Dreambooth Stable Diffusion
1.0.0
للركض على Vast.ai
لتشغيله على Google Colab
لتشغيله على جهاز كمبيوتر محلي (Windows)
لتشغيله على جهاز كمبيوتر محلي (Ubuntu)
تكييف برنامج Dreambooth الخاص بـ Corridor Digital مع ريبو Joepenna's
باستخدام التسميات التوضيحية في Dreambooth Joepenna

أهلاً! اسمي جو بينا.
ربما تكون قد شاهدت بعض مقاطع فيديو YouTube الخاصة بي تحت Mysteryguitarman . أنا الآن مخرج فيلم روائي. ربما تكون قد رأيت القطب الشمالي أو المتجول.
بالنسبة لأفلامي ، أحتاج إلى أن أكون قادرًا على تدريب ممثلين محددين ، أو الدعائم ، والمواقع ، وما إلى ذلك ، لقد قمت بمجموعة من التغييرات على @Xavierxiao's Repo من أجل تدريب وجوه الناس.
لا يمكنني إصدار جميع الاختبارات الخاصة بالفيلم الذي أعمل عليه ، لكن عندما أختبر وجهي ، أقوم بإصدار تلك الموجودة على صفحة Twitter الخاصة بي - mystteryguitarm.
تم إجراء الكثير من هذه الاختبارات مع صديق لي - Niko من Tairdordigital. قد يكون كيف وجدت هذا الريبو!
أنا لست مؤلفًا حقًا. أنا عنيد فقط ، وأنا لا أخاف من googling. لذلك ، في النهاية ، انضم بعض الأشخاص الأذكياء حقًا وهم يساهمون. في هذا الريبو ، على وجه التحديد: @djbilejeskigammagec mrsaad –– لكن الكثير من الآخرين في خلافنا!
لم يعد هذا الريبو الخاص بي. هذا هو الأشخاص الذين يعملون في Who-Wanna-Wanna-dreambooth-on-sd-work-well!
الآن ، إذا كنت تريد أن تحاول القيام بذلك ... يرجى قراءة التحذيرات أدناه أولاً:
دعونا نحترم العمل الجاد والإبداع للأشخاص الذين أمضوا سنوات في شحذ مهاراتهم.
على الجانب الفني:
لا ينفذ هذا التنفيذ بشكل كامل أفكار Google حول كيفية الحفاظ على المساحة الكامنة.
لا يبدو أن هناك طريقة سهلة لتدريب موضوعين على التوالي. سوف ينتهي بك المطاف بملف 11-12GB قبل التقليم.
~2gb أفضل الممارسات هي تغيير الرمز المميز إلى اسم المشاهير ( ملاحظة: الرمز المميز ، وليس الفصل - لذلك ستكون موجهتك مثل: Chris Evans person ). ها هي زوجتي تدرب على نفس الإعدادات بالضبط ، باستثناء الرمز المميز
لاحظ Runpod بشكل دوري ، يقوم بترقية صورة Docker الأساسية التي يمكن أن تؤدي إلى عدم عمل الريبو. لا توجد مقاطع فيديو على YouTube محدثة ولكن لا يزال بإمكانك متابعتها كدليل. اتبع على طول مقاطع فيديو/دروس في Runpod YouTube النموذجية ، مع التغييرات التالية:
من داخل صفحة القرون الخاصة بي ،
runpod/pytorch:3.10-2.0.1-120-develrunpod/pytorch:3.10-2.0.1-118-runtimerunpod/pytorch:3.10-2.0.0-117runpod/pytorch:3.10-1.13.1-116اشترك في Runpod. لا تتردد في استخدام رابط الإحالة الخاص بي هنا ، بحيث لا يتعين علي دفع ثمنه (لكنك تفعل).
بعد تسجيل الدخول ، حدد إما SECURE CLOUD أو COMMUNITY CLOUD
تأكد من العثور على سرعة متداخلة "عالية" حتى لا تضيع الوقت والمال على التنزيلات البطيئة
حدد شيئًا مع ما لا يقل عن 24 جيجابايت VRAM مثل RTX 3090 أو RTX 4090 أو RTX A5000
اتبع تعليمات الفيديو هذه أدناه:
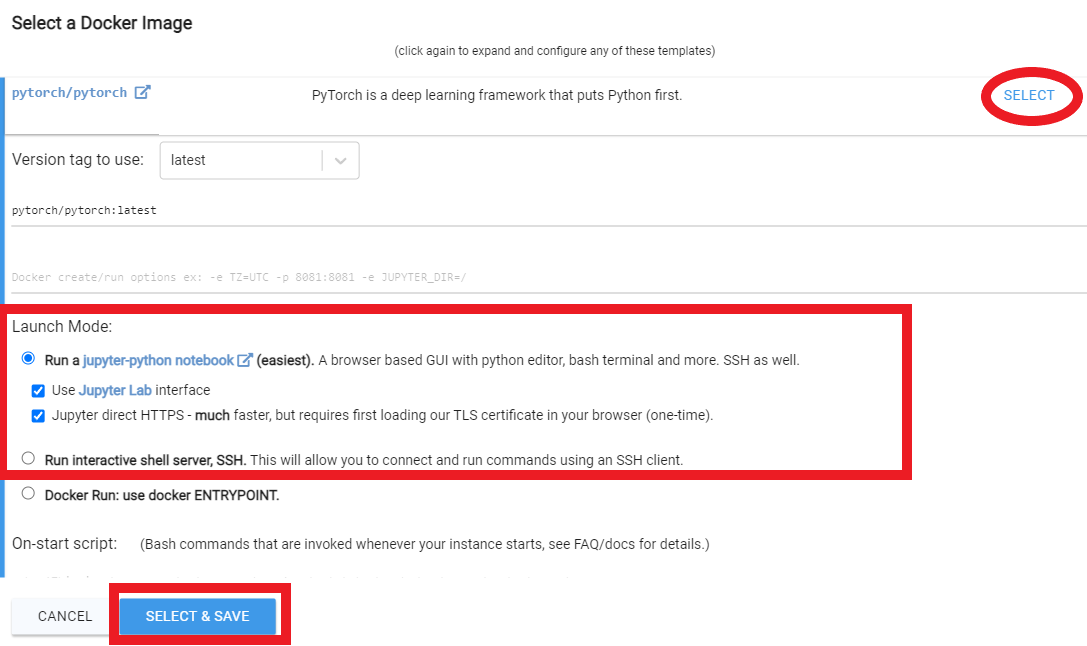
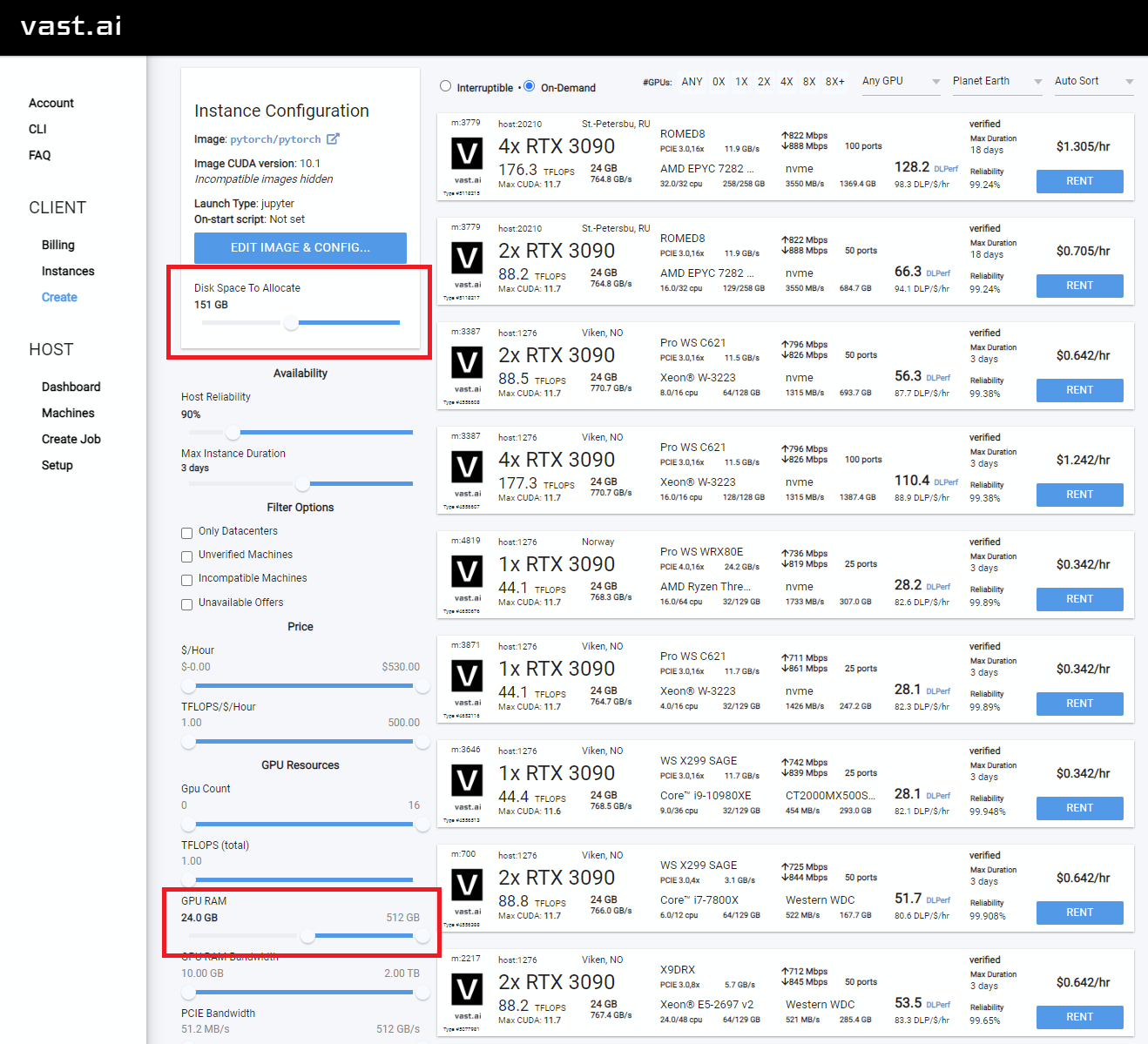
Rent ، ثم توجه إلى صفحة الحالات الخاصة بك وانقر فوق Open 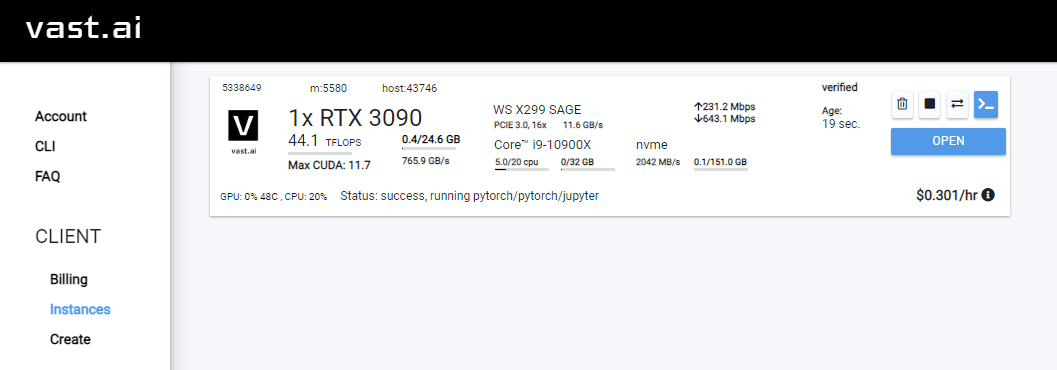
Notebook -> Python 3 (يمكنك القيام بهذه الخطوة التالية عدة طرق ، لكنني عادةً ما أقوم بذلك) 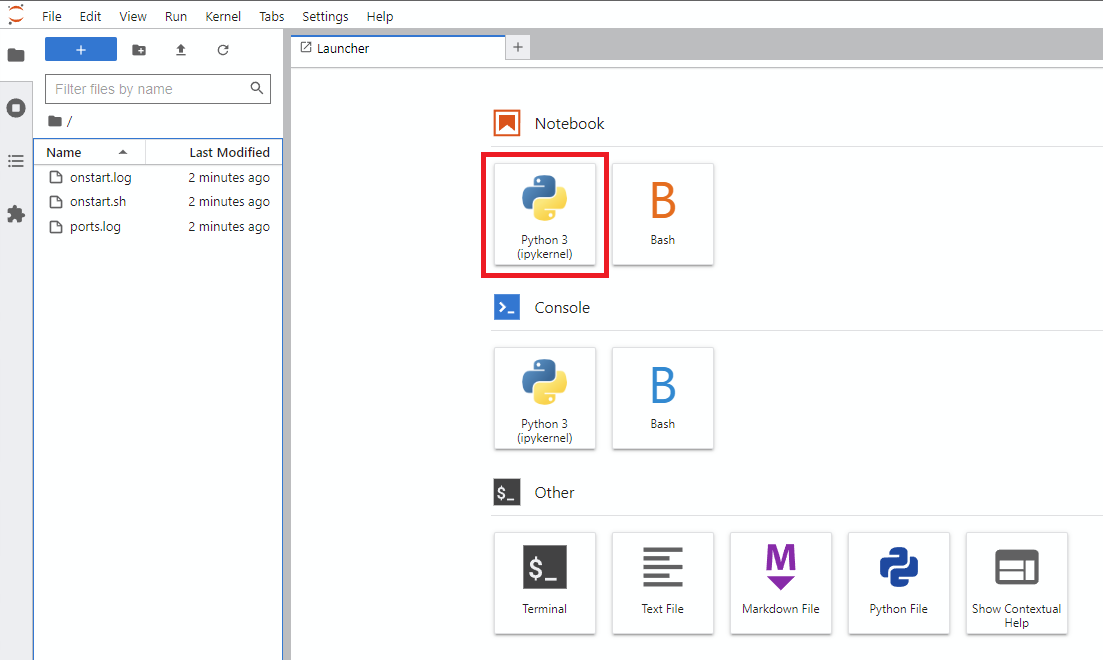
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion.gitrun 
Dreambooth-Stable-Diffusion الجديد على اليسار وافتح إما dreambooth_simple_joepenna.ipynb أو dreambooth_runpod_joepenna.ipynb file 
cmdC:>git clone https://github.com/JoePenna/Dreambooth-Stable-DiffusionC:>cd Dreambooth-Stable-Diffusioncmd > python -m venv dreambooth_joepenna
cmd > dreambooth_joepennaScriptsactivate.bat
cmd > pip install torch == 1.13.1+cu117 torchvision == 0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
cmd > pip install -r requirements.txt cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > deactivate Anaconda Prompt (miniconda3)(base) C:>git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion(base) C:>cd Dreambooth-Stable-Diffusion(base) C:Dreambooth-Stable-Diffusion > conda env create -f environment.yaml
(base) C:Dreambooth-Stable-Diffusion > conda activate dreambooth_joepenna cmd> python "main.py" --project_name "ProjectName" --training_model "C:v1-5-pruned-emaonly-pruned.ckpt" --regularization_images "C:regularization_images" --training_images "C:training_images" --max_training_steps 2000 --class_word "person" --token "zwx" --flip_p 0 --learning_rate 1.0e-06 --save_every_x_steps 250
cmd > conda deactivate {
"class_word": "woman",
"config_date_time": "2023-04-08T16-54-00",
"debug": false,
"flip_percent": 0.0,
"gpu": 0,
"learning_rate": 1e-06,
"max_training_steps": 3500,
"model_path": "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt",
"model_repo_id": "",
"project_config_filename": "my-config.json",
"project_name": "<token> project",
"regularization_images_folder_path": "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim",
"save_every_x_steps": 250,
"schema": 1,
"seed": 23,
"token": "<token>",
"token_only": false,
"training_images": [
"001@a photo of <token> looking down.png",
"002-DUPLICATE@a close photo of <token> smiling wearing a black sweatshirt.png",
"002@a photo of <token> wearing a black sweatshirt sitting on a blue couch.png",
"003@a photo of <token> smiling wearing a red flannel shirt with a door in the background.png",
"004@a photo of <token> wearing a purple sweater dress standing with her arms crossed in front of a piano.png",
"005@a close photo of <token> with her hand on her chin.png",
"005@a photo of <token> with her hand on her chin wearing a dark green coat and a red turtleneck.png",
"006@a close photo of <token>.png",
"007@a close photo of <token>.png",
"008@a photo of <token> wearing a purple turtleneck and earings.png",
"009@a close photo of <token> wearing a red flannel shirt with her hand on her head.png",
"011@a close photo of <token> wearing a black shirt.png",
"012@a close photo of <token> smirking wearing a gray hooded sweatshirt.png",
"013@a photo of <token> standing in front of a desk.png",
"014@a close photo of <token> standing in a kitchen.png",
"015@a photo of <token> wearing a pink sweater with her hand on her forehead sitting on a couch with leaves in the background.png",
"016@a photo of <token> wearing a black shirt standing in front of a door.png",
"017@a photo of <token> smiling wearing a black v-neck sweater sitting on a couch in front of a lamp.png",
"019@a photo of <token> wearing a blue v-neck shirt in front of a door.png",
"020@a photo of <token> looking down with her hand on her face wearing a black sweater.png",
"021@a close photo of <token> pursing her lips wearing a pink hooded sweatshirt.png",
"022@a photo of <token> looking off into the distance wearing a striped shirt.png",
"023@a photo of <token> smiling wearing a blue beanie holding a wine glass with a kitchen table in the background.png",
"024@a close photo of <token> looking at the camera.png"
],
"training_images_count": 24,
"training_images_folder_path": "D:\stable-diffusion\training_images\24 Images - captioned"
}
python "main.py" --config_file_path "path/to/the/my-config.json"
dreambooth_helpers ediuments.py
| يأمر | يكتب | مثال | وصف |
|---|---|---|---|
--config_file_path | خيط | "C:\Users\David\Dreambooth Configs\my-config.json" | المسار ملف التكوين للاستخدام |
--project_name | خيط | "My Project Name" | اسم المشروع |
--debug | بول | False | الافتراضات الاختيارية False . تمكين تسجيل التصحيح |
--seed | int | 23 | الافتراضات الاختيارية إلى 23 . بذرة لذرة |
--max_training_steps | int | 3000 | عدد خطوات التدريب للتشغيل |
--token | خيط | "owhx" | رمز فريد من نوعه تريد تمثيل طرازك المدرب. |
--token_only | بول | False | الافتراضات الاختيارية False . تدريب فقط باستخدام الرمز المميز وليس الفصل. |
--training_model | خيط | "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" | طريق إلى النموذج للتدريب (model.ckpt) |
--training_images | خيط | "D:\stable-diffusion\training_images\24 Images - captioned" | Path to Training Images Directory |
--regularization_images | خيط | "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" | طريق إلى الدليل مع صور التنظيم |
--class_word | خيط | "woman" | تطابق class_word مع فئة الصور التي تريد تدريبها. مثال: man ، woman ، dog ، أو artstyle . |
--flip_p | يطفو | 0.0 | الافتراضات الاختيارية إلى 0.5 . نسبة الوجه. مثال: إذا تم ضبطها على 0.5 ، فسيقلب (مرآة) صور التدريب الخاصة بك 50 ٪ من الوقت. يساعد هذا في توسيع مجموعة البيانات الخاصة بك دون الحاجة إلى تضمين المزيد من صور التدريب. هذا يمكن أن يؤدي إلى نتائج أسوأ للتدريب على الوجه لأن معظم وجوه الناس ليست متناظرة تمامًا. |
--learning_rate | يطفو | 1.0e-06 | الافتراضات الاختيارية إلى 1.0e-06 (0.000001). حدد معدل التعلم. يقبل الترميز العلمي. |
--save_every_x_steps | int | 250 | الافتراضات الاختيارية إلى 0 . يحفظ نقطة تفتيش كل خطوات X. في 0 يحفظ فقط في نهاية التدريب عندما يتم الوصول إلى max_training_steps . |
--gpu | int | 0 | الافتراضات الاختيارية إلى 0 . حدد وحدة معالجة الرسومات بخلاف 0 لاستخدامها في التدريب. لم يتم تنفيذ دعم GPU المتعدد حاليًا. |
python "main.py" --project_name "My Project Name" --max_training_steps 3000 --token "owhx" --training_model "D:\stable-diffusion\models\v1-5-pruned-emaonly-pruned.ckpt" --training_images "D:\stable-diffusion\training_images\24 Images - captioned" --regularization_images "D:\stable-diffusion\regularization_images\Stable-Diffusion-Regularization-Images-person_ddim\person_ddim" --class_word "woman" --flip_p 0.0 --save_every_x_steps 500
التسميات التوضيحية مدعومة. هذا هو الدليل حول كيفية تنفيذنا لهم.
دعنا نقول أن الرمز المميز الخاص بك هو effy وفصلك هو شخص ، جذر البيانات الخاص بك /القطار ثم:
تم training_images/img-001.jpg مع effy person
يمكنك تخصيص التسمية التوضيحية عن طريق إضافته بعد رمز @ في اسم الملف.
/training_images/img-001@a photo of effy => a photo of effy
يمكنك استخدام اثنين من الرموز في التسميات التوضيحية الخاصة بك S أقصى S - و C - الكبير C - للإشارة إلى الموضوع والفئة.
/training_images/img-001@S being a good C.jpg => effy being a good person
لإنشاء موضوع جديد تحتاج فقط لإنشاء مجلد لذلك. لذا:
/training_images/bingo/img-001.jpg => bingo person
يبقى الفصل كما هو ، لكن الموضوع قد تغير الآن.
مرة أخرى - الرمز المميز هو الآن بنغو:
/training_images/bingo/img-001@S is being silly.jpg => bingo is being silly
مجلد واحد أعمق ويمكنك تغيير الفصل: /training_images/bingo/dog/img-001@S being a good C.jpg => bingo being a good dog
لا يأتي كيكر: مستوى واحد أعمق ويمكنك التسمية التوضيحية a picture of effy person الصور: /training_images/effy/person/a picture of/img-001.jpg
غالبية الكود في هذا الريبو كتبه رينون جال وآخرون. آل ، مؤلفي ورقة أبحاث الانعكاس النصي. على الرغم من أن بعض الأفكار حول صور التنظيم والحفاظ على الخسائر السابقة (أفكار من "Dreambooth") تمت إضافةها ، احتمالية كل من فريق معهد ماساتشوستس للتكنولوجيا والباحثين في Google ، أقوم بتسمية هذا الشوكة إلى: "الريبو المعروف سابقًا باسم" Dreambooth "" .
للحصول على تطبيق بديل ، يرجى الاطلاع على "خيار بديل" أدناه.
ground truth (صورة حقيقية ، تحذير: امرأة جميلة جدا) 
نفس موجه لجميع هذه الصور أدناه:
sks person | woman person | Natalie Portman person | Kate Mara person |
|---|---|---|---|
 |  |  |  |
المطالبة مع الرمز المميز الخاص بك فقط. أي "Joepenna" بدلاً من "Joepenna person"
إذا تدربت مع joepenna تحت person الفصل ، يجب أن يعرف النموذج وجهك فقط على النحو التالي:
joepenna person
مثال على ذلك:
غير صحيح ( person المفقود بعد joepenna )
portrait photograph of joepenna 35mm film vintage glass
✅ هذا صحيح (يتم تضمين person بعد joepenna )
portrait photograph of joepenna person 35mm film vintage glass
قد تحصل في بعض الأحيان على شخص يشبهك كيندا مع Joepenna (خاصة إذا تدربت على العديد من الخطوات) ، ولكن هذا فقط لأن هذا التكرار الحالي لـ Dreambooth يتغلب على الرمز المميز لدرجة أنه ينزف في هذا الرمز المميز.
أثناء التدريب ، لا يعرف المستقر أنك شخص. سيحاكي ما يراه.
لذا ، إذا كانت هذه هي صور التدريب الخاصة بك تبدو هكذا:
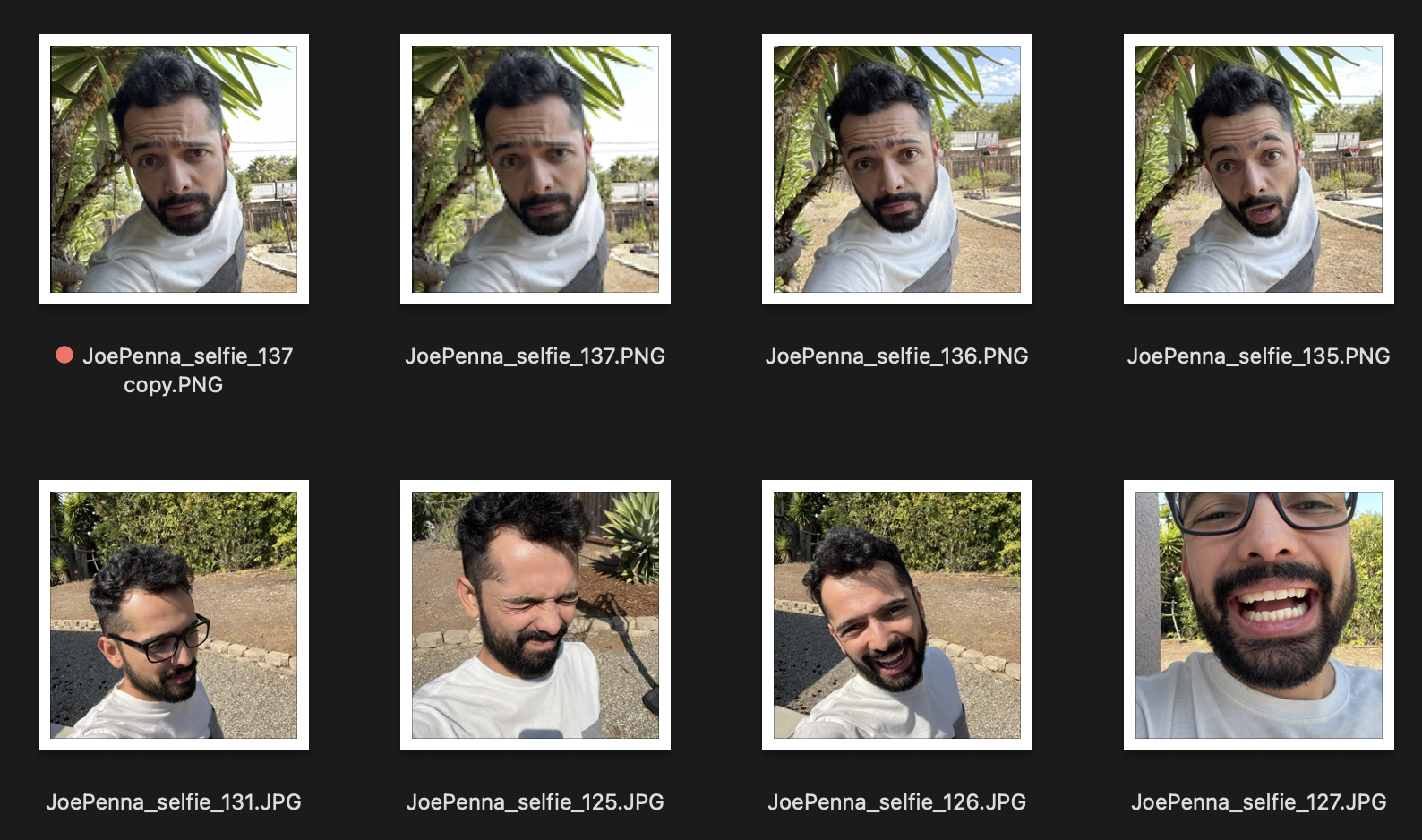
أنت فقط ستحصل على أجيال منك خارج بجوار شجرة شائكة ، ترتدي قميصًا أبيض ورمادي ، بأسلوب ... حسناً ، صورة شخصية.
بدلاً من ذلك ، فإن مجموعة التدريب هذه أفضل بكثير:
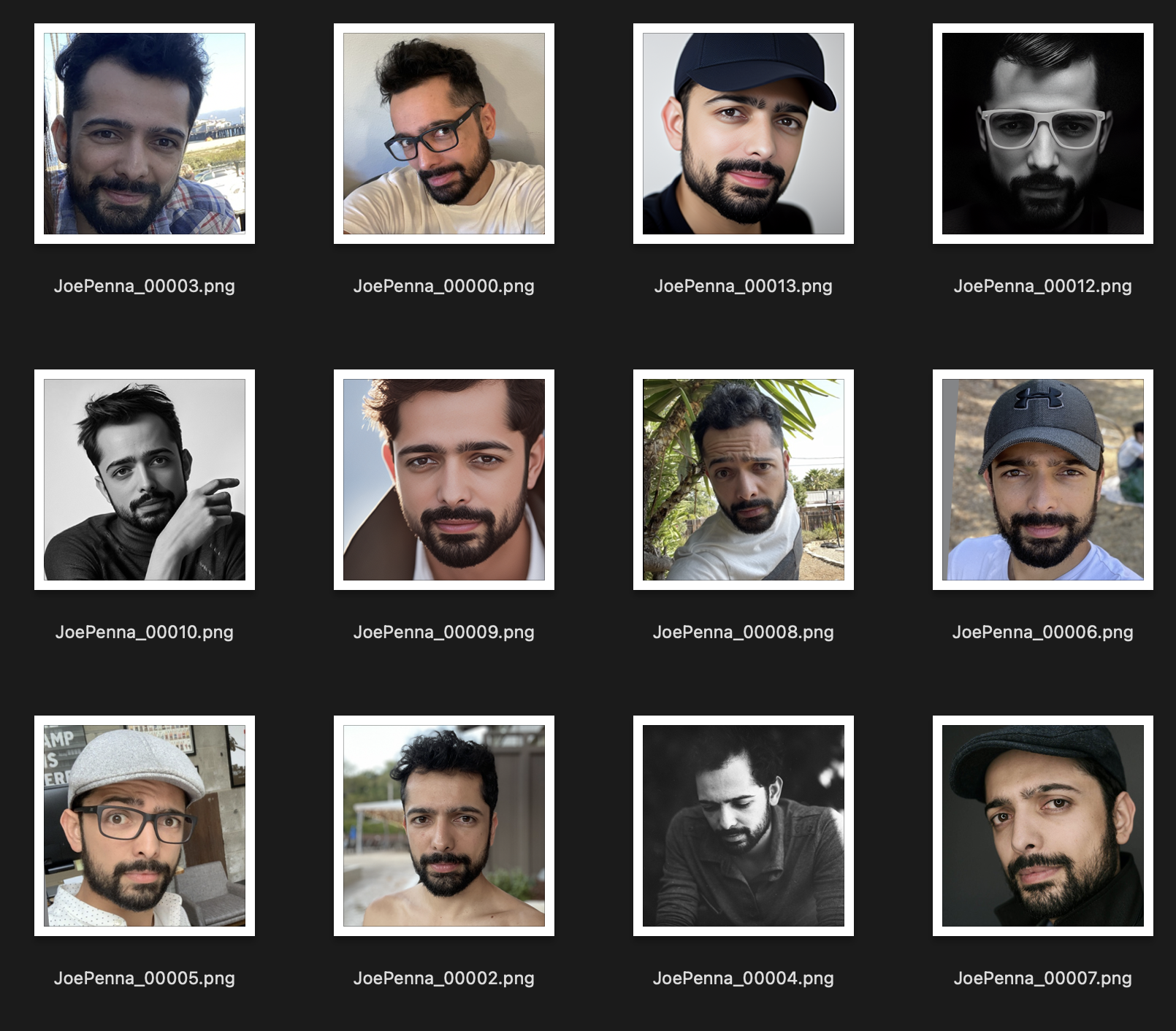
الشيء الوحيد المتسق بين الصور هو الموضوع. لذلك ، سوف ينظر المستقر من خلال الصور ويتعلم وجهك فقط ، مما سيجعل "تحرير" إلى أنماط أخرى ممكنة.
هل أنت متأكد من أنك تطرح ذلك بشكل صحيح؟
يجب أن يكون <token> <class> ، وليس فقط <token> . على سبيل المثال:
JoePenna person, portrait photograph, 85mm medium format photo
إذا كان لا يزال لا يبدو مثلك ، فلن تتدرب لفترة كافية.
حسنًا ، بعض الأسباب التي تجعلك تدربت لفترة طويلة ... أو كانت صورك متشابهة جدًا ... أو لم تتدرب مع صور كافية.
لا مشكلة. يمكننا إصلاح ذلك بالمطالبة. الانتشار المستقر يضع الكثير من الجدارة لكل ما تكتبه أولاً. لذا احفظه في وقت لاحق:
an exquisite portrait photograph, 85mm medium format photo of JoePenna person with a classic haircut
أنت لم تتدرب لفترة كافية ...
لا مشكلة. يمكننا إصلاح ذلك بالمطالبة:
JoePenna person in a portrait photograph, JoePenna person in a 85mm medium format photo of JoePenna person
يتم دعم Dreambooth الآن في نماذج Huggingface للتدريب مع انتشار مستقر.
جربه هنا:


