Con el rápido desarrollo de la tecnología de síntesis de voz, los riesgos de seguridad causados por la falsificación de voz se han vuelto cada vez más prominentes. Para abordar este desafío, el Laboratorio de Seguridad de Sistemas Inteligentes de la Universidad de Zhejiang y la Universidad de Tsinghua desarrollaron conjuntamente un marco innovador de detección de falsificación de voz: SafeEar. Este marco logra una detección eficiente de falsificaciones al tiempo que protege la privacidad de la voz del usuario, proporcionando una nueva solución para garantizar la seguridad de la información. El editor de Downcodes le llevará a comprender la singularidad de SafeEar.
En el contexto de la tecnología actual de conversión y síntesis rápida de voz, la falsificación de voz se está volviendo cada vez más grave y plantea amenazas considerables a la privacidad y la seguridad social de los usuarios. Recientemente, el Laboratorio de Seguridad de Sistemas Inteligentes de la Universidad de Zhejiang y la Universidad de Tsinghua lanzaron conjuntamente un nuevo marco de detección de falsificación de voz llamado "SafeEar".
Este marco se compromete a lograr una detección eficiente de falsificaciones al tiempo que protege la privacidad del contenido de voz y aborda plenamente los problemas causados por la síntesis de voz.
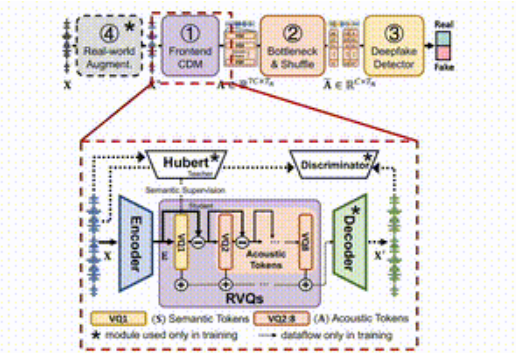
La idea de SafeEar es separar inteligentemente la información acústica y semántica del habla mediante el diseño de un modelo desacoplado basado en códecs de audio neuronales. Esto significa que SafeEar solo se basa en información acústica para la detección de falsificaciones sin tocar el contenido completo del sonido, lo que puede prevenir eficazmente las fugas de privacidad.
Todo el marco se divide en cuatro partes principales.
En primer lugar, el modelo de desacoplamiento frontal es responsable de extraer las características acústicas objetivo del habla de entrada; en segundo lugar, la capa de cuello de botella y la capa de confusión mejoran la resistencia al robo de contenido al reducir la dimensionalidad y alterar las características acústicas; en tercer lugar, el detector de falsificación utiliza Transformer; clasificador para determinar si el audio ha sido falsificado; finalmente, el módulo de mejora del entorno real mejora aún más la detección del modelo simulando diferentes entornos de audio;
Entrada del proyecto: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
Después de experimentos con múltiples conjuntos de datos de referencia, el equipo de investigación descubrió que la tasa de error de SafeEar era tan baja como 2,02%. Esto significa que es muy eficaz para identificar audio deepfake. Además, SafeEar también puede proteger contenido de audio en cinco idiomas, lo que dificulta que las máquinas o los oídos humanos lo analicen, con una tasa de error de palabras de hasta el 93,93 %. Al mismo tiempo, mediante pruebas, los investigadores descubrieron que los atacantes no podían recuperar el contenido de voz protegido, lo que demuestra las ventajas de la tecnología en la protección de la privacidad.
Además, el equipo de SafeEar también construyó un conjunto de datos que contiene 1,5 millones de datos de audio multilingües que cubren inglés, chino, alemán, francés e italiano, lo que proporciona información básica rica para futuras investigaciones y detección de falsificaciones de voz.
El lanzamiento de SafeEar no sólo aporta nuevas soluciones al campo de la detección de falsificaciones de voz, sino que también allana el camino para proteger la privacidad de la voz de los usuarios.
Destacar:
La aparición de SafeEar proporciona un arma poderosa contra la tecnología de falsificación de voz, y su excelente desempeño en protección de la privacidad y detección de seguridad merece atención. Esperamos que SafeEar siga mejorando en el futuro para servir mejor a la seguridad social.