Downcodes editor reports: Google's DeepMind team has recently made a major breakthrough and successfully developed an innovative technology called SCoRe (Self-Correction through Reinforcement Learning), which can effectively solve the self-correction problem of large language models (LLM). Unlike previous methods that relied on multiple models or external verification, SCoRe can identify and correct errors by itself, bringing new hope for the reliability and accuracy of AI models. The core of this technology lies in its unique two-stage reinforcement learning method. The model continuously improves its error correction capabilities through self-learning and improvement.
Google's DeepMind research team recently made a major breakthrough and developed an innovative technology called SCoRe (Self-Correction through Reinforcement Learning, self-correction through reinforcement learning). This technology aims to solve the long-standing challenge that large language models (LLMs) have trouble self-correcting, identifying and fixing errors without relying on multiple models or external checks.
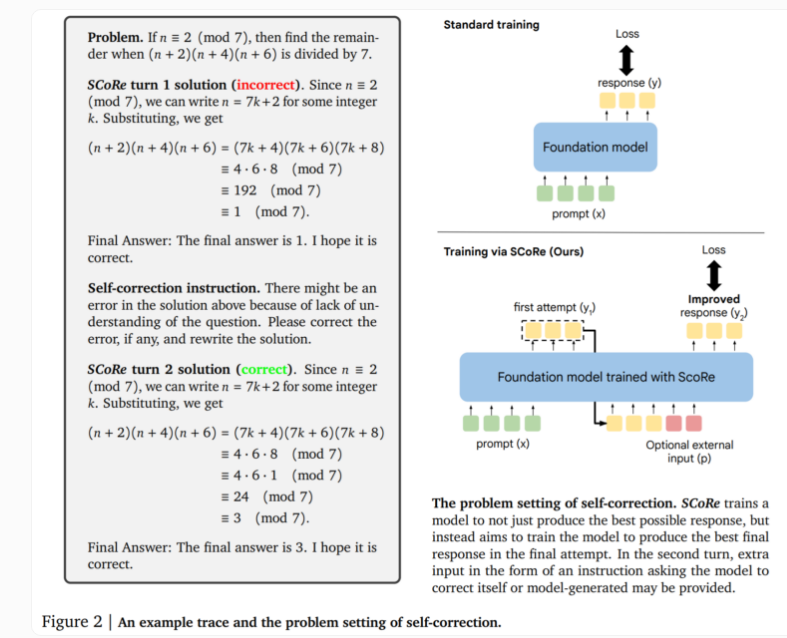
The core of SCoRe technology lies in its two-stage approach. The first stage optimizes the model initialization so that it can generate corrections on the second try while maintaining similarity of the initial response to the base model. The second stage uses multi-stage reinforcement learning to teach the model how to improve the first and second answers. This approach is unique in that it only uses self-generated training data, with the model creating its own examples by solving the problem and trying to improve the solution.
In actual tests, SCoRe showed significant performance improvements. Tests using Google's Gemini 1.0 Pro and 1.5 Flash models showed a 15.6 percentage point improvement in self-correction on the mathematical reasoning task of the MATH benchmark. In HumanEval's code generation task, performance improved by 9.1 percentage points. These results demonstrate that SCoRe has made substantial progress in improving the self-correction capabilities of AI models.
The researchers highlight that SCoRe is the first method to achieve meaningful positive intrinsic self-correction, allowing the model to improve its answers without external feedback. However, the current version of SCoRe only performs one round of self-correction training, and future research may explore the possibility of multiple correction steps.
This research from the DeepMind team reveals an important insight: teaching self-correcting meta-strategies requires going beyond standard language model training methods. Multi-stage reinforcement learning opens up new possibilities in the field of AI and is expected to promote the development of smarter and more reliable AI systems.
This breakthrough technology not only demonstrates the potential of AI self-improvement, but also provides new ideas for solving the reliability and accuracy problems of large-scale language models, which may have a profound impact on the development of future AI applications.
The emergence of SCoRe technology marks a milestone in the field of self-correction capabilities in the AI field, laying a solid foundation for building more reliable and intelligent AI systems. The editor of Downcodes looks forward to the application of SCoRe technology in more fields in the future, injecting new vitality into the development of artificial intelligence.