음성 합성 기술의 급속한 발전으로 인해 음성 위조로 인한 보안 위험이 점점 더 커지고 있습니다. 이 문제를 해결하기 위해 Zhejiang University Intelligent System Security Laboratory와 Tsinghua University는 혁신적인 음성 위조 탐지 프레임워크인 SafeEar를 공동으로 개발했습니다. 이 프레임워크는 사용자 음성 프라이버시를 보호하는 동시에 효율적인 위조 탐지를 달성하여 정보 보안을 보장하는 새로운 솔루션을 제공합니다. 다운코드 편집자는 SafeEar의 고유성을 이해하도록 안내합니다.
오늘날의 신속한 음성 합성 및 변환 기술의 맥락에서 음성 위조는 점점 더 심각해지고 있으며 사용자의 개인 정보 보호 및 사회 보장에 상당한 위협을 가하고 있습니다. 최근 저장대학교 지능형 시스템 보안 연구소와 칭화대학교는 "SafeEar"라는 새로운 음성 위조 탐지 프레임워크를 공동으로 출시했습니다.
이 프레임워크는 음성 콘텐츠의 개인 정보를 보호하면서 효율적인 위조 탐지를 달성하고 음성 합성으로 인해 발생하는 문제에 완벽하게 대처하기 위해 노력하고 있습니다.
SafeEar의 아이디어는 신경 오디오 코덱을 기반으로 분리된 모델을 설계하여 음성의 음향 정보와 의미 정보를 교묘하게 분리하는 것입니다. 즉, SafeEar는 소리의 전체 내용을 건드리지 않고 위조 감지를 위해 음향 정보에만 의존하므로 개인정보 유출을 효과적으로 방지할 수 있습니다.
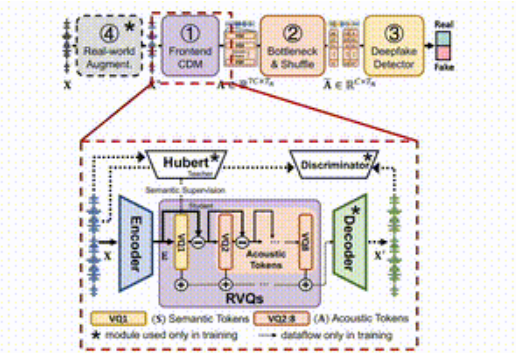
전체 프레임워크는 네 가지 주요 부분으로 나뉩니다.
첫째, 프런트엔드 디커플링 모델은 입력 음성에서 대상 음향 특징을 추출하는 역할을 합니다. 둘째, 병목 레이어와 혼란 레이어는 차원을 줄이고 음향 특징을 방해하여 콘텐츠 도난에 대한 저항력을 향상시킵니다. 세 번째, 위조 탐지기는 Transformer를 활용합니다. 오디오가 위조되었는지 여부를 결정하는 분류기, 최종적으로 실제 환경 강화 모듈은 다양한 오디오 환경을 시뮬레이션하여 모델 감지를 더욱 향상시킵니다.
프로젝트 입구: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
연구팀은 여러 벤치마크 데이터 세트를 실험한 결과 SafeEar의 오류율이 2.02%만큼 낮다는 것을 발견했습니다. 이는 딥페이크 오디오를 식별하는 데 매우 효과적이라는 것을 의미합니다. 또한 SafeEar는 5개 언어로 오디오 콘텐츠를 보호할 수 있어 최대 93.93%의 단어 오류율로 기계나 사람의 귀로 구문 분석하기 어렵습니다. 동시에 연구원들은 테스트를 통해 공격자가 보호된 음성 콘텐츠를 복구할 수 없다는 사실을 발견했으며 이는 개인 정보 보호에 있어 기술의 장점을 입증했습니다.
또한 SafeEar 팀은 영어, 중국어, 독일어, 프랑스어, 이탈리아어를 포함하는 150만 개의 다국어 오디오 데이터가 포함된 데이터 세트를 구축하여 향후 음성 위조 탐지 및 연구를 위한 풍부한 기본 정보를 제공합니다.
SafeEar의 출시는 음성 위조 탐지 분야에 새로운 솔루션을 제공할 뿐만 아니라 사용자의 음성 개인 정보를 보호할 수 있는 길을 열어줍니다.
가장 밝은 부분:
SafeEar의 등장은 음성위조 기술에 대항하는 강력한 무기를 제공하며, 개인정보 보호 및 보안탐지 분야에서 뛰어난 성능을 발휘할 수 있어 주목됩니다. 우리는 사회보장에 더 나은 서비스를 제공하기 위해 앞으로 더욱 개선되는 SafeEar를 기대합니다.