مع التطور السريع لتكنولوجيا تركيب الكلام، أصبحت المخاطر الأمنية الناجمة عن تزوير الكلام بارزة بشكل متزايد. ولمواجهة هذا التحدي، قام مختبر أمن النظام الذكي بجامعة تشجيانغ وجامعة تسينغهوا بتطوير إطار عمل مبتكر للكشف عن تزوير الصوت - SafeEar. يحقق هذا الإطار اكتشافًا فعالاً للتزوير مع حماية خصوصية صوت المستخدم، مما يوفر حلاً جديدًا لضمان أمن المعلومات. سوف يأخذك محرر Downcodes إلى فهم تفرد SafeEar.
في سياق تكنولوجيا التوليف والتحويل السريع للكلام اليوم، أصبح تزوير الصوت خطيرًا بشكل متزايد، مما يشكل تهديدات كبيرة لخصوصية المستخدم والأمن الاجتماعي. في الآونة الأخيرة، أصدر مختبر أمان النظام الذكي بجامعة تشجيانغ وجامعة تسينغهوا بشكل مشترك إطارًا جديدًا للكشف عن تزوير الصوت يسمى "SafeEar".
يلتزم هذا الإطار بتحقيق اكتشاف فعال للتزوير مع حماية خصوصية المحتوى الصوتي والتعامل بشكل كامل مع المشكلات الناجمة عن تركيب الكلام.
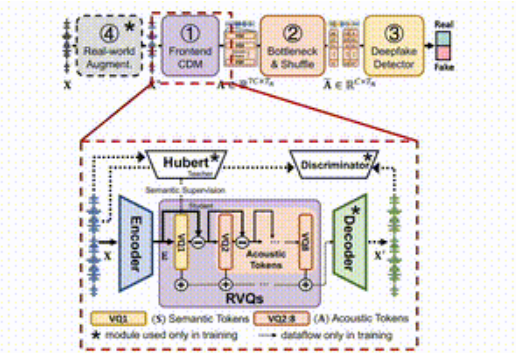
تتمثل فكرة SafeEar في الفصل الذكي بين المعلومات الصوتية والدلالية للكلام من خلال تصميم نموذج منفصل يعتمد على برامج الترميز الصوتية العصبية. وهذا يعني أن SafeEar يعتمد فقط على المعلومات الصوتية لاكتشاف التزوير دون لمس المحتوى الكامل للصوت، وهو ما يمكن أن يمنع تسرب الخصوصية بشكل فعال.
ينقسم الإطار بأكمله إلى أربعة أجزاء رئيسية.
أولاً، يكون نموذج فصل الواجهة الأمامية مسؤولاً عن استخراج الميزات الصوتية المستهدفة من خطاب الإدخال؛ وثانيًا، تعمل طبقة عنق الزجاجة وطبقة الارتباك على تحسين مقاومة سرقة المحتوى عن طريق تقليل الأبعاد وتعطيل الميزات الصوتية. ثالثًا، يستخدم كاشف التزوير المحول والمصنف لتحديد ما إذا كان الصوت قد تم تزويره، وأخيرًا، تعمل وحدة تحسين البيئة الحقيقية على تحسين اكتشاف النموذج من خلال محاكاة بيئات صوتية مختلفة.
مدخل المشروع: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
وبعد إجراء تجارب على مجموعات بيانات مرجعية متعددة، وجد فريق البحث أن معدل خطأ SafeEar كان منخفضًا يصل إلى 2.02%. وهذا يعني أنه فعال للغاية في التعرف على الصوت المزيف العميق! علاوة على ذلك، فإن SafeEar قادر أيضًا على حماية المحتوى الصوتي بخمس لغات، مما يجعل من الصعب تحليله بواسطة الآلات أو الأذن البشرية، مع معدل خطأ في الكلمات يصل إلى 93.93%. وفي الوقت نفسه، ومن خلال الاختبار، وجد الباحثون أن المهاجمين لم يتمكنوا من استعادة المحتوى الصوتي المحمي، مما يدل على مزايا التكنولوجيا في حماية الخصوصية.
بالإضافة إلى ذلك، قام فريق SafeEar أيضًا بإنشاء مجموعة بيانات تحتوي على 1.5 مليون قطعة من البيانات الصوتية متعددة اللغات التي تغطي الإنجليزية والصينية والألمانية والفرنسية والإيطالية، مما يوفر معلومات أساسية غنية للكشف عن تزوير الصوت وإجراء الأبحاث في المستقبل.
إن إطلاق SafeEar لا يقدم حلولاً جديدة في مجال كشف تزوير الصوت فحسب، بل يمهد الطريق أيضًا لحماية خصوصية صوت المستخدمين.
تسليط الضوء على:
يوفر ظهور SafeEar سلاحًا قويًا ضد تقنية تزوير الصوت، كما أن أدائها المتميز في حماية الخصوصية والكشف الأمني يستحق الاهتمام. ونحن نتطلع إلى مزيد من التحسين في SafeEar في المستقبل لخدمة الضمان الاجتماعي بشكل أفضل.