다운코드 편집자 보고서: Google의 DeepMind 팀은 최근 대규모 언어 모델(LLM)의 자체 수정 문제를 효과적으로 해결할 수 있는 SCoRe(강화 학습을 통한 자체 수정)라는 혁신적인 기술을 성공적으로 개발하여 획기적인 발전을 이루었습니다. SCoRe는 여러 모델이나 외부 검증에 의존했던 기존 방식과 달리 오류를 스스로 파악하고 수정할 수 있어 AI 모델의 신뢰성과 정확성에 대한 새로운 희망을 안겨준다. 이 기술의 핵심은 모델 특유의 2단계 강화학습 방식으로, 자가 학습과 개선을 통해 오류 수정 능력을 지속적으로 향상시키는 데 있습니다.
Google DeepMind 연구팀은 최근 SCoRe(Self-Correction through Reinforcement Learning, Self-corrrection through Reinforcement Learning)이라는 혁신적인 기술을 개발하는 데 큰 진전을 이루었습니다. 이 기술은 여러 모델이나 외부 검사에 의존하지 않고 LLM(대형 언어 모델)이 자체 수정, 오류 식별 및 수정에 어려움을 겪는 오랜 문제를 해결하는 것을 목표로 합니다.
SCoRe 기술의 핵심은 2단계 접근 방식에 있습니다. 첫 번째 단계에서는 기본 모델에 대한 초기 응답의 유사성을 유지하면서 두 번째 시도에서 수정 사항을 생성할 수 있도록 모델 초기화를 최적화합니다. 두 번째 단계에서는 다단계 강화 학습을 사용하여 첫 번째와 두 번째 답변을 개선하는 방법을 모델에 가르칩니다. 이 접근 방식은 자체 생성된 훈련 데이터만 사용하며, 모델은 문제를 해결하고 솔루션 개선을 시도하여 자체 예제를 생성한다는 점에서 독특합니다.
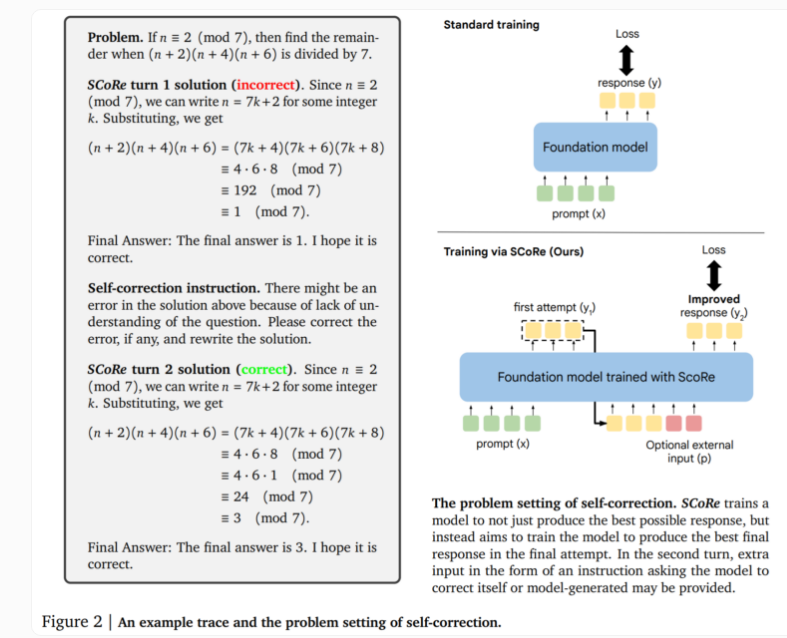
실제 테스트에서 SCoRe는 상당한 성능 향상을 보여주었습니다. Google의 Gemini 1.0 Pro 및 1.5 Flash 모델을 사용한 테스트에서는 MATH 벤치마크의 수학적 추론 작업에서 자체 수정이 15.6% 포인트 향상된 것으로 나타났습니다. HumanEval의 코드 생성 작업에서는 성능이 9.1% 포인트 향상되었습니다. 이러한 결과는 SCoRe가 AI 모델의 자체 수정 기능을 향상시키는 데 상당한 진전을 이루었음을 보여줍니다.
연구원들은 SCoRe가 의미 있는 긍정적인 본질적인 자기 교정을 달성하는 첫 번째 방법이며, 모델이 외부 피드백 없이 답변을 개선할 수 있도록 해준다는 점을 강조합니다. 그러나 SCoRe의 현재 버전은 한 번의 자기 교정 훈련만 수행하며 향후 연구에서는 여러 교정 단계의 가능성을 탐색할 수 있습니다.
DeepMind 팀의 이 연구는 중요한 통찰력을 보여줍니다. 즉, 자체 수정 메타 전략을 가르치려면 표준 언어 모델 훈련 방법 이상의 것이 필요합니다. 다단계 강화학습은 AI 분야에 새로운 가능성을 열어주며, 더욱 스마트하고 안정적인 AI 시스템 개발을 촉진할 것으로 기대됩니다.
이 획기적인 기술은 AI 자체 개선의 잠재력을 보여줄 뿐만 아니라, 미래 AI 애플리케이션 개발에 지대한 영향을 미칠 수 있는 대규모 언어 모델의 신뢰성과 정확성 문제를 해결하기 위한 새로운 아이디어를 제공합니다.
SCoRe 기술의 출현은 AI 분야의 자가 교정 기능 분야에서 이정표를 세우며, 보다 안정적이고 지능적인 AI 시스템을 구축하기 위한 견고한 기반을 마련했습니다. 다운코드 편집장은 앞으로 SCoRe 기술이 더 많은 분야에 적용돼 인공지능 발전에 새로운 활력을 불어넣을 것으로 기대한다.