nama file.
/training_images/img-001@a photo of effy => a photo of effy
Anda dapat menggunakan dua token dalam keterangan Anda - huruf besar S - dan C - Huruf C - untuk menunjukkan subjek dan kelas.
/training_images/img-001@S being a good C.jpg => effy being a good person
Untuk membuat subjek baru, Anda hanya perlu membuat folder untuk itu. Jadi:
/training_images/bingo/img-001.jpg => bingo person
Kelas tetap sama, tetapi sekarang subjek telah berubah.
Sekali lagi - token S sekarang adalah bingo:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
Satu folder lebih dalam dan Anda dapat mengubah kelas: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
No Come The Kicker: Satu tingkat lebih dalam dan Anda dapat menulis grup gambar: /training_images/effy/person/a picture of/img-001.jpg => a picture of effy person
Mayoritas kode dalam repo ini ditulis oleh Rinon Gal et. Al, penulis makalah penelitian inversi tekstual. Meskipun beberapa ide tentang gambar regularisasi dan pelestarian kerugian sebelumnya (ide -ide dari "Dreambooth") ditambahkan, karena menghormati tim MIT dan peneliti Google, saya mengubah nama garpu ini menjadi: "Repo yang sebelumnya dikenal sebagai" DreamBooth "" .
Untuk implementasi alternatif, silakan lihat "Opsi Alternatif" di bawah ini.
The ground truth (gambar nyata, hati -hati: wanita yang sangat cantik) 
Prompt yang sama untuk semua gambar di bawah ini:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
Meminta hanya dengan token Anda. yaitu "joepenna" bukan "orang joepenna"
Jika Anda dilatih dengan joepenna di bawah kelas person , model seharusnya hanya mengetahui wajah Anda sebagai:
joepenna person
Contoh permintaan:
Salah ( person hilang mengikuti joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ Ini benar ( person termasuk setelah joepenna )
portrait photograph of joepenna person 35mm film vintage glass
Anda mungkin kadang -kadang mendapatkan seseorang yang agak terlihat seperti Anda dengan Joepenna (terutama jika Anda dilatih untuk terlalu banyak langkah), tetapi itu hanya karena iterasi Dreambooth saat ini berlebihan yang begitu banyak token sehingga berdarah ke dalam token itu.
Saat berlatih, stabil tidak tahu bahwa Anda adalah seseorang. Itu hanya akan meniru apa yang dilihatnya.
Jadi, jika ini adalah gambar pelatihan Anda terlihat seperti ini:
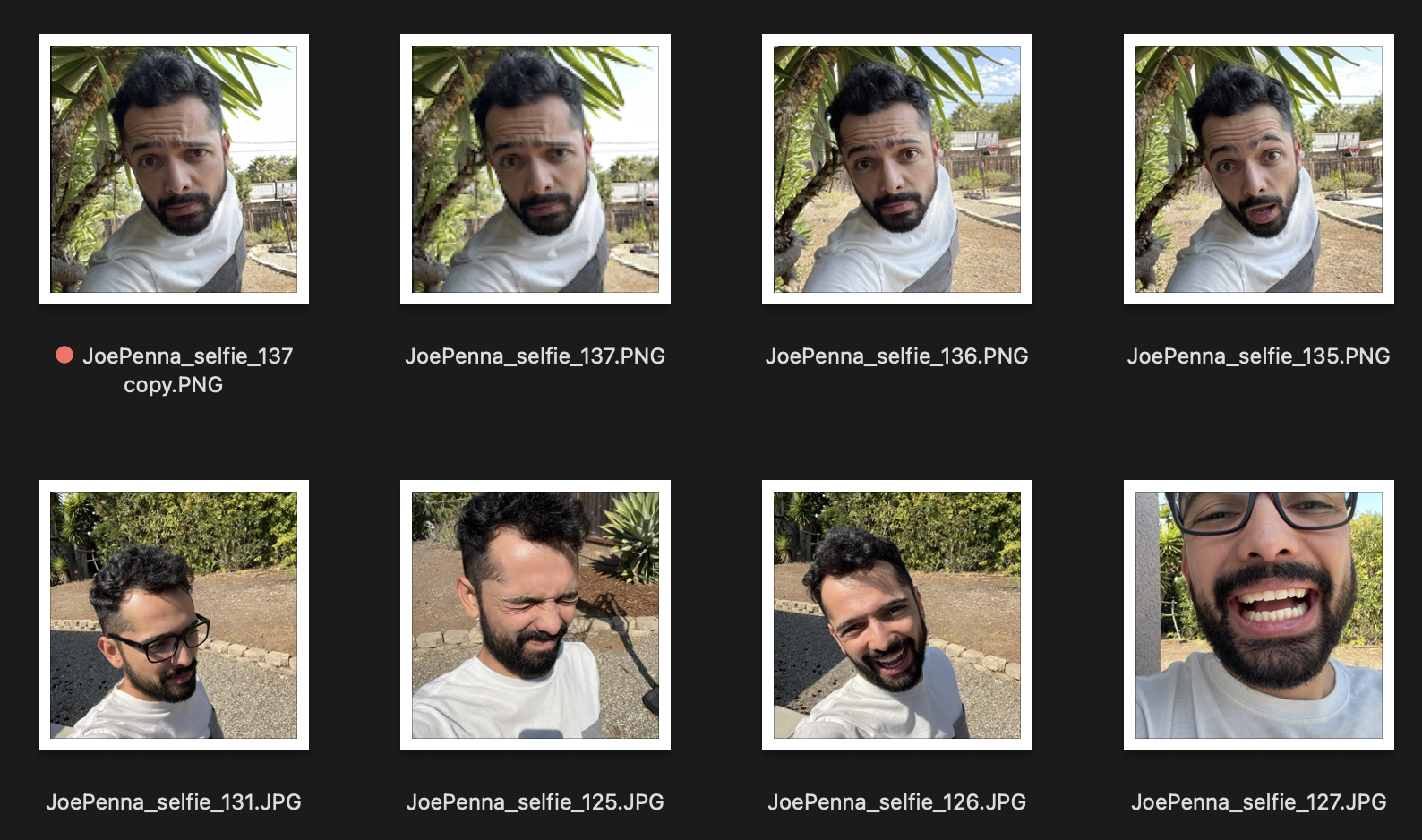
Anda hanya akan mendapatkan generasi dari Anda di luar di sebelah pohon runcing, mengenakan kemeja putih dan abu-abu, dengan gaya ... yah, foto selfie.
Sebaliknya, set pelatihan ini jauh lebih baik:
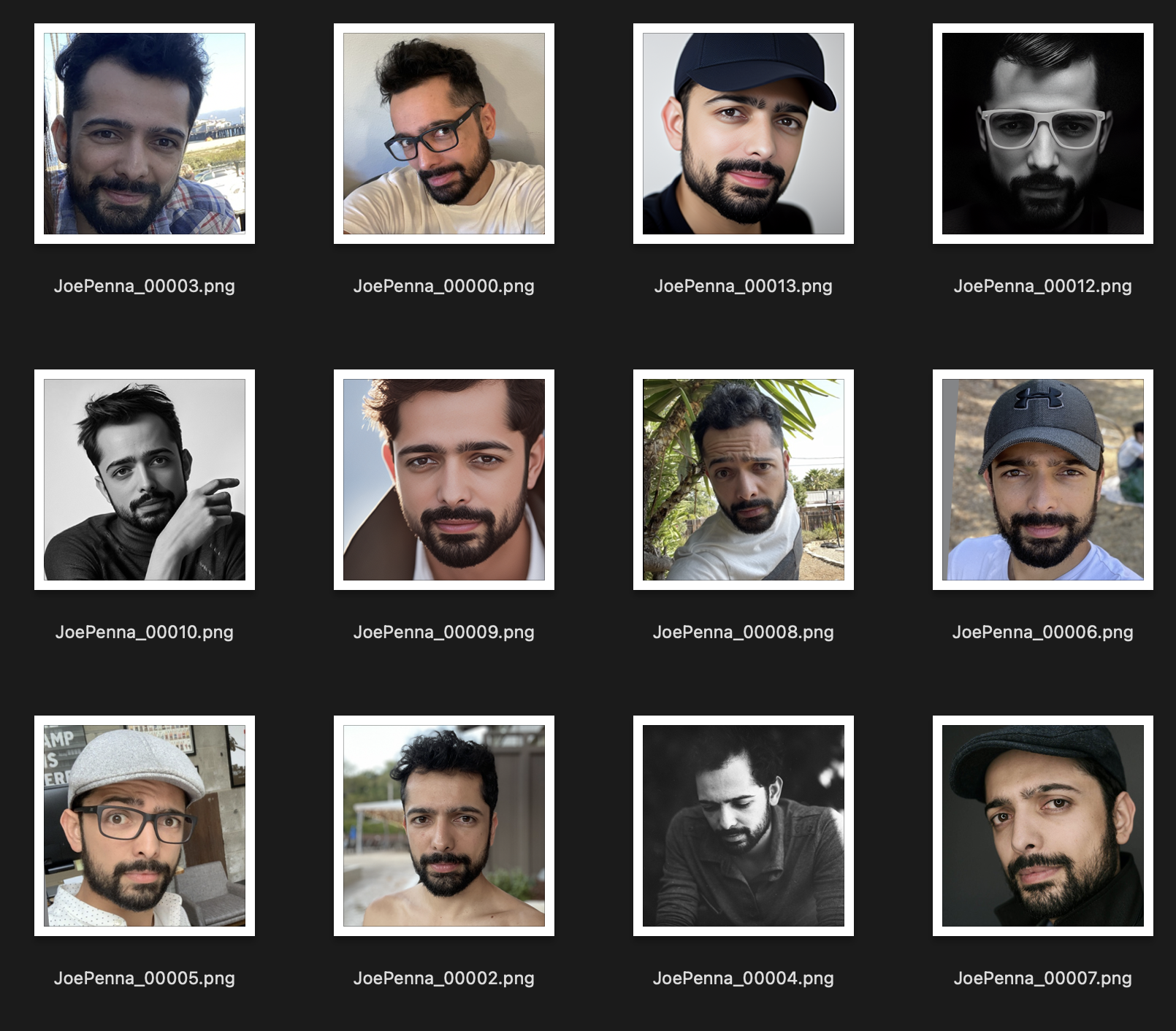
Satu -satunya hal yang konsisten antara gambar adalah subjek. Jadi, stabil akan melihat melalui gambar dan hanya mempelajari wajah Anda, yang akan membuat "mengedit" menjadi gaya lain.
Apakah Anda yakin Anda memicu itu dengan benar?
Itu harus <token> <class> , bukan hanya <token> . Misalnya:
JoePenna person, portrait photograph, 85mm medium format photo
Jika masih tidak terlihat seperti Anda, Anda tidak berlatih cukup lama.
Oke, beberapa alasan mengapa: Anda mungkin sudah berlatih terlalu lama ... atau gambar Anda terlalu mirip ... atau Anda tidak berlatih dengan cukup gambar.
Tidak masalah. Kami dapat memperbaikinya dengan prompt. Difusi yang stabil memberi banyak manfaat pada apa pun yang Anda ketik terlebih dahulu. Jadi simpan untuk nanti:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
Anda tidak berlatih cukup lama ...
Tidak masalah. Kami dapat memperbaikinya dengan prompt:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
Dreambooth sekarang didukung dalam diffuser Huggingface untuk pelatihan dengan difusi yang stabil.
Cobalah di sini:


