Avec le développement rapide de la technologie de synthèse vocale, les risques de sécurité causés par la contrefaçon de parole sont devenus de plus en plus importants. Pour relever ce défi, le laboratoire de sécurité des systèmes intelligents de l'université du Zhejiang et l'université de Tsinghua ont développé conjointement un cadre innovant de détection de contrefaçon vocale : SafeEar. Ce cadre permet une détection efficace des contrefaçons tout en protégeant la confidentialité de la voix des utilisateurs, offrant ainsi une nouvelle solution pour garantir la sécurité des informations. L'éditeur de Downcodes vous fera comprendre le caractère unique de SafeEar.
Dans le contexte actuel de technologie rapide de synthèse et de conversion de la parole, la contrefaçon de voix devient de plus en plus grave, posant des menaces considérables à la vie privée des utilisateurs et à la sécurité sociale. Récemment, le laboratoire de sécurité des systèmes intelligents de l'université du Zhejiang et de l'université de Tsinghua ont publié conjointement un nouveau cadre de détection de contrefaçon vocale appelé « SafeEar ».
Ce cadre s'engage à parvenir à une détection efficace des contrefaçons tout en protégeant la confidentialité du contenu vocal et en résolvant pleinement les problèmes causés par la synthèse vocale.
L'idée de SafeEar est de séparer intelligemment les informations acoustiques et sémantiques de la parole en concevant un modèle découplé basé sur des codecs audio neuronaux. Cela signifie que SafeEar s'appuie uniquement sur les informations acoustiques pour détecter les contrefaçons sans toucher au contenu complet du son, ce qui peut efficacement empêcher les fuites de confidentialité.
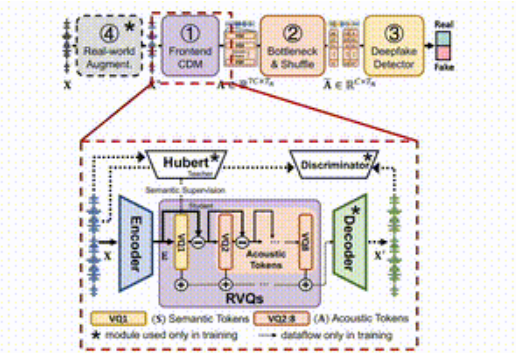
L'ensemble du cadre est divisé en quatre parties principales.
Premièrement, le modèle de découplage frontal est chargé d'extraire les caractéristiques acoustiques cibles de la parole d'entrée ; deuxièmement, la couche de goulot d'étranglement et la couche de confusion améliorent la résistance au vol de contenu en réduisant la dimensionnalité et en perturbant les caractéristiques acoustiques. Troisièmement, le détecteur de contrefaçon utilise Transformer ; classificateur pour déterminer si l'audio a été falsifié ; enfin, le module d'amélioration de l'environnement réel améliore encore la détection du modèle en simulant différents environnements audio.
Entrée du projet : https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
Après des expériences sur plusieurs ensembles de données de référence, l'équipe de recherche a constaté que le taux d'erreur de SafeEar était aussi faible que 2,02 %. Cela signifie qu'il est très efficace pour identifier les deepfakes audio. De plus, SafeEar est également capable de protéger le contenu audio en cinq langues, ce qui le rend difficile à analyser par les machines ou les oreilles humaines, avec un taux d'erreur de mot allant jusqu'à 93,93 % ! Dans le même temps, grâce à des tests, les chercheurs ont constaté que les attaquants étaient incapables de récupérer le contenu vocal protégé, démontrant ainsi les avantages de la technologie en matière de protection de la vie privée.
En outre, l'équipe SafeEar a également construit un ensemble de données contenant 1,5 million de données audio multilingues couvrant l'anglais, le chinois, l'allemand, le français et l'italien, fournissant ainsi de riches informations de base pour la détection et la recherche futures de falsifications vocales.
Le lancement de SafeEar apporte non seulement de nouvelles solutions dans le domaine de la détection des falsifications vocales, mais ouvre également la voie à la protection de la confidentialité vocale des utilisateurs.
Souligner:
L’émergence de SafeEar constitue une arme puissante contre la technologie de contrefaçon vocale, et ses performances exceptionnelles en matière de protection de la vie privée et de détection de sécurité méritent notre attention. Nous espérons que SafeEar sera encore amélioré à l'avenir pour mieux servir la sécurité sociale.