รายงานตัวแก้ไข Downcodes: ทีม DeepMind ของ Google ได้สร้างความก้าวหน้าครั้งใหญ่เมื่อเร็ว ๆ นี้และประสบความสำเร็จในการพัฒนาเทคโนโลยีนวัตกรรมที่เรียกว่า SCoRe (การแก้ไขตนเองผ่านการเรียนรู้แบบเสริมกำลัง) ซึ่งสามารถแก้ไขปัญหาการแก้ไขด้วยตนเองของแบบจำลองภาษาขนาดใหญ่ (LLM) ได้อย่างมีประสิทธิภาพ แตกต่างจากวิธีการก่อนหน้านี้ที่ต้องอาศัยแบบจำลองหลายแบบหรือการตรวจสอบจากภายนอก SCoRe สามารถระบุและแก้ไขข้อผิดพลาดได้ด้วยตัวเอง นำมาซึ่งความหวังใหม่สำหรับความน่าเชื่อถือและความแม่นยำของแบบจำลอง AI แกนหลักของเทคโนโลยีนี้อยู่ที่วิธีการเรียนรู้แบบเสริมกำลังสองขั้นตอนอันเป็นเอกลักษณ์ โมเดลดังกล่าวปรับปรุงความสามารถในการแก้ไขข้อผิดพลาดอย่างต่อเนื่องผ่านการเรียนรู้ด้วยตนเองและการปรับปรุง
เมื่อเร็วๆ นี้ ทีมวิจัย DeepMind ของ Google ได้สร้างความก้าวหน้าครั้งใหญ่และพัฒนาเทคโนโลยีนวัตกรรมที่เรียกว่า SCoRe (การแก้ไขตนเองผ่านการเรียนรู้แบบเสริมกำลัง การแก้ไขตนเองผ่านการเรียนรู้แบบเสริมกำลัง) เทคโนโลยีนี้มีจุดมุ่งหมายเพื่อแก้ปัญหาความท้าทายที่มีมายาวนานว่าโมเดลภาษาขนาดใหญ่ (LLM) มีปัญหาในการแก้ไขด้วยตนเอง การระบุ และแก้ไขข้อผิดพลาดโดยไม่ต้องอาศัยหลายโมเดลหรือการตรวจสอบจากภายนอก
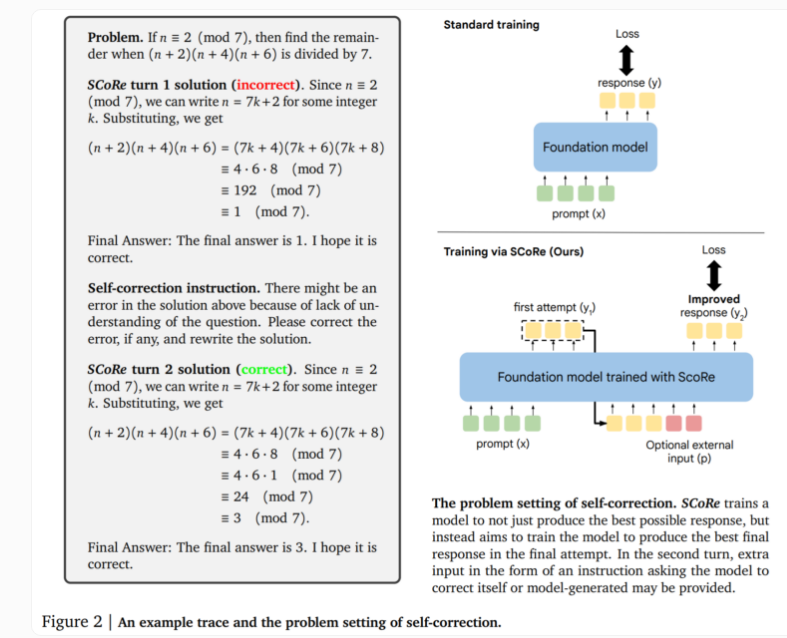
แกนหลักของเทคโนโลยี SCoRe อยู่ที่แนวทางสองขั้นตอน ขั้นแรกจะปรับการเริ่มต้นโมเดลให้เหมาะสม เพื่อให้สามารถสร้างการแก้ไขในการลองครั้งที่สอง ในขณะที่ยังคงรักษาความคล้ายคลึงกันของการตอบสนองเริ่มต้นกับโมเดลพื้นฐาน ขั้นตอนที่สองใช้การเรียนรู้แบบเสริมกำลังแบบหลายขั้นตอนเพื่อสอนแบบจำลองถึงวิธีปรับปรุงคำตอบที่หนึ่งและสอง แนวทางนี้มีเอกลักษณ์เฉพาะตรงที่ใช้เฉพาะข้อมูลการฝึกอบรมที่สร้างขึ้นเอง โดยแบบจำลองจะสร้างตัวอย่างของตัวเองโดยการแก้ปัญหาและพยายามปรับปรุงโซลูชัน
ในการทดสอบจริง SCoRe แสดงให้เห็นการปรับปรุงประสิทธิภาพที่สำคัญ การทดสอบโดยใช้โมเดล Gemini 1.0 Pro และ 1.5 Flash ของ Google พบว่าการแก้ไขตัวเองในงานการให้เหตุผลทางคณิตศาสตร์ของเกณฑ์มาตรฐาน MATH มีการปรับปรุง 15.6 เปอร์เซ็นต์ ในงานสร้างโค้ดของ HumanEval ประสิทธิภาพดีขึ้น 9.1 เปอร์เซ็นต์ ผลลัพธ์เหล่านี้แสดงให้เห็นว่า SCoRe มีความก้าวหน้าอย่างมากในการปรับปรุงความสามารถในการแก้ไขตัวเองของโมเดล AI
นักวิจัยเน้นย้ำว่า SCoRe เป็นวิธีแรกในการบรรลุการแก้ไขตนเองเชิงบวกที่มีความหมาย ซึ่งช่วยให้แบบจำลองสามารถปรับปรุงคำตอบได้โดยไม่ต้องมีข้อเสนอแนะจากภายนอก อย่างไรก็ตาม SCoRe เวอร์ชันปัจจุบันทำการฝึกอบรมการแก้ไขตัวเองเพียงรอบเดียวเท่านั้น และการวิจัยในอนาคตอาจสำรวจความเป็นไปได้ของขั้นตอนการแก้ไขหลายขั้นตอน
งานวิจัยจากทีม DeepMind นี้เผยให้เห็นข้อมูลเชิงลึกที่สำคัญ: การสอนกลยุทธ์เมตาที่แก้ไขตัวเองนั้นจำเป็นต้องทำมากกว่าวิธีการฝึกอบรมโมเดลภาษามาตรฐาน การเรียนรู้การเสริมกำลังแบบหลายขั้นตอนเปิดโอกาสใหม่ๆ ในด้าน AI และคาดว่าจะส่งเสริมการพัฒนาระบบ AI ที่ชาญฉลาดและเชื่อถือได้มากขึ้น
เทคโนโลยีที่ก้าวหน้านี้ไม่เพียงแต่แสดงให้เห็นถึงศักยภาพของการพัฒนาตนเองของ AI เท่านั้น แต่ยังให้แนวคิดใหม่ในการแก้ปัญหาความน่าเชื่อถือและความแม่นยำของแบบจำลองภาษาขนาดใหญ่ ซึ่งอาจมีผลกระทบอย่างมากต่อการพัฒนาแอปพลิเคชัน AI ในอนาคต
การเกิดขึ้นของเทคโนโลยี SCoRe ถือเป็นก้าวสำคัญในด้านความสามารถในการแก้ไขตัวเองในด้าน AI โดยวางรากฐานที่มั่นคงสำหรับการสร้างระบบ AI ที่เชื่อถือได้และชาญฉลาดยิ่งขึ้น บรรณาธิการของ Downcodes ตั้งตารอคอยการประยุกต์ใช้เทคโนโลยี SCoRe ในสาขาอื่นๆ มากขึ้นในอนาคต โดยอัดฉีดพลังใหม่ๆ ให้กับการพัฒนาปัญญาประดิษฐ์