Informes del editor de Downcodes: El equipo DeepMind de Google ha logrado recientemente un gran avance y ha desarrollado con éxito una tecnología innovadora llamada SCoRe (Autocorrección a través del aprendizaje por refuerzo), que puede resolver eficazmente el problema de autocorrección de los modelos de lenguaje grandes (LLM). A diferencia de los métodos anteriores que dependían de múltiples modelos o verificación externa, SCoRe puede identificar y corregir errores por sí solo, lo que brinda nuevas esperanzas para la confiabilidad y precisión de los modelos de IA. El núcleo de esta tecnología radica en su exclusivo método de aprendizaje por refuerzo de dos etapas. El modelo mejora continuamente sus capacidades de corrección de errores mediante el autoaprendizaje y la mejora.
El equipo de investigación DeepMind de Google logró recientemente un gran avance y desarrolló una tecnología innovadora llamada SCoRe (Autocorrección a través del aprendizaje por refuerzo, autocorrección a través del aprendizaje por refuerzo). Esta tecnología tiene como objetivo resolver el desafío de larga data de que los modelos de lenguaje grandes (LLM) tienen problemas para autocorregirse, identificar y corregir errores sin depender de múltiples modelos o verificaciones externas.
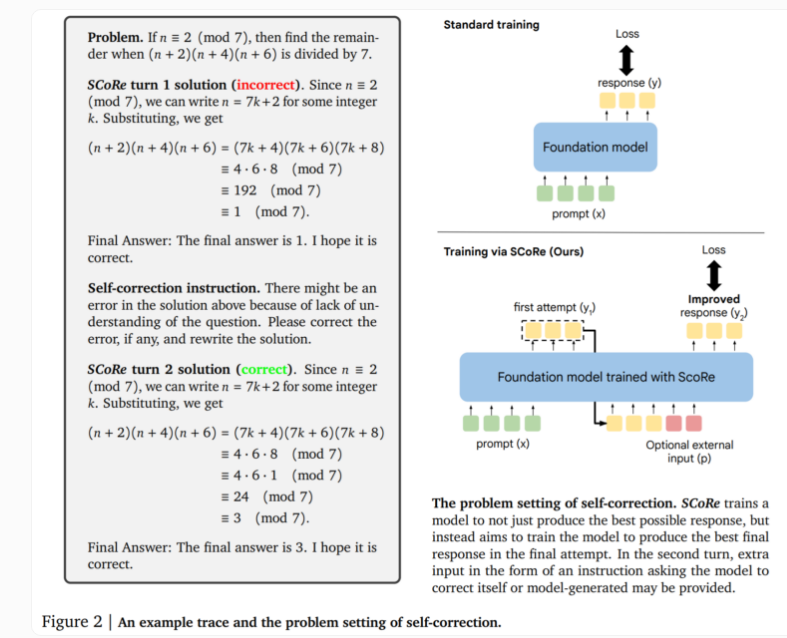
El núcleo de la tecnología SCoRe reside en su enfoque en dos etapas. La primera etapa optimiza la inicialización del modelo para que pueda generar correcciones en el segundo intento manteniendo la similitud de la respuesta inicial con el modelo base. La segunda etapa utiliza el aprendizaje por refuerzo de múltiples etapas para enseñar al modelo cómo mejorar la primera y la segunda respuesta. Este enfoque es único porque solo utiliza datos de entrenamiento autogenerados, y el modelo crea sus propios ejemplos resolviendo el problema e intentando mejorar la solución.
En pruebas reales, SCoRe mostró importantes mejoras de rendimiento. Las pruebas que utilizaron los modelos Gemini 1.0 Pro y 1.5 Flash de Google mostraron una mejora de 15,6 puntos porcentuales en la autocorrección en la tarea de razonamiento matemático del punto de referencia MATH. En la tarea de generación de código de HumanEval, el rendimiento mejoró en 9,1 puntos porcentuales. Estos resultados demuestran que SCoRe ha logrado avances sustanciales en la mejora de las capacidades de autocorrección de los modelos de IA.
Los investigadores destacan que SCoRe es el primer método para lograr una autocorrección intrínseca positiva significativa, lo que permite al modelo mejorar sus respuestas sin retroalimentación externa. Sin embargo, la versión actual de SCoRe solo realiza una ronda de entrenamiento de autocorrección y futuras investigaciones pueden explorar la posibilidad de múltiples pasos de corrección.
Esta investigación del equipo de DeepMind revela una idea importante: enseñar metaestrategias de autocorrección requiere ir más allá de los métodos de entrenamiento de modelos de lenguaje estándar. El aprendizaje por refuerzo en múltiples etapas abre nuevas posibilidades en el campo de la IA y se espera que promueva el desarrollo de sistemas de IA más inteligentes y confiables.
Esta innovadora tecnología no sólo demuestra el potencial de la superación personal de la IA, sino que también proporciona nuevas ideas para resolver los problemas de confiabilidad y precisión de los modelos lingüísticos a gran escala, lo que puede tener un profundo impacto en el desarrollo de futuras aplicaciones de IA.
La aparición de la tecnología SCoRe marca un hito en el campo de las capacidades de autocorrección en el campo de la IA y sienta una base sólida para construir sistemas de IA más confiables e inteligentes. El editor de Downcodes espera que la tecnología SCoRe se aplique en más campos en el futuro, inyectando nueva vitalidad al desarrollo de la inteligencia artificial.