Downcodes小編報:GoogleDeepMind團隊近日取得重大突破,成功研發名為SCoRe(Self-Correction through Reinforcement Learning)的創新技術,該技術能夠有效解決大型語言模型(LLM)自我糾錯難題。有別於以往依賴多個模型或外部校驗的方法,SCoRe僅依靠自身即可識別並修正錯誤,為AI模型的可靠性和準確性帶來了新的希望。這項技術的核心在於其獨特的兩階段強化學習方法,模型透過自我學習和改進,不斷提升自身的糾錯能力。
谷歌DeepMind研究團隊最近取得重大突破,開發出名為SCoRe(Self-Correction through Reinforcement Learning,透過強化學習進行自我修正)的創新技術。這項技術旨在解決大型語言模型(LLM)難以自我糾正的長期挑戰,無需依賴多個模型或外部檢查即可識別和修復錯誤。
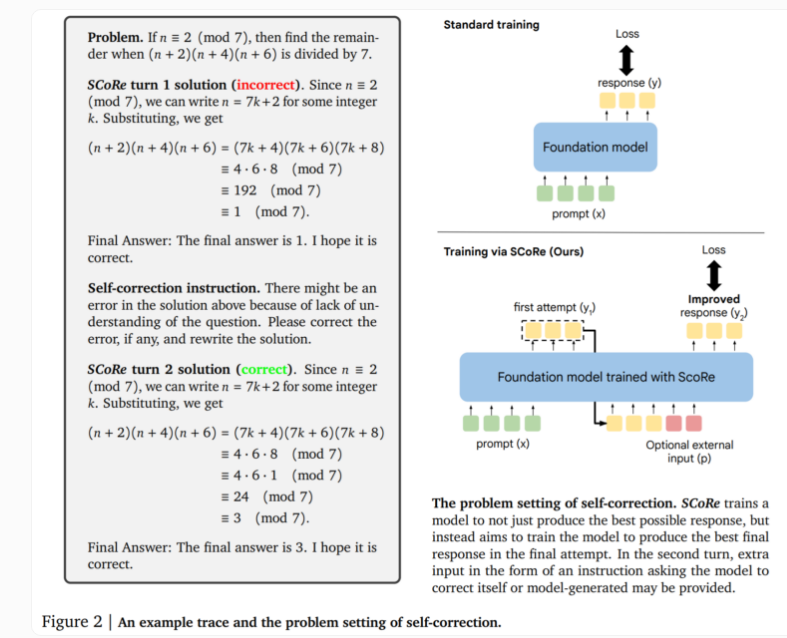
SCoRe技術的核心在於其兩階段方法。第一階段最佳化模型初始化,使其能在第二次嘗試時產生修正,同時保持初始反應與基礎模型的相似性。第二階段採用多階段強化學習,教導模型如何改善第一和第二個答案。這種方法的獨特之處在於它僅使用自生成的訓練數據,模型透過解決問題並嘗試改進解決方案來創建自己的範例。
在實際測試中,SCoRe展現出顯著的效能提升。使用Google的Gemini1.0Pro和1.5Flash模型進行的測試顯示,在MATH基準測試的數學推理任務中,自我糾正能力提高了15.6個百分點。在HumanEval的程式碼產生任務中,效能提升了9.1個百分點。這些結果表明,SCoRe在提高AI模型自我修正能力方面取得了實質進展。
研究人員強調,SCoRe是第一個實現有意義的正向內在自我修正的方法,使模型能夠在沒有外在回饋的情況下改善答案。然而,目前版本的SCoRe僅進行一輪自我修正訓練,未來的研究可能會探索多個修正步驟的可能性。
DeepMind團隊的研究揭示了一個重要洞見:教導自我糾正等元策略需要超越標準的語言模型訓練方法。多階段強化學習為AI領域開啟了新的可能性,有望推動更聰明、更可靠的AI系統的發展。
這項突破性技術不僅展現了AI自我完善的潛力,也為解決大型語言模型的可靠性和準確性問題提供了新的思路,可能對未來AI應用的發展產生深遠影響。
SCoRe技術的出現標誌著AI領域在自我糾錯能力方面取得了里程碑式的進展,為建立更可靠、更聰明的AI系統奠定了堅實的基礎。 Downcodes小編期待未來SCoRe技術能在更多領域得到應用,為人工智慧的發展注入新的活力。