With the rapid development of speech synthesis technology, the security risks caused by speech forgery have become increasingly prominent. To address this challenge, Zhejiang University Intelligent System Security Laboratory and Tsinghua University jointly developed an innovative voice forgery detection framework - SafeEar. This framework achieves efficient forgery detection while protecting user voice privacy, providing a new solution for ensuring information security. The editor of Downcodes will take you to understand the uniqueness of SafeEar.
In the context of today's rapid speech synthesis and conversion technology, voice forgery is becoming increasingly serious, posing considerable threats to user privacy and social security. Recently, the Intelligent System Security Laboratory of Zhejiang University and Tsinghua University jointly released a new voice forgery detection framework called "SafeEar".
This framework is committed to achieving efficient forgery detection while protecting the privacy of voice content, and fully coping with the problems caused by speech synthesis.
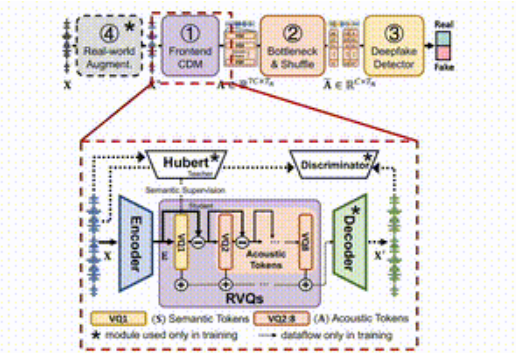
The idea of SafeEar is to cleverly separate the acoustic and semantic information of speech by designing a decoupled model based on neural audio codecs. This means that SafeEar only relies on acoustic information for forgery detection without touching the complete content of the sound, which can effectively prevent privacy leaks.
The entire framework is divided into four main parts.
First, the front-end decoupling model is responsible for extracting target acoustic features from the input speech; second, the bottleneck layer and confusion layer improve the resistance to content theft by reducing dimensionality and disrupting the acoustic features; third, the forgery detector utilizes Transformer classifier to determine whether the audio has been forged; finally, the real environment enhancement module further improves model detection by simulating different audio environments.
Project entrance: https://github.com/LetterLiGo/SafeEar?tab=readme-ov-file
After experiments on multiple benchmark data sets, the research team found that SafeEar's error rate was as low as 2.02%. This means that it is very effective at identifying deepfake audio! Moreover, SafeEar is also able to protect audio content in five languages, making it difficult to be parsed by machines or human ears, with a word error rate of up to 93.93%. At the same time, through testing, the researchers found that attackers were unable to recover the protected voice content, demonstrating the technology's advantages in privacy protection.
In addition, the SafeEar team also constructed a data set containing 1.5 million pieces of multi-lingual audio data covering English, Chinese, German, French and Italian, providing rich basic information for future voice forgery detection and research.
The launch of SafeEar not only brings new solutions to the field of voice forgery detection, but also paves the way to protect users' voice privacy.
Highlight:
The emergence of SafeEar provides a powerful weapon against voice forgery technology, and its outstanding performance in privacy protection and security detection deserves attention. We look forward to SafeEar being further improved in the future to better serve social security.