Исследовательские группы из Пекинского университета и Alibaba совместно выпустили новый тест для оценки математических способностей Omni-MATH, который используется для оценки способностей к рассуждению больших языковых моделей на уровне олимпиадных математических соревнований. Тест содержит 4428 вопросов соревновательного уровня, охватывающих более 33 подобластей математики, с уровнями сложности от олимпийского подготовительного уровня до высшего соревновательного уровня, и проверяется вручную, чтобы обеспечить высокую надежность ответов. Запуск Omni-MATH предоставляет новые стандарты и способы изучения потенциала ИИ в области высшей математики, а также предоставляет более комплексный инструмент для оценки возможностей математического рассуждения больших языковых моделей. Редактор Downcodes подробно объяснит уникальный дизайн, систему оценки и инновационные методы оценки Omni-MATH.
Поскольку GPT-4 компании OpenAI неоднократно добивался отличных результатов в традиционных математических оценках, исследовательские группы из Пекинского университета и Alibaba совместно запустили новый тест оценки — Omni-MATH, предназначенный для оценки производительности больших языковых моделей на уровне олимпиадных математических соревнований. Умение рассуждать. Эта инициатива не только обеспечивает новый стандарт оценки математических способностей ИИ, но и открывает новый способ изучения потенциала ИИ в области высшей математики.
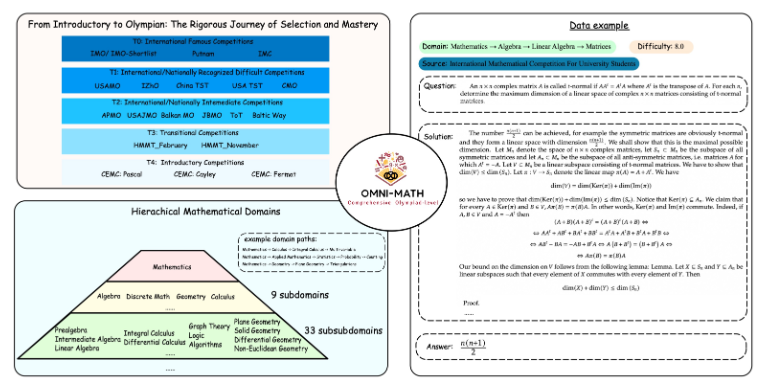
Уникальный дизайн Omni-MATH
Оценочная библиотека Omni-MATH содержит 4428 вопросов по математике соревновательного уровня, охватывающих более 33 подполей математики и 10 различных уровней сложности. Особенности включают в себя:
Высокая надежность: все вопросы поступают с различных математических олимпиад и форумов, а ответы проверяются вручную.
Широкий охват: от подготовительного уровня к олимпиадам (T4) до высших олимпиадных соревнований по математике (T0), таких как IMO, IMC и Putnam и т. д.
Учет разнообразия. Вопрос разнообразия ответов оптимизируется с помощью методов оценки, основанных на GPT-4 и других моделях оценки.
В последних рейтингах, помимо полнокровной версии GPT-4, выдающимися исполнителями стали:
GPT-4-mini: средний балл примерно на 8% выше, чем у GPT-4-preview.
Qwen2-MATH-72b: Превзошел результаты GPT-4-турбо
Эти результаты показывают, что даже небольшие модели могут хорошо работать с определенными возможностями.
Глубина и широта системы оценки
При разработке Omni-MATH полностью учитывается процесс отбора и уровень сложности международных соревнований по математике:
Обратитесь к системам отбора на математические олимпиады в таких странах, как Великобритания и США.
Охватывает многие области математики: от теории чисел до алгебры и геометрии.
Источники данных включают различные конкурсные вопросы, анализ и контент форумов на известных математических сайтах.
Инновационные методы оценки
Исследовательская группа разработала верификатор ответов с открытым исходным кодом Omni-Judge, который использует точно настроенную модель Llama3-Instruct для быстрого определения соответствия между выходными данными модели и стандартным ответом. Этот метод не только обеспечивает степень согласованности 95%, но также обеспечивает удобное решение для оценки сложных математических задач.
Запуск Omni-MATH — это не только новый вызов математическим возможностям ИИ, но и важный инструмент оценки будущего применения и развития ИИ в области высшей математики. Благодаря постоянному развитию технологий искусственного интеллекта мы, возможно, сможем стать свидетелями удивительных результатов искусственного интеллекта на соревнованиях по математической олимпиаде в ближайшем будущем.
Адрес проекта: https://github.com/KbsdJames/Omni-MATH/
В целом, появление Omni-MATH знаменует новую высоту в оценке математических способностей ИИ. Он предоставляет исследователям и разработчикам ценные инструменты и данные и способствует постоянному развитию ИИ в области математики. В будущем, поскольку Omni-MATH будет продолжать совершенствоваться и обновляться, я считаю, что он будет играть более важную роль в области математики ИИ.