أصدرت فرق بحثية من جامعة بكين وعلي بابا بشكل مشترك معيارًا جديدًا لتقييم القدرات الرياضية Omni-MATH، والذي يُستخدم لتقييم القدرات الاستدلالية لنماذج اللغات الكبيرة على مستوى مسابقة الأولمبياد الرياضي. ويحتوي المعيار على 4428 سؤالاً على مستوى المنافسة تغطي أكثر من 33 مجالًا فرعيًا للرياضيات، مع مستويات صعوبة تتراوح من المستوى الإعدادي الأولمبي إلى أعلى مستوى للمنافسة، ويتم التحقق منه يدويًا لضمان موثوقية عالية للإجابات. يوفر إطلاق Omni-MATH معايير وطرق جديدة لاستكشاف إمكانات الذكاء الاصطناعي في مجال الرياضيات المتقدمة، كما يوفر أداة أكثر شمولاً لتقييم قدرات التفكير الرياضي لنماذج اللغات الكبيرة. سيشرح محرر Downcodes بالتفصيل التصميم الفريد ونظام التقييم وطرق التقييم المبتكرة لـ Omni-MATH.
نظرًا لأن GPT-4 الخاص بـ OpenAI حقق مرارًا وتكرارًا نتائج رائعة في تقييمات الرياضيات التقليدية، فقد أطلقت فرق البحث من جامعة بكين وعلي بابا بشكل مشترك معيار تقييم جديد - Omni-MATH، المصمم لتقييم أداء نماذج اللغات الكبيرة على مستوى مسابقة الأولمبياد الرياضي. مهارات التفكير. ولا توفر هذه المبادرة معيارًا جديدًا لتقييم القدرات الرياضية للذكاء الاصطناعي فحسب، بل تفتح أيضًا طريقة جديدة لاستكشاف إمكانات الذكاء الاصطناعي في مجال الرياضيات المتقدمة.
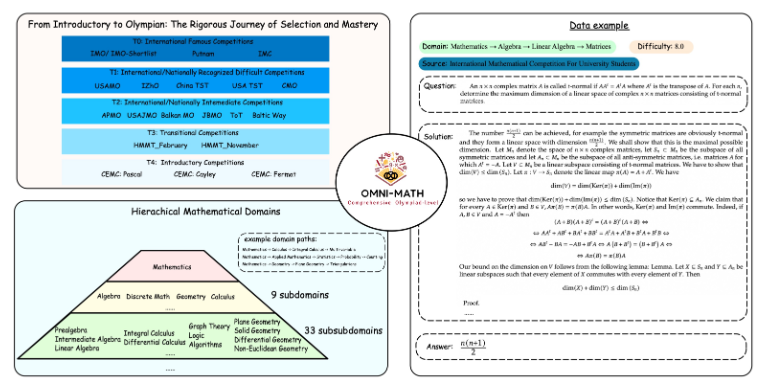
تصميم Omni-MATH الفريد
تحتوي مكتبة تقييم Omni-MATH على 4,428 سؤال رياضي على مستوى المنافسة، تغطي أكثر من 33 مجالًا فرعيًا للرياضيات، مع 10 مستويات مختلفة من الصعوبة. تشمل الميزات:
موثوقية عالية: جميع الأسئلة تأتي من مسابقات ومنتديات الرياضيات المختلفة، ويتم التحقق من الإجابات يدويًا.
تغطية واسعة: من المستوى التحضيري للأولمبياد (T4) إلى أعلى مسابقات الرياضيات في الأولمبياد (T0) مثل IMO وIMC وPutnam وما إلى ذلك.
اعتبارات التنوع: تم تحسين مسألة تنوع الإجابات من خلال طرق التقييم المستندة إلى GPT-4 ونماذج التقييم الأخرى.
في أحدث التصنيفات، بالإضافة إلى إصدار GPT-4 الكامل، يشمل الأداء المتميز ما يلي:
GPT-4-mini: متوسط النتيجة أعلى بحوالي 8% من معاينة GPT-4
Qwen2-MATH-72b: تجاوز نتائج GPT-4-turbo
تظهر هذه النتائج أنه حتى النماذج الصغيرة يمكن أن تؤدي أداءً جيدًا فيما يتعلق بقدرات محددة.
عمق واتساع نظام التقييم
يأخذ تصميم Omni-MATH في الاعتبار الكامل عملية الاختيار ومستوى الصعوبة في مسابقات الرياضيات الدولية:
راجع أنظمة اختيار أولمبياد الرياضيات في دول مثل المملكة المتحدة والولايات المتحدة.
يغطي العديد من مجالات الرياضيات من نظرية الأعداد إلى الجبر إلى الهندسة
تتضمن مصادر البيانات أسئلة المنافسة المختلفة والتحليلات ومحتوى المنتديات على مواقع الرياضيات الشهيرة
أساليب التقييم المبتكرة
قام فريق البحث بتطوير أداة التحقق من الإجابات مفتوحة المصدر Omni-Judge، والتي تستخدم نموذج Llama3-Instruct المضبوط بدقة لتحديد الاتساق بين مخرجات النموذج والإجابة القياسية بسرعة. لا تضمن هذه الطريقة معدل اتساق يبلغ 95% فحسب، بل توفر أيضًا حلاً مناسبًا لتقييم المشكلات الرياضية المعقدة.
لا يعد إطلاق Omni-MATH تحديًا جديدًا لقدرات الذكاء الاصطناعي الرياضية فحسب، بل يوفر أيضًا أداة تقييم مهمة للتطبيق المستقبلي وتطوير الذكاء الاصطناعي في مجال الرياضيات المتقدمة. ومع التقدم المستمر في تكنولوجيا الذكاء الاصطناعي، قد نتمكن من رؤية الأداء المذهل للذكاء الاصطناعي في مسابقة أولمبياد الرياضيات في المستقبل القريب.
عنوان المشروع: https://github.com/KbsdJames/Omni-MATH/
بشكل عام، يمثل ظهور Omni-MATH ارتفاعًا جديدًا في تقييم القدرة الرياضية للذكاء الاصطناعي، فهو يوفر للباحثين والمطورين أدوات وبيانات قيمة، ويعزز التطوير المستمر للذكاء الاصطناعي في مجال الرياضيات. في المستقبل، مع استمرار تحسين Omni-MATH وتحديثه، أعتقد أنه سيلعب دورًا أكبر في مجال رياضيات الذكاء الاصطناعي.