ダウンコード編集者のレポート: Google の DeepMind チームは最近大きな進歩を遂げ、大規模言語モデル (LLM) の自己修正問題を効果的に解決できる SCoRe (強化学習による自己修正) と呼ばれる革新的なテクノロジの開発に成功しました。複数のモデルや外部検証に依存していた以前の方法とは異なり、SCoRe はエラーを自ら特定して修正できるため、AI モデルの信頼性と精度に新たな期待がもたらされます。このテクノロジーの核心は、独自の 2 段階の強化学習手法にあり、モデルは自己学習と改善を通じてエラー訂正能力を継続的に向上させます。
Google の DeepMind 研究チームは最近大きな進歩を遂げ、SCoRe (Self-Correction through Reinforcement Learning、強化学習による自己修正) と呼ばれる革新的なテクノロジーを開発しました。このテクノロジーは、大規模言語モデル (LLM) が複数のモデルや外部チェックに依存せずにエラーを自己修正、特定、修正するのが難しいという長年の課題を解決することを目的としています。
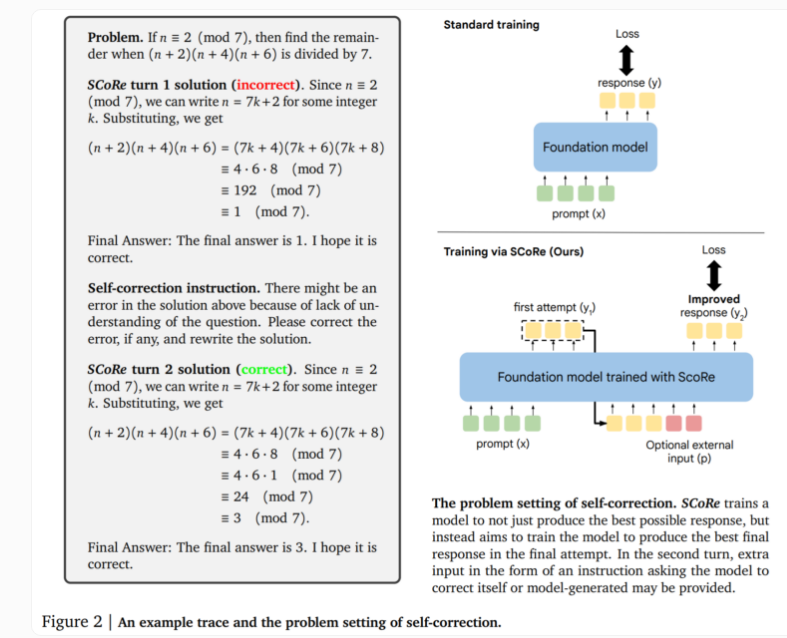
SCoRe テクノロジーの中核は、2 段階のアプローチにあります。最初の段階ではモデルの初期化が最適化され、ベース モデルに対する初期応答の類似性を維持しながら 2 回目の試行で修正を生成できるようになります。第 2 段階では、多段階強化学習を使用して、最初と 2 番目の答えを改善する方法をモデルに教えます。このアプローチは、自己生成されたトレーニング データのみを使用し、モデルが問題を解決してソリューションの改善を試みることによって独自のサンプルを作成するという点で独特です。
実際のテストでは、SCoRe は大幅なパフォーマンスの向上を示しました。 Google の Gemini 1.0 Pro および 1.5 Flash モデルを使用したテストでは、MATH ベンチマークの数学的推論タスクの自己修正が 15.6 パーセント ポイント向上したことが示されました。 HumanEval のコード生成タスクでは、パフォーマンスが 9.1 パーセント向上しました。これらの結果は、SCoRe が AI モデルの自己修正機能の向上において大幅な進歩を遂げたことを示しています。
研究者らは、SCoRe が意味のあるポジティブな本質的自己修正を達成する最初の方法であり、外部フィードバックなしでモデルの答えを改善できることを強調しています。ただし、現在のバージョンの SCoRe は自己修正トレーニングを 1 ラウンドのみ実行するため、将来の研究では複数の修正ステップの可能性が探られる可能性があります。
DeepMind チームによるこの調査では、自己修正メタ戦略を教えるには、標準的な言語モデルのトレーニング方法を超える必要があるという重要な洞察が明らかになりました。多段階強化学習は AI 分野に新たな可能性をもたらし、よりスマートで信頼性の高い AI システムの開発を促進すると期待されています。
この画期的なテクノロジーは、AI の自己改善の可能性を実証するだけでなく、大規模な言語モデルの信頼性と精度の問題を解決するための新しいアイデアを提供し、将来の AI アプリケーションの開発に大きな影響を与える可能性があります。
SCoRe テクノロジーの登場は、AI 分野における自己修正機能のマイルストーンとなり、より信頼性が高くインテリジェントな AI システムを構築するための強固な基盤を築きます。 Downcodes の編集者は、将来的には SCoRe テクノロジーがより多くの分野に応用され、人工知能の開発に新たな活力が吹き込まれることを期待しています。