Mit der rasanten Entwicklung der Sprachsynthesetechnologie sind die durch Sprachfälschung verursachten Sicherheitsrisiken immer deutlicher geworden. Um dieser Herausforderung zu begegnen, haben das Intelligent System Security Laboratory der Zhejiang University und die Tsinghua University gemeinsam ein innovatives Framework zur Erkennung von Sprachfälschungen entwickelt – SafeEar. Dieses Framework ermöglicht eine effiziente Fälschungserkennung und schützt gleichzeitig die Privatsphäre der Benutzerstimme, was eine neue Lösung zur Gewährleistung der Informationssicherheit darstellt. Der Herausgeber von Downcodes wird Ihnen die Einzigartigkeit von SafeEar näher bringen.
Im Kontext der heutigen Technologie zur schnellen Sprachsynthese und -konvertierung wird Stimmfälschung immer schwerwiegender und stellt eine erhebliche Bedrohung für die Privatsphäre und die soziale Sicherheit der Benutzer dar. Kürzlich haben das Intelligent System Security Laboratory der Zhejiang University und der Tsinghua University gemeinsam ein neues Framework zur Erkennung von Sprachfälschungen namens „SafeEar“ veröffentlicht.
Dieses Framework zielt darauf ab, eine effiziente Fälschungserkennung zu erreichen und gleichzeitig die Privatsphäre von Sprachinhalten zu schützen und die durch die Sprachsynthese verursachten Probleme vollständig zu bewältigen.
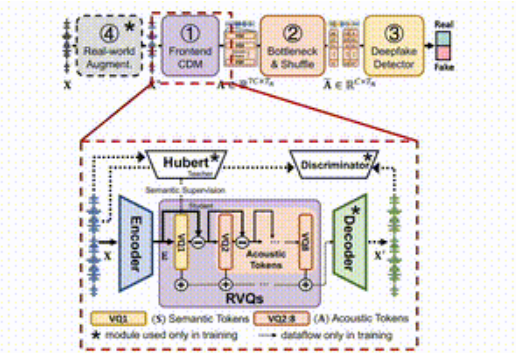
Die Idee von SafeEar besteht darin, die akustischen und semantischen Informationen der Sprache geschickt zu trennen, indem ein entkoppeltes Modell basierend auf neuronalen Audio-Codecs entworfen wird. Dies bedeutet, dass sich SafeEar zur Fälschungserkennung ausschließlich auf akustische Informationen verlässt, ohne den gesamten Inhalt des Tons zu berühren, wodurch Datenschutzlecks wirksam verhindert werden können.
Das gesamte Framework ist in vier Hauptteile unterteilt.
Erstens ist das Front-End-Entkopplungsmodell dafür verantwortlich, akustische Zielmerkmale aus der Eingabesprache zu extrahieren. Zweitens verbessern die Engpassschicht und die Verwirrungsschicht den Widerstand gegen Inhaltsdiebstahl, indem sie die Dimensionalität reduzieren und die akustischen Merkmale stören. Drittens nutzt der Fälschungsdetektor Transformer Klassifikator zur Bestimmung, ob das Audio gefälscht wurde; schließlich verbessert das Modul zur Verbesserung der realen Umgebung die Modellerkennung weiter, indem es verschiedene Audioumgebungen simuliert.
Projekteingang: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
Nach Experimenten mit mehreren Benchmark-Datensätzen stellte das Forschungsteam fest, dass die Fehlerquote von SafeEar nur 2,02 % betrug. Dies bedeutet, dass es Deepfake-Audio sehr effektiv erkennt! Darüber hinaus ist SafeEar auch in der Lage, Audioinhalte in fünf Sprachen zu schützen, was die Analyse durch Maschinen oder menschliche Ohren erschwert, mit einer Wortfehlerrate von bis zu 93,93 %. Gleichzeitig stellten die Forscher durch Tests fest, dass Angreifer die geschützten Sprachinhalte nicht wiederherstellen konnten, was die Vorteile der Technologie beim Schutz der Privatsphäre unter Beweis stellte.
Darüber hinaus erstellte das SafeEar-Team einen Datensatz mit 1,5 Millionen mehrsprachigen Audiodaten, die Englisch, Chinesisch, Deutsch, Französisch und Italienisch abdecken und umfassende Basisinformationen für die künftige Erkennung und Forschung von Stimmfälschungen liefern.
Die Einführung von SafeEar bringt nicht nur neue Lösungen im Bereich der Sprachfälschungserkennung, sondern ebnet auch den Weg zum Schutz der Privatsphäre der Benutzer.
Highlight:
Das Aufkommen von SafeEar stellt eine leistungsstarke Waffe gegen Sprachfälschungstechnologie dar, und seine herausragende Leistung beim Schutz der Privatsphäre und bei der Sicherheitserkennung verdient Aufmerksamkeit. Wir freuen uns darauf, SafeEar in Zukunft weiter zu verbessern, um der sozialen Sicherheit besser zu dienen.