北京大學和阿里巴巴的研究團隊聯合發布了全新的數學能力評測基準Omni-MATH,用於評估大型語言模型在奧林匹克數學競賽級別的推理能力。該基準包含4428道涵蓋33個以上數學子領域的競賽級題目,難度等級從奧林匹克預備級別到頂級競賽級別不等,並透過人工驗證確保答案的高可靠性。 Omni-MATH的推出,為AI在高階數學領域的潛力探索提供了新的標準和途徑,也為評估大型語言模型的數學推理能力提供了更全面的工具。 Downcodes小編將為您詳細解讀Omni-MATH的獨特設計、評測體係以及創新的評測方法。
隨著OpenAI的GPT-4在傳統數學評測中屢創佳績,北京大學和阿里巴巴的研究團隊聯手推出了一個全新的評測基準——Omni-MATH,旨在評估大型語言模型在奧林匹克數學競賽級別的推理能力。這項舉措不僅為AI數學能力的評估提供了新標準,也為探索AI在高級數學領域的潛力開闢了新途徑。
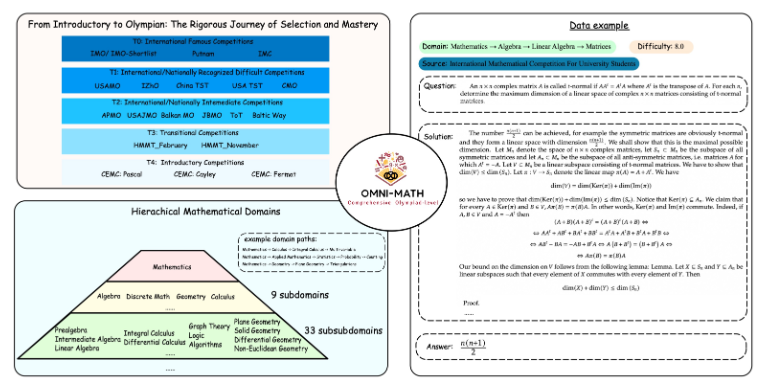
Omni-MATH的獨特設計
Omni-MATH評測庫包含4,428個競賽等級的數學問題,涵蓋33個以上的數學子領域,難度分為10個不同等級。其特點包括:
高可靠性:所有題目均來自各種數學競賽和論壇,答案經過人工驗證。
廣泛涵蓋:從奧林匹克預備等級(T4)到頂級奧林匹克數學競賽(T0),如IMO、IMC和普特南等。
多樣性考量:透過基於GPT-4和其他評測模型的評價方式,優化了答案多樣性的問題。
在最新的排行榜上,除GPT-4滿血版外,表現突出的包括:
GPT-4-mini:平均分數比GPT-4-preview高出約8%
Qwen2-MATH-72b:超過了GPT-4-turbo的成績
這些結果顯示,即使是小型模型,在特定能力上也可能有出色表現。
評測體系的深度與廣度
Omni-MATH的設計充分考慮了國際數學競賽的選拔流程和難度層級:
參考英國和美國等國的奧數選拔體系
涵蓋從數論、代數到幾何等多個數學領域
資料來源包括各類比賽主題、解析及著名數學網站的論壇內容
創新的評測方法
研究團隊開發了Omni-Judge開源答案驗證器,利用微調過的Llama3-Instruct模型,能快速判斷模型輸出與標準答案的一致性。這種方法在確保95%一致率的同時,也為複雜數學問題的評測提供了便利解決方案。
Omni-MATH的推出不僅是AI數學能力的全新挑戰,也為未來AI在高階數學領域的應用與發展提供了重要的評估工具。隨著AI技術的不斷進步,我們或許能在不久的將來,見證AI在奧林匹克數學競賽中的驚人表現。
專案網址:https://github.com/KbsdJames/Omni-MATH/
總而言之,Omni-MATH的出現標誌著AI數學能力評估邁向新的高度,它為研究人員和開發者提供了寶貴的工具和數據,推動著AI在數學領域不斷發展。未來,隨著Omni-MATH的不斷改進和更新,相信它將在AI數學領域發揮更大的作用。