베이징 대학교와 알리바바의 연구팀은 올림피아드 수학 대회 수준에서 대규모 언어 모델의 추론 능력을 평가하는 데 사용되는 새로운 수학 능력 평가 벤치마크인 Omni-MATH를 공동으로 출시했습니다. 벤치마크에는 수학의 33개 하위 분야를 다루는 4,428개의 경쟁 수준 질문이 포함되어 있으며, 난이도는 올림픽 준비 수준부터 최고 경쟁 수준까지이며 답변의 높은 신뢰성을 보장하기 위해 수동으로 검증됩니다. Omni-MATH의 출시는 고급 수학 분야에서 AI의 잠재력을 탐색할 수 있는 새로운 표준과 방법을 제공하며, 대규모 언어 모델의 수학적 추론 기능을 평가하기 위한 보다 포괄적인 도구도 제공합니다. Downcodes의 편집자는 Omni-MATH의 독특한 디자인, 평가 시스템 및 혁신적인 평가 방법을 자세히 설명합니다.
OpenAI의 GPT-4가 전통적인 수학 평가에서 계속해서 좋은 결과를 거두자 북경대학교와 알리바바 연구팀은 올림피아드 수학 대회 수준에서 대규모 언어 모델의 성능을 평가하기 위해 설계된 새로운 평가 벤치마크인 Omni-MATH를 공동으로 출시했습니다. 추론 기술. 이 이니셔티브는 AI 수학적 능력 평가를 위한 새로운 표준을 제공할 뿐만 아니라 고급 수학 분야에서 AI의 잠재력을 탐색할 수 있는 새로운 방법을 열어줍니다.
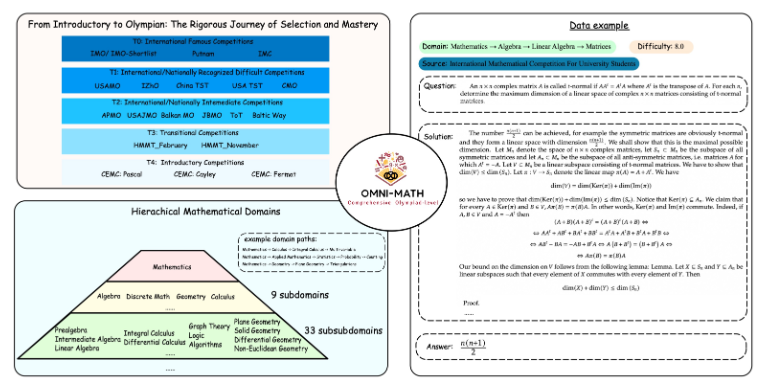
Omni-MATH의 독특한 디자인
Omni-MATH 평가 라이브러리에는 10가지 난이도 수준의 33개 이상의 수학 하위 필드를 다루는 4,428개의 경쟁 수준 수학 문제가 포함되어 있습니다. 기능은 다음과 같습니다:
높은 신뢰성: 모든 질문은 다양한 수학 대회 및 포럼에서 나온 것이며 답변은 수동으로 확인됩니다.
광범위한 적용 범위: 올림피아드 준비 수준(T4)부터 IMO, IMC, Putnam 등과 같은 최고 올림피아드 수학 대회(T0)까지.
다양성 고려: 답변 다양성 문제는 GPT-4 및 기타 평가 모델을 기반으로 한 평가 방법을 통해 최적화됩니다.
최신 순위에서 GPT-4 순수 버전 외에도 뛰어난 성과를 낸 선수는 다음과 같습니다.
GPT-4-mini: 평균 점수가 GPT-4-미리보기보다 약 8% 더 높습니다.
Qwen2-MATH-72b: GPT-4-터보의 결과를 능가함
이러한 결과는 작은 모델이라도 특정 기능에서 좋은 성능을 발휘할 수 있음을 보여줍니다.
평가 시스템의 깊이와 폭
Omni-MATH의 디자인은 국제 수학 대회의 선발 과정과 난이도를 충분히 고려합니다.
영국, 미국 등의 국가의 수학 올림피아드 선발 시스템을 참고하세요.
정수론부터 대수학, 기하학까지 수학의 다양한 영역을 다룹니다.
데이터 소스에는 유명 수학 웹사이트의 다양한 경쟁 질문, 분석 및 포럼 콘텐츠가 포함됩니다.
혁신적인 평가 방법
연구팀은 미세 조정된 Llama3-Instruct 모델을 사용하여 모델 출력과 표준 답변 간의 일관성을 신속하게 판단하는 Omni-Judge 오픈 소스 답변 검증기를 개발했습니다. 이 방법은 95%의 일관성 비율을 보장할 뿐만 아니라 복잡한 수학적 문제를 평가하는 데 편리한 솔루션을 제공합니다.
Omni-MATH의 출시는 AI의 수학적 역량에 대한 새로운 도전일 뿐만 아니라, 고급 수학 분야에서 AI의 향후 적용 및 개발을 위한 중요한 평가 도구를 제공합니다. AI 기술이 지속적으로 발전함에 따라 우리는 머지않아 수학올림피아드 대회에서 AI의 놀라운 성능을 목격할 수 있을 것이다.
프로젝트 주소: https://github.com/KbsdJames/Omni-MATH/
전체적으로 Omni-MATH의 출현은 AI 수학적 능력 평가에 있어 새로운 차원을 의미합니다. 이는 연구원과 개발자에게 귀중한 도구와 데이터를 제공하고 수학 분야에서 AI의 지속적인 개발을 촉진합니다. 앞으로도 Omni-MATH는 계속해서 개선되고 업데이트되면서 AI 수학 분야에서 더 큰 역할을 하리라 믿습니다.