Com o rápido desenvolvimento da tecnologia de síntese de voz, os riscos de segurança causados pela falsificação de voz tornaram-se cada vez mais proeminentes. Para enfrentar esse desafio, o Laboratório de Segurança de Sistemas Inteligentes da Universidade de Zhejiang e a Universidade de Tsinghua desenvolveram em conjunto uma estrutura inovadora de detecção de falsificação de voz - SafeEar. Esta estrutura alcança uma detecção eficiente de falsificações, ao mesmo tempo que protege a privacidade da voz do usuário, fornecendo uma nova solução para garantir a segurança da informação. O editor de Downcodes levará você a entender a singularidade do SafeEar.
No contexto da tecnologia actual de síntese e conversão rápida de voz, a falsificação de voz está a tornar-se cada vez mais grave, representando ameaças consideráveis à privacidade dos utilizadores e à segurança social. Recentemente, o Laboratório de Segurança de Sistemas Inteligentes da Universidade de Zhejiang e a Universidade de Tsinghua lançaram em conjunto uma nova estrutura de detecção de falsificação de voz chamada "SafeEar".
Esta estrutura está empenhada em alcançar uma detecção eficiente de falsificações, protegendo ao mesmo tempo a privacidade do conteúdo de voz e lidando totalmente com os problemas causados pela síntese de voz.
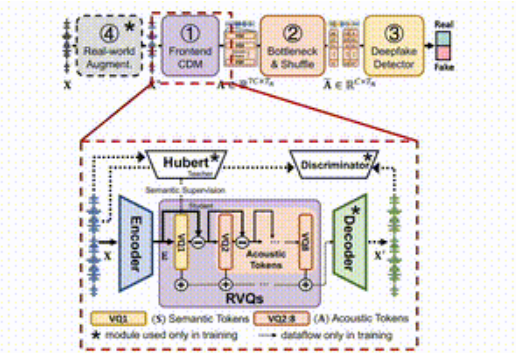
A ideia do SafeEar é separar de forma inteligente as informações acústicas e semânticas da fala, projetando um modelo desacoplado baseado em codecs de áudio neurais. Isso significa que o SafeEar depende apenas de informações acústicas para detecção de falsificações, sem tocar no conteúdo completo do som, o que pode prevenir efetivamente vazamentos de privacidade.
Toda a estrutura está dividida em quatro partes principais.
Primeiro, o modelo de desacoplamento front-end é responsável por extrair recursos acústicos alvo da fala de entrada; segundo, a camada de gargalo e a camada de confusão melhoram a resistência ao roubo de conteúdo, reduzindo a dimensionalidade e interrompendo os recursos acústicos; terceiro, o detector de falsificação utiliza o Transformer; classificador para determinar se o áudio foi forjado; finalmente, o módulo de aprimoramento de ambiente real melhora ainda mais a detecção do modelo, simulando diferentes ambientes de áudio;
Entrada do projeto: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
Após experimentos em vários conjuntos de dados de referência, a equipe de pesquisa descobriu que a taxa de erro do SafeEar era tão baixa quanto 2,02%. Isso significa que é muito eficaz na identificação de áudio deepfake. Além disso, o SafeEar também é capaz de proteger conteúdo de áudio em cinco idiomas, dificultando a análise por máquinas ou ouvidos humanos, com uma taxa de erro de palavras de até 93,93%. Ao mesmo tempo, através de testes, os investigadores descobriram que os atacantes não conseguiram recuperar o conteúdo de voz protegido, demonstrando as vantagens da tecnologia na proteção da privacidade.
Além disso, a equipe do SafeEar também construiu um conjunto de dados contendo 1,5 milhão de dados de áudio multilíngues, abrangendo inglês, chinês, alemão, francês e italiano, fornecendo informações básicas valiosas para futuras pesquisas e detecção de falsificações de voz.
O lançamento do SafeEar não só traz novas soluções para a área de detecção de falsificação de voz, mas também abre caminho para proteger a privacidade de voz dos usuários.
Destaque:
O surgimento do SafeEar fornece uma arma poderosa contra a tecnologia de falsificação de voz, e seu excelente desempenho na proteção da privacidade e na detecção de segurança merece atenção. Esperamos que o SafeEar seja melhorado ainda mais no futuro para melhor servir a seguridade social.