Downcodes-Editor berichtet: Googles DeepMind-Team hat kürzlich einen großen Durchbruch erzielt und erfolgreich eine innovative Technologie namens SCoRe (Selbstkorrektur durch Reinforcement Learning) entwickelt, die das Selbstkorrekturproblem großer Sprachmodelle (LLM) effektiv lösen kann. Im Gegensatz zu früheren Methoden, die auf mehreren Modellen oder externer Verifizierung beruhten, kann SCoRe Fehler selbst identifizieren und korrigieren, was neue Hoffnung für die Zuverlässigkeit und Genauigkeit von KI-Modellen weckt. Der Kern dieser Technologie liegt in ihrer einzigartigen zweistufigen Reinforcement-Learning-Methode. Das Modell verbessert kontinuierlich seine Fehlerkorrekturfähigkeiten durch Selbstlernen und Verbesserung.
Das DeepMind-Forschungsteam von Google erzielte kürzlich einen großen Durchbruch und entwickelte eine innovative Technologie namens SCoRe (Selbstkorrektur durch Reinforcement Learning, Selbstkorrektur durch Verstärkungslernen). Diese Technologie zielt darauf ab, das seit langem bestehende Problem zu lösen, dass große Sprachmodelle (LLMs) Schwierigkeiten haben, Fehler selbst zu korrigieren, zu identifizieren und zu beheben, ohne auf mehrere Modelle oder externe Prüfungen angewiesen zu sein.
Der Kern der SCoRe-Technologie liegt in ihrem zweistufigen Ansatz. Die erste Stufe optimiert die Modellinitialisierung, sodass beim zweiten Versuch Korrekturen generiert werden können, während die Ähnlichkeit der anfänglichen Reaktion mit dem Basismodell erhalten bleibt. Die zweite Stufe nutzt mehrstufiges Verstärkungslernen, um dem Modell beizubringen, wie es die erste und zweite Antwort verbessern kann. Das Besondere an diesem Ansatz ist, dass er nur selbst generierte Trainingsdaten verwendet und das Modell seine eigenen Beispiele erstellt, indem es das Problem löst und versucht, die Lösung zu verbessern.
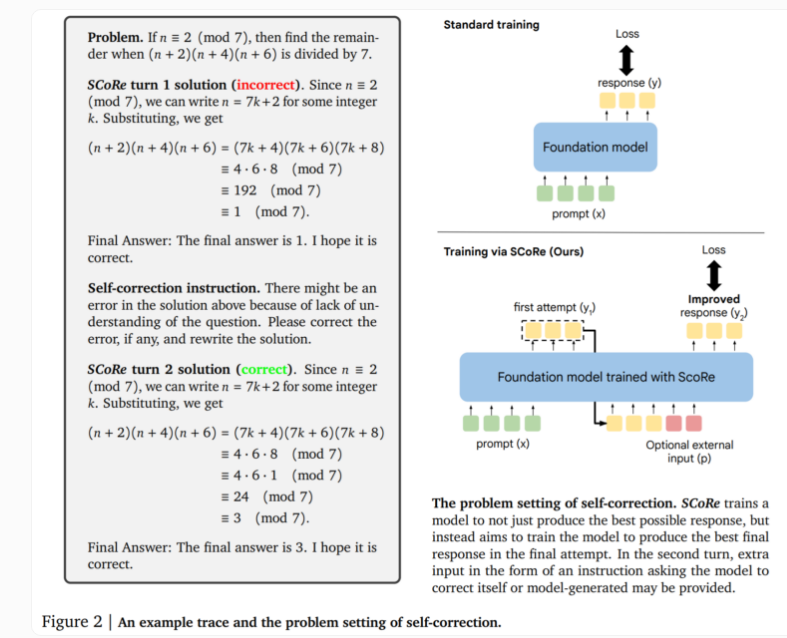
In tatsächlichen Tests zeigte SCoRe deutliche Leistungsverbesserungen. Tests mit den Modellen Gemini 1.0 Pro und 1.5 Flash von Google zeigten eine Verbesserung der Selbstkorrektur um 15,6 Prozentpunkte bei der mathematischen Denkaufgabe des MATH-Benchmarks. Bei der Codegenerierungsaufgabe von HumanEval verbesserte sich die Leistung um 9,1 Prozentpunkte. Diese Ergebnisse zeigen, dass SCoRe erhebliche Fortschritte bei der Verbesserung der Selbstkorrekturfähigkeiten von KI-Modellen gemacht hat.
Die Forscher betonen, dass SCoRe die erste Methode ist, die eine sinnvolle positive intrinsische Selbstkorrektur erreicht und es dem Modell ermöglicht, seine Antworten ohne externes Feedback zu verbessern. Allerdings führt die aktuelle Version von SCoRe nur eine Runde des Selbstkorrekturtrainings durch, und zukünftige Forschungen könnten die Möglichkeit mehrerer Korrekturschritte untersuchen.
Diese Forschung des DeepMind-Teams bringt eine wichtige Erkenntnis zutage: Das Vermitteln selbstkorrigierender Metastrategien erfordert, über die Standardmethoden des Sprachmodelltrainings hinauszugehen. Mehrstufiges Reinforcement Learning eröffnet neue Möglichkeiten im Bereich der KI und soll die Entwicklung intelligenterer und zuverlässigerer KI-Systeme vorantreiben.
Diese bahnbrechende Technologie demonstriert nicht nur das Potenzial der KI-Selbstverbesserung, sondern liefert auch neue Ideen zur Lösung der Zuverlässigkeits- und Genauigkeitsprobleme großer Sprachmodelle, die tiefgreifende Auswirkungen auf die Entwicklung zukünftiger KI-Anwendungen haben können.
Das Aufkommen der SCoRe-Technologie markiert einen Meilenstein auf dem Gebiet der Selbstkorrekturfähigkeiten im KI-Bereich und legt eine solide Grundlage für den Aufbau zuverlässigerer und intelligenterer KI-Systeme. Der Herausgeber von Downcodes freut sich auf die künftige Anwendung der SCoRe-Technologie in weiteren Bereichen, die der Entwicklung künstlicher Intelligenz neuen Schwung verleihen wird.