Los equipos de investigación de la Universidad de Pekín y Alibaba lanzaron conjuntamente un nuevo punto de referencia de evaluación de habilidades matemáticas Omni-MATH, que se utiliza para evaluar las capacidades de razonamiento de modelos de lenguaje grandes en el nivel de la Competencia de Matemáticas de la Olimpiada. El punto de referencia contiene 4.428 preguntas a nivel de competencia que cubren más de 33 subcampos de matemáticas, con niveles de dificultad que van desde el nivel de preparación olímpica hasta el nivel de competencia más alto, y se verifica manualmente para garantizar una alta confiabilidad de las respuestas. El lanzamiento de Omni-MATH proporciona nuevos estándares y formas de explorar el potencial de la IA en el campo de las matemáticas avanzadas y también proporciona una herramienta más completa para evaluar las capacidades de razonamiento matemático de grandes modelos de lenguaje. El editor de Downcodes explicará en detalle el diseño único, el sistema de evaluación y los métodos de evaluación innovadores de Omni-MATH.
Dado que GPT-4 de OpenAI ha logrado repetidamente excelentes resultados en evaluaciones de matemáticas tradicionales, los equipos de investigación de la Universidad de Pekín y Alibaba han lanzado conjuntamente un nuevo punto de referencia de evaluación: Omni-MATH, diseñado para evaluar el rendimiento de grandes modelos de lenguaje en el nivel de la Competencia Olímpica de Matemáticas. Habilidades de razonamiento. Esta iniciativa no sólo proporciona un nuevo estándar para la evaluación de las habilidades matemáticas de la IA, sino que también abre una nueva forma de explorar el potencial de la IA en el campo de las matemáticas avanzadas.
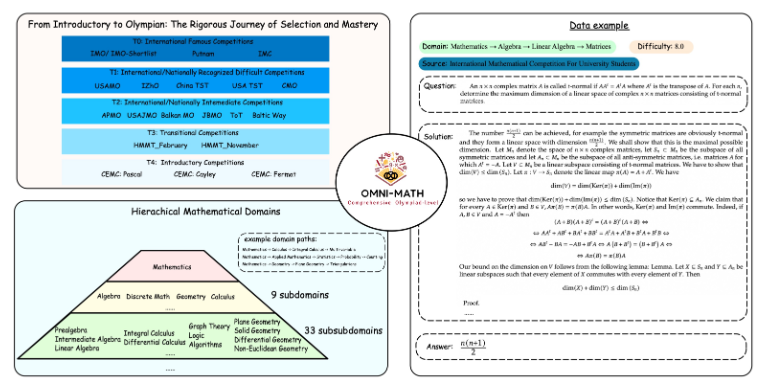
El diseño único de Omni-MATH
La biblioteca de evaluación Omni-MATH contiene 4428 preguntas de matemáticas de nivel competitivo, que cubren más de 33 subcampos de matemáticas, con 10 niveles diferentes de dificultad. Las características incluyen:
Alta confiabilidad: todas las preguntas provienen de varios foros y concursos de matemáticas, y las respuestas se verifican manualmente.
Amplia cobertura: desde el nivel preparatorio de la Olimpiada (T4) hasta las principales competiciones de matemáticas de la Olimpiada (T0), como IMO, IMC y Putnam, etc.
Consideración de la diversidad: la cuestión de la diversidad de respuestas se optimiza mediante métodos de evaluación basados en GPT-4 y otros modelos de evaluación.
En las últimas clasificaciones, además de la versión pura GPT-4, los artistas destacados incluyen:
GPT-4-mini: la puntuación promedio es aproximadamente un 8% más alta que la vista previa de GPT-4
Qwen2-MATH-72b: Superó los resultados de GPT-4-turbo
Estos resultados muestran que incluso los modelos pequeños pueden funcionar bien en capacidades específicas.
La profundidad y amplitud del sistema de evaluación.
El diseño de Omni-MATH tiene plenamente en cuenta el proceso de selección y el nivel de dificultad de los concursos internacionales de matemáticas:
Consulte los sistemas de selección de las Olimpiadas de Matemáticas en países como el Reino Unido y Estados Unidos.
Cubre muchas áreas de las matemáticas, desde la teoría de números hasta el álgebra y la geometría.
Las fuentes de datos incluyen varias preguntas de competencia, análisis y contenido de foros en sitios web de matemáticas famosos.
Métodos de evaluación innovadores
El equipo de investigación desarrolló el verificador de respuestas de código abierto Omni-Judge, que utiliza el modelo Llama3-Instruct ajustado para determinar rápidamente la coherencia entre la salida del modelo y la respuesta estándar. Este método no sólo garantiza una tasa de coherencia del 95%, sino que también proporciona una solución conveniente para la evaluación de problemas matemáticos complejos.
El lanzamiento de Omni-MATH no es sólo un nuevo desafío para las capacidades matemáticas de la IA, sino que también proporciona una importante herramienta de evaluación para la futura aplicación y desarrollo de la IA en el campo de las matemáticas avanzadas. Con el avance continuo de la tecnología de IA, es posible que podamos presenciar el sorprendente desempeño de la IA en la competencia de la Olimpiada de Matemáticas en un futuro cercano.
Dirección del proyecto: https://github.com/KbsdJames/Omni-MATH/
Con todo, el surgimiento de Omni-MATH marca una nueva altura en la evaluación de la capacidad matemática de la IA. Proporciona a investigadores y desarrolladores herramientas y datos valiosos y promueve el desarrollo continuo de la IA en el campo de las matemáticas. En el futuro, a medida que Omni-MATH continúe mejorándose y actualizándose, creo que desempeñará un papel más importante en el campo de las matemáticas de IA.