北京大学とアリババの研究チームは共同で、オリンピック数学コンクールレベルで大規模言語モデルの推論能力を評価するために使用される、新しい数学能力評価ベンチマーク「Omni-MATH」を発表した。このベンチマークには、数学の 33 サブ分野以上をカバーする競技レベルの問題が 4,428 問含まれており、難易度はオリンピック準備レベルからトップ競技レベルまであり、回答の高い信頼性を確保するために手動で検証されています。 Omni-MATH の開始により、高度な数学の分野で AI の可能性を探求するための新しい標準と方法が提供され、また、大規模な言語モデルの数学的推論機能を評価するためのより包括的なツールも提供されます。 Omni-MATH の独自の設計、評価システム、革新的な評価手法について、Downcodes 編集者が詳しく解説します。
OpenAI の GPT-4 が伝統的な数学評価で繰り返し優れた結果を達成していることから、北京大学とアリババの研究チームは共同で、オリンピック数学競技会レベルで大規模言語モデルのパフォーマンスを評価するように設計された新しい評価ベンチマークである Omni-MATH を立ち上げました。推理スキル。この取り組みは、AI の数学的能力を評価するための新しい基準を提供するだけでなく、高度な数学の分野で AI の可能性を探求する新しい方法を開きます。
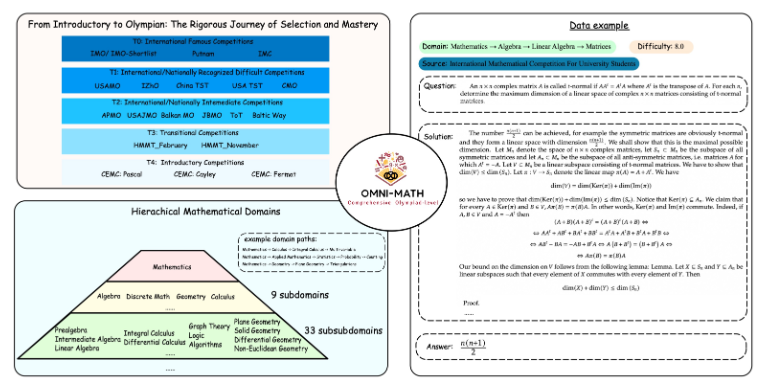
Omni-MATH のユニークなデザイン
Omni-MATH 評価ライブラリには、33 を超える数学サブ分野をカバーする、10 の異なる難易度の競技レベルの数学の問題が 4,428 問含まれています。特徴は次のとおりです。
高い信頼性: すべての質問はさまざまな数学コンテストやフォーラムからのものであり、回答は手動で検証されます。
幅広い範囲: オリンピック準備レベル (T4) から、IMO、IMC、パトナムなどのオリンピックのトップ数学コンテスト (T0) まで。
多様性への配慮:GPT-4などの評価モデルに基づく評価手法により、質問の回答多様性を最適化します。
最新のランキングでは、GPT-4 の完全版に加えて、優れたパフォーマンスを示したものが次のとおりです。
GPT-4-mini: 平均スコアは GPT-4-preview より約 8% 高い
Qwen2-MATH-72b: GPT-4-turbo の結果を超えました
これらの結果は、小規模なモデルでも特定の機能で良好なパフォーマンスを発揮できることを示しています。
評価制度の深さと幅広さ
Omni-MATH の設計は、国際的な数学コンテストの選考プロセスと難易度を十分に考慮しています。
英国や米国などの数学オリンピックの選考システムを参照してください。
数論から代数、幾何学まで数学の多くの分野をカバー
データ ソースには、有名な数学 Web サイトのさまざまなコンテストの問題、分析、フォーラム コンテンツが含まれます。
革新的な評価方法
研究チームは、Omni-Judge オープンソース回答検証ツールを開発しました。これは、微調整された Llama3-Instruct モデルを使用して、モデル出力と標準回答の間の一貫性を迅速に判断します。この方法は、95% の一貫性率を保証するだけでなく、複雑な数学的問題を評価するための便利なソリューションも提供します。
Omni-MATH の開始は、AI の数学的能力に対する新たな挑戦であるだけでなく、高度な数学の分野における AI の将来の応用と開発のための重要な評価ツールも提供します。 AI技術の継続的な進歩により、近い将来、数学オリンピックの競技会でAIの驚くべきパフォーマンスを目撃できるかもしれません。
プロジェクトアドレス: https://github.com/KbsdJames/Omni-MATH/
全体として、Omni-MATH の登場は、AI の数学的能力の評価において新たな高みを示し、研究者や開発者に貴重なツールとデータを提供し、数学分野における AI の継続的な開発を促進します。今後もOmni-MATHは改良・アップデートを続け、AI数学の分野でさらに大きな役割を果たすことになると思います。