Laporan editor Downcode: Tim DeepMind Google baru-baru ini membuat terobosan besar dan berhasil mengembangkan teknologi inovatif yang disebut SCoRe (Koreksi Mandiri melalui Pembelajaran Penguatan), yang secara efektif dapat memecahkan masalah koreksi mandiri pada model bahasa besar (LLM). Berbeda dengan metode sebelumnya yang mengandalkan banyak model atau verifikasi eksternal, SCoRe dapat mengidentifikasi dan memperbaiki kesalahan dengan sendirinya, sehingga membawa harapan baru bagi keandalan dan keakuratan model AI. Inti dari teknologi ini terletak pada metode pembelajaran penguatan dua tahap yang unik. Model ini terus meningkatkan kemampuan koreksi kesalahannya melalui pembelajaran mandiri dan peningkatan.
Tim peneliti DeepMind Google baru-baru ini membuat terobosan besar dan mengembangkan teknologi inovatif yang disebut SCoRe (Self-Correction through Reinforcement Learning, koreksi diri melalui pembelajaran penguatan). Teknologi ini bertujuan untuk memecahkan tantangan lama dimana model bahasa besar (LLM) mengalami kesulitan dalam mengoreksi diri sendiri, mengidentifikasi dan memperbaiki kesalahan tanpa bergantung pada banyak model atau pemeriksaan eksternal.
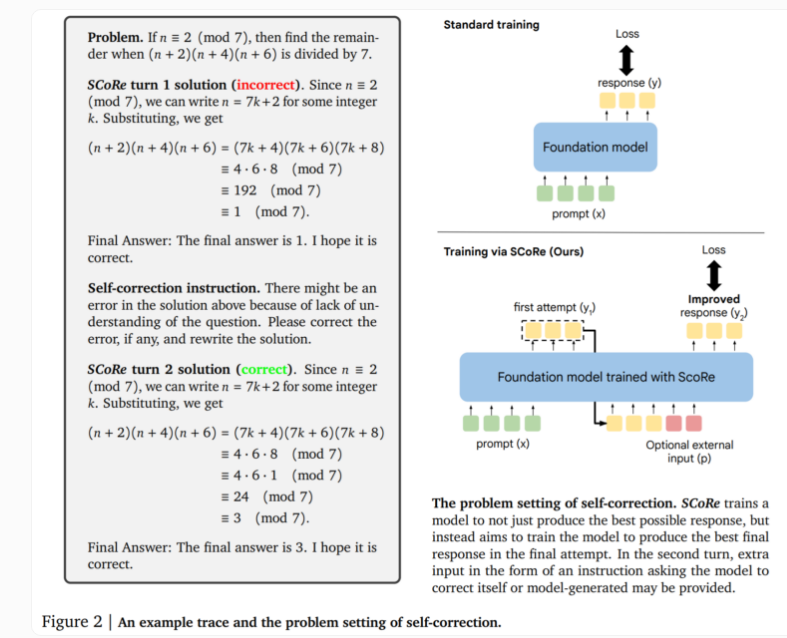
Inti dari teknologi SCoRe terletak pada pendekatan dua tahapnya. Tahap pertama mengoptimalkan inisialisasi model sehingga dapat menghasilkan koreksi pada percobaan kedua dengan tetap menjaga kesamaan respon awal dengan model dasar. Tahap kedua menggunakan pembelajaran penguatan multi-tahap untuk mengajarkan model bagaimana meningkatkan jawaban pertama dan kedua. Pendekatan ini unik karena hanya menggunakan data pelatihan yang dihasilkan sendiri, dan model membuat contohnya sendiri dengan memecahkan masalah dan mencoba meningkatkan solusinya.
Dalam pengujian sebenarnya, SCoRe menunjukkan peningkatan kinerja yang signifikan. Pengujian menggunakan model Google Gemini 1.0 Pro dan 1.5 Flash menunjukkan peningkatan sebesar 15,6 poin persentase dalam koreksi diri pada tugas penalaran matematis dari benchmark MATH. Dalam tugas pembuatan kode HumanEval, kinerja meningkat sebesar 9,1 poin persentase. Hasil ini menunjukkan bahwa SCoRe telah mencapai kemajuan besar dalam meningkatkan kemampuan koreksi mandiri model AI.
Para peneliti menyoroti bahwa SCoRe adalah metode pertama yang mencapai koreksi diri intrinsik positif yang bermakna, memungkinkan model untuk meningkatkan jawabannya tanpa umpan balik eksternal. Namun, versi SCoRe saat ini hanya melakukan satu putaran pelatihan koreksi diri, dan penelitian di masa depan mungkin mengeksplorasi kemungkinan beberapa langkah koreksi.
Penelitian dari tim DeepMind ini mengungkapkan wawasan penting: mengajarkan meta-strategi yang mengoreksi diri memerlukan lebih dari sekadar metode pelatihan model bahasa standar. Pembelajaran penguatan multi-tahap membuka kemungkinan baru di bidang AI dan diharapkan dapat mendorong pengembangan sistem AI yang lebih cerdas dan andal.
Terobosan teknologi ini tidak hanya menunjukkan potensi pengembangan AI, namun juga memberikan ide-ide baru untuk memecahkan masalah keandalan dan akurasi model bahasa berskala besar, yang mungkin berdampak besar pada pengembangan aplikasi AI di masa depan.
Kemunculan teknologi SCoRe menandai tonggak sejarah dalam bidang kemampuan koreksi diri di bidang AI, meletakkan dasar yang kokoh untuk membangun sistem AI yang lebih andal dan cerdas. Editor Downcodes menantikan penerapan teknologi SCoRe di lebih banyak bidang di masa depan, memberikan vitalitas baru ke dalam pengembangan kecerdasan buatan.