С быстрым развитием технологий синтеза речи риски безопасности, вызванные подделкой речи, становятся все более заметными. Чтобы решить эту проблему, Лаборатория интеллектуальной системной безопасности Университета Чжэцзян и Университет Цинхуа совместно разработали инновационную систему обнаружения подделки голоса — SafeEar. Эта платформа обеспечивает эффективное обнаружение подделок, одновременно защищая конфиденциальность голосовых сообщений пользователей, предоставляя новое решение для обеспечения информационной безопасности. Редактор Downcodes поможет вам понять уникальность SafeEar.
В контексте современных технологий быстрого синтеза и преобразования речи подделка голоса становится все более серьезной, создавая серьезные угрозы для конфиденциальности и социальной безопасности пользователей. Недавно Лаборатория безопасности интеллектуальных систем Университета Чжэцзян и Университета Цинхуа совместно выпустила новую систему обнаружения подделки голоса под названием «SafeEar».
Эта платформа призвана обеспечить эффективное обнаружение подделок, одновременно защищая конфиденциальность голосового контента и полностью справляясь с проблемами, вызванными синтезом речи.
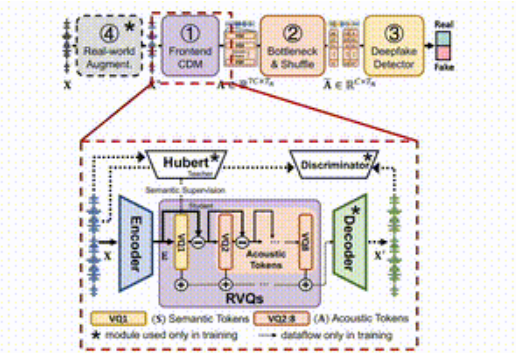
Идея SafeEar состоит в том, чтобы умело разделить акустическую и семантическую информацию речи, разработав разделенную модель на основе нейронных аудиокодеков. Это означает, что SafeEar полагается только на акустическую информацию для обнаружения подделки, не затрагивая полное содержание звука, что может эффективно предотвратить утечку конфиденциальной информации.
Вся структура разделена на четыре основные части.
Во-первых, внешняя модель развязки отвечает за извлечение целевых акустических характеристик из входной речи; во-вторых, уровень узкого места и уровень путаницы повышают устойчивость к краже контента за счет уменьшения размерности и нарушения акустических характеристик; в-третьих, детектор подделок использует Transformer; классификатор для определения того, был ли звук подделан; наконец, модуль улучшения реальной среды дополнительно улучшает обнаружение модели за счет моделирования различных звуковых сред;
Вход в проект: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
После экспериментов с несколькими наборами контрольных данных исследовательская группа обнаружила, что уровень ошибок SafeEar составляет всего 2,02%. Это означает, что он очень эффективен при выявлении поддельного аудио. Более того, SafeEar также способен защищать аудиоконтент на пяти языках, что затрудняет его анализ машинами или человеческими ушами, а уровень ошибок в словах достигает 93,93%. В то же время в ходе тестирования исследователи обнаружили, что злоумышленникам не удалось восстановить защищенный голосовой контент, что продемонстрировало преимущества технологии в защите конфиденциальности.
Кроме того, команда SafeEar также создала набор данных, содержащий 1,5 миллиона фрагментов многоязычных аудиоданных, охватывающих английский, китайский, немецкий, французский и итальянский языки, предоставляя богатую базовую информацию для будущего обнаружения и исследования подделок голоса.
Запуск SafeEar не только приносит новые решения в области обнаружения подделки голоса, но и открывает путь к защите конфиденциальности голоса пользователей.
Выделять:
Появление SafeEar представляет собой мощное оружие против технологии подделки голоса, а его выдающиеся характеристики в области защиты конфиденциальности и обнаружения безопасности заслуживают внимания. Мы с нетерпением ожидаем дальнейшего совершенствования SafeEar в будущем, чтобы лучше служить социальному обеспечению.