隨著語音合成技術的快速發展,語音偽造帶來的安全隱憂日益突出。為了因應這項挑戰,浙江大學智慧系統安全實驗室和清華大學聯合研發出了一個創新的語音偽造檢測框架-SafeEar。該框架在保護用戶語音隱私的同時,實現了高效的偽造檢測,為保障資訊安全提供了新的解決方案。 Downcodes小編將帶你深入了解SafeEar的獨特之處。
在現今快速語音合成轉換技術背景下,語音偽造日益嚴重,使用者隱私和社會安全帶來了不小的威脅。近日,浙江大學智慧系統安全實驗室和清大學聯合發布了一種新型的語音偽造檢測框架,名為「SafeEar」。
此框架致力於在保護語音內容隱私的同時,實現高效的偽造檢測,充分應對語音合成帶來的。
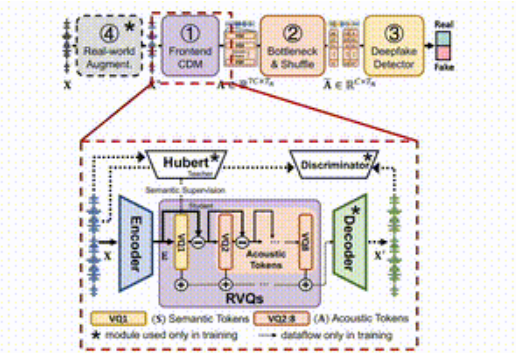
SafeEar 的想法是透過設計基於神經音訊編解碼器的解耦模型,巧妙地將語音的聲學與語義訊息分開。這意味著,SafeEar 僅依賴聲學資訊進行偽造檢測,而無需接觸音的完整內容,這樣就能有效防止隱私外洩。
整個框架分為四個主要部分。
首先,前端解耦模型負責從輸入的語音中提取目標聲學特徵;其次,瓶頸層和混淆層則通過降維和打亂聲學特徵,提高了對內容竊取的抵禦能力;第三,偽造檢測器利用了Transformer 分類器來判斷音訊是否被偽造;最後,真實環境增強模組則透過模擬不同的音訊環境,進一步了模型的偵測。
專案入口:https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
經過多個基準資料集的實驗,研究團隊發現SafeEar 的錯誤率低至2.02%。這意味著它在識別深偽音訊方面非常有效!而且,SafeEar 還能夠保護五種語言的音訊內容,使其不易被機器或人耳解析,單字錯誤率高達93.93%。同時,透過測試,研究人員發現攻擊者無法恢復被保護的語音內容,顯示出該技術在隱私保護方面的優勢。
此外,SafeEar 團隊還建立了一個包含150萬條多語言音訊資料的資料集涵蓋了英語、中文、德語文法語和義大利語等多種,為未來的語音偽造檢測和研究提供了豐富的基礎資料。
SafeEar 的推出不僅為語音偽造檢測領域帶來了新的解決方案,也為保護用戶的語音隱私鋪平了道路。
劃重點:
SafeEar 的出現為對抗語音偽造技術提供了強大的武器,其在隱私保護和安全檢測方面的突出表現值得關注。 期待未來SafeEar能進一步完善,更能服務社會安全。