ด้วยการพัฒนาอย่างรวดเร็วของเทคโนโลยีการสังเคราะห์เสียงพูด ความเสี่ยงด้านความปลอดภัยที่เกิดจากการปลอมแปลงคำพูดจึงมีความโดดเด่นมากขึ้น เพื่อจัดการกับความท้าทายนี้ ห้องปฏิบัติการรักษาความปลอดภัยระบบอัจฉริยะของมหาวิทยาลัยเจ้อเจียง และมหาวิทยาลัยชิงหัวได้ร่วมกันพัฒนากรอบการตรวจจับการปลอมแปลงด้วยเสียงที่เป็นนวัตกรรมใหม่ - SafeEar เฟรมเวิร์กนี้บรรลุการตรวจจับการปลอมแปลงที่มีประสิทธิภาพพร้อมทั้งปกป้องความเป็นส่วนตัวของเสียงของผู้ใช้ ซึ่งเป็นโซลูชันใหม่สำหรับการรับรองความปลอดภัยของข้อมูล บรรณาธิการของ Downcodes จะพาคุณไปทำความเข้าใจถึงเอกลักษณ์ของ SafeEar
ในบริบทของเทคโนโลยีการสังเคราะห์เสียงและการแปลงคำพูดที่รวดเร็วในปัจจุบัน การปลอมแปลงเสียงเริ่มมีความร้ายแรงมากขึ้นเรื่อยๆ ซึ่งก่อให้เกิดภัยคุกคามต่อความเป็นส่วนตัวของผู้ใช้และความมั่นคงทางสังคมอย่างมาก เมื่อเร็วๆ นี้ ห้องทดลองความปลอดภัยระบบอัจฉริยะของมหาวิทยาลัยเจ้อเจียงและมหาวิทยาลัยชิงหัวได้ร่วมกันเปิดตัวกรอบการตรวจจับการปลอมแปลงด้วยเสียงแบบใหม่ที่เรียกว่า "SafeEar"
กรอบการทำงานนี้มุ่งมั่นที่จะบรรลุการตรวจจับการปลอมแปลงที่มีประสิทธิภาพในขณะเดียวกันก็ปกป้องความเป็นส่วนตัวของเนื้อหาเสียง และจัดการกับปัญหาที่เกิดจากการสังเคราะห์เสียงอย่างเต็มที่
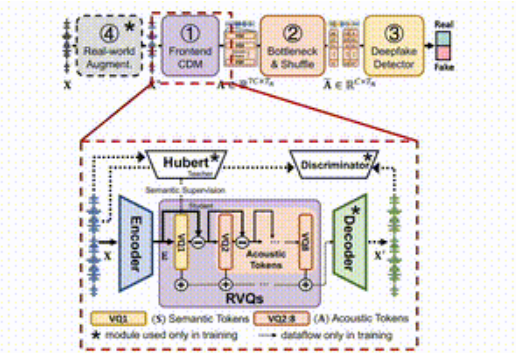
แนวคิดของ SafeEar คือการแยกข้อมูลเสียงพูดและความหมายอย่างชาญฉลาดโดยการออกแบบแบบจำลองแยกส่วนตามตัวแปลงสัญญาณเสียงแบบประสาท ซึ่งหมายความว่า SafeEar ใช้เฉพาะข้อมูลเสียงในการตรวจจับการปลอมแปลงโดยไม่ต้องสัมผัสกับเนื้อหาเสียงทั้งหมด ซึ่งสามารถป้องกันการรั่วไหลของความเป็นส่วนตัวได้อย่างมีประสิทธิภาพ
กรอบงานทั้งหมดแบ่งออกเป็นสี่ส่วนหลัก
ประการแรก โมเดลการแยกส่วนส่วนหน้ามีหน้าที่แยกคุณสมบัติทางเสียงเป้าหมายออกจากคำพูดอินพุต ประการที่สอง ชั้นคอขวดและชั้นความสับสนปรับปรุงความต้านทานต่อการขโมยเนื้อหาโดยการลดขนาดและรบกวนคุณสมบัติทางเสียง ประการที่สาม เครื่องตรวจจับการปลอมแปลงใช้ Transformer ลักษณนามเพื่อตรวจสอบว่าเสียงได้รับการปลอมแปลงหรือไม่ ในที่สุดโมดูลการปรับปรุงสภาพแวดล้อมจริงจะปรับปรุงการตรวจจับแบบจำลองเพิ่มเติมโดยการจำลองสภาพแวดล้อมเสียงที่แตกต่างกัน
ทางเข้าโครงการ: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
หลังจากการทดลองกับชุดข้อมูลเกณฑ์มาตรฐานหลายชุด ทีมวิจัยพบว่าอัตราข้อผิดพลาดของ SafeEar ต่ำถึง 2.02% ซึ่งหมายความว่ามีประสิทธิภาพมากในการระบุเสียง Deepfake! นอกจากนี้ SafeEar ยังสามารถปกป้องเนื้อหาเสียงในห้าภาษา ทำให้ยากต่อการแยกวิเคราะห์โดยเครื่องจักรหรือหูของมนุษย์ โดยมีอัตราความผิดพลาดของคำสูงถึง 93.93% ในขณะเดียวกัน จากการทดสอบ นักวิจัยพบว่าผู้โจมตีไม่สามารถกู้คืนเนื้อหาเสียงที่ได้รับการป้องกันได้ ซึ่งแสดงให้เห็นถึงข้อดีของเทคโนโลยีในการปกป้องความเป็นส่วนตัว
นอกจากนี้ ทีม SafeEar ยังสร้างชุดข้อมูลที่ประกอบด้วยข้อมูลเสียงหลายภาษาจำนวน 1.5 ล้านชิ้น ซึ่งครอบคลุมภาษาอังกฤษ จีน เยอรมัน ฝรั่งเศส และอิตาลี ซึ่งเป็นข้อมูลพื้นฐานที่สมบูรณ์สำหรับการตรวจจับและการวิจัยการปลอมแปลงเสียงในอนาคต
การเปิดตัว SafeEar ไม่เพียงแต่นำโซลูชั่นใหม่ๆ มาสู่การตรวจจับการปลอมแปลงด้วยเสียงเท่านั้น แต่ยังปูทางในการปกป้องความเป็นส่วนตัวของเสียงของผู้ใช้อีกด้วย
ไฮไลท์:
การเกิดขึ้นของ SafeEar ถือเป็นอาวุธอันทรงพลังในการต่อต้านเทคโนโลยีการปลอมแปลงเสียง และประสิทธิภาพที่โดดเด่นในการปกป้องความเป็นส่วนตัวและการตรวจจับความปลอดภัยสมควรได้รับความสนใจ เราหวังว่าจะได้รับการปรับปรุง SafeEar เพิ่มเติมในอนาคตเพื่อรองรับการประกันสังคมที่ดียิ่งขึ้น