Dengan pesatnya perkembangan teknologi sintesis ucapan, risiko keamanan yang disebabkan oleh pemalsuan ucapan menjadi semakin menonjol. Untuk mengatasi tantangan ini, Laboratorium Keamanan Sistem Cerdas Universitas Zhejiang dan Universitas Tsinghua bersama-sama mengembangkan kerangka kerja deteksi pemalsuan suara yang inovatif – SafeEar. Kerangka kerja ini mencapai deteksi pemalsuan yang efisien sekaligus melindungi privasi suara pengguna, memberikan solusi baru untuk memastikan keamanan informasi. Editor Downcodes akan membawa Anda memahami keunikan SafeEar.
Dalam konteks sintesis ucapan dan teknologi konversi yang cepat saat ini, pemalsuan suara menjadi semakin serius, sehingga menimbulkan ancaman besar terhadap privasi pengguna dan keamanan sosial. Baru-baru ini, Laboratorium Keamanan Sistem Cerdas Universitas Zhejiang dan Universitas Tsinghua bersama-sama merilis kerangka deteksi pemalsuan suara baru yang disebut "SafeEar".
Kerangka kerja ini berkomitmen untuk mencapai deteksi pemalsuan yang efisien sekaligus melindungi privasi konten suara, dan sepenuhnya mengatasi masalah yang disebabkan oleh sintesis ucapan.
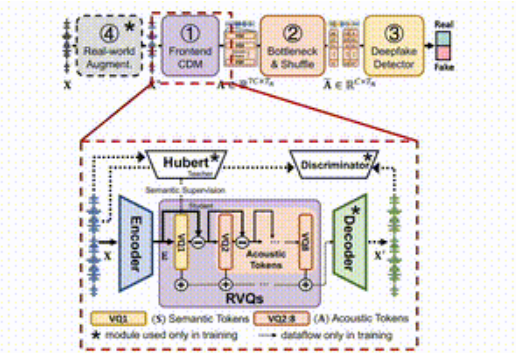
Ide SafeEar adalah untuk secara cerdik memisahkan informasi akustik dan semantik ucapan dengan merancang model terpisah berdasarkan codec audio saraf. Artinya SafeEar hanya mengandalkan informasi akustik untuk mendeteksi pemalsuan tanpa menyentuh keseluruhan konten suara, sehingga secara efektif dapat mencegah kebocoran privasi.
Keseluruhan kerangka ini dibagi menjadi empat bagian utama.
Pertama, model decoupling front-end bertanggung jawab untuk mengekstraksi fitur akustik target dari masukan ucapan; kedua, lapisan kemacetan dan lapisan kebingungan meningkatkan ketahanan terhadap pencurian konten dengan mengurangi dimensi dan mengganggu fitur akustik; ketiga, detektor pemalsuan menggunakan Transformer pengklasifikasi untuk menentukan apakah audio telah dipalsukan; dan terakhir, modul peningkatan lingkungan nyata semakin meningkatkan deteksi model dengan mensimulasikan lingkungan audio yang berbeda.
Pintu masuk proyek: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
Setelah melakukan percobaan pada beberapa kumpulan data benchmark, tim peneliti menemukan bahwa tingkat kesalahan SafeEar hanya 2,02%. Artinya sangat efektif dalam mengidentifikasi audio deepfake! Apalagi SafeEar juga mampu melindungi konten audio dalam lima bahasa sehingga sulit diurai oleh mesin atau telinga manusia, dengan tingkat kesalahan kata hingga 93,93%. Pada saat yang sama, melalui pengujian, para peneliti menemukan bahwa penyerang tidak dapat memulihkan konten suara yang dilindungi, hal ini menunjukkan keunggulan teknologi dalam perlindungan privasi.
Selain itu, tim SafeEar juga menyusun kumpulan data yang berisi 1,5 juta keping data audio multibahasa yang mencakup bahasa Inggris, China, Jerman, Prancis, dan Italia, yang memberikan informasi dasar yang kaya untuk deteksi dan penelitian pemalsuan suara di masa depan.
Peluncuran SafeEar tidak hanya menghadirkan solusi baru di bidang deteksi pemalsuan suara, namun juga membuka jalan untuk melindungi privasi suara pengguna.
Menyorot:
Kemunculan SafeEar memberikan senjata ampuh melawan teknologi pemalsuan suara, dan kinerjanya yang luar biasa dalam perlindungan privasi dan deteksi keamanan patut mendapat perhatian. Kami berharap SafeEar dapat ditingkatkan lebih lanjut di masa depan untuk melayani jaminan sosial dengan lebih baik.