ทีมวิจัยจากมหาวิทยาลัยปักกิ่งและอาลีบาบาร่วมกันเปิดตัว Omni-MATH เกณฑ์มาตรฐานการประเมินความสามารถทางคณิตศาสตร์ใหม่ ซึ่งใช้ในการประเมินความสามารถในการให้เหตุผลของแบบจำลองภาษาขนาดใหญ่ในระดับการแข่งขันคณิตศาสตร์โอลิมปิก เกณฑ์มาตรฐานประกอบด้วยคำถามระดับการแข่งขัน 4,428 ข้อ ซึ่งครอบคลุมสาขาย่อยทางคณิตศาสตร์มากกว่า 33 สาขาวิชา โดยมีระดับความยากตั้งแต่ระดับเตรียมความพร้อมโอลิมปิกไปจนถึงระดับการแข่งขันสูงสุด และได้รับการตรวจสอบด้วยตนเองเพื่อให้มั่นใจว่าคำตอบมีความน่าเชื่อถือในระดับสูง การเปิดตัว Omni-MATH มอบมาตรฐานและวิธีการใหม่ในการสำรวจศักยภาพของ AI ในด้านคณิตศาสตร์ขั้นสูง และยังมอบเครื่องมือที่ครอบคลุมมากขึ้นสำหรับการประเมินความสามารถในการให้เหตุผลทางคณิตศาสตร์ของแบบจำลองภาษาขนาดใหญ่ บรรณาธิการของ Downcodes จะอธิบายรายละเอียดเกี่ยวกับการออกแบบ ระบบการประเมินผล และวิธีการประเมินที่เป็นนวัตกรรมใหม่ของ Omni-MATH
เนื่องจาก GPT-4 ของ OpenAI ได้รับผลลัพธ์ที่ยอดเยี่ยมหลายครั้งในการประเมินทางคณิตศาสตร์แบบดั้งเดิม ทีมวิจัยจากมหาวิทยาลัยปักกิ่งและอาลีบาบาจึงได้ร่วมกันเปิดตัวเกณฑ์มาตรฐานการประเมินใหม่ - Omni-MATH ซึ่งออกแบบมาเพื่อประเมินประสิทธิภาพของแบบจำลองภาษาขนาดใหญ่ในระดับการแข่งขันคณิตศาสตร์โอลิมปิก ทักษะการใช้เหตุผล โครงการริเริ่มนี้ไม่เพียงแต่มอบมาตรฐานใหม่สำหรับการประเมินความสามารถทางคณิตศาสตร์ของ AI เท่านั้น แต่ยังเปิดทางใหม่ในการสำรวจศักยภาพของ AI ในสาขาคณิตศาสตร์ขั้นสูงอีกด้วย
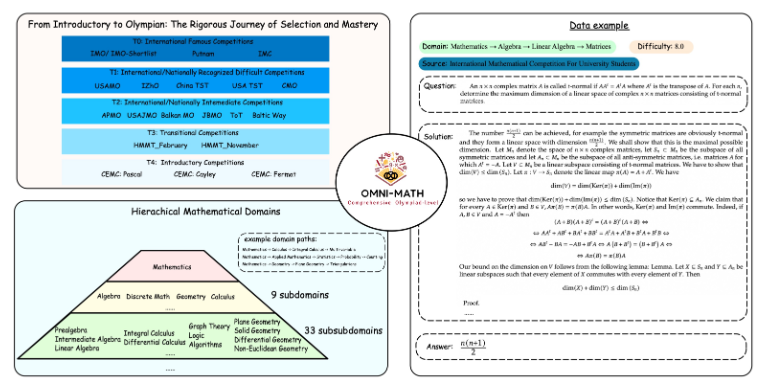
การออกแบบที่เป็นเอกลักษณ์ของ Omni-MATH
ห้องสมุดประเมินผล Omni-MATH มีคำถามคณิตศาสตร์ระดับแข่งขัน 4,428 ข้อ ครอบคลุมฟิลด์ย่อยคณิตศาสตร์มากกว่า 33 ฟิลด์ พร้อมระดับความยากที่แตกต่างกัน 10 ระดับ คุณสมบัติได้แก่:
ความน่าเชื่อถือสูง: คำถามทั้งหมดมาจากการแข่งขันและฟอรัมคณิตศาสตร์ต่างๆ และคำตอบจะได้รับการตรวจสอบด้วยตนเอง
ครอบคลุมอย่างกว้างขวาง: ตั้งแต่ระดับเตรียมอุดมศึกษาโอลิมปิก (T4) ไปจนถึงการแข่งขันคณิตศาสตร์โอลิมปิกชั้นนำ (T0) เช่น IMO, IMC และ Putnam เป็นต้น
การพิจารณาความหลากหลาย: คำถามเกี่ยวกับความหลากหลายของคำตอบได้รับการปรับให้เหมาะสมด้วยวิธีการประเมินตาม GPT-4 และแบบจำลองการประเมินอื่นๆ
ในการจัดอันดับล่าสุด นอกเหนือจากเวอร์ชันเต็มของ GPT-4 แล้ว ยังมีนักแสดงที่โดดเด่น ได้แก่:
GPT-4-mini: คะแนนเฉลี่ยสูงกว่า GPT-4-preview ประมาณ 8%
Qwen2-MATH-72b: เกินผลลัพธ์ของ GPT-4-turbo
ผลลัพธ์เหล่านี้แสดงให้เห็นว่าแม้แต่รุ่นเล็กๆ ก็สามารถทำงานได้ดีกับความสามารถเฉพาะด้าน
ความลึกและความกว้างของระบบการประเมินผล
การออกแบบ Omni-MATH คำนึงถึงกระบวนการคัดเลือกและระดับความยากของการแข่งขันคณิตศาสตร์ระดับนานาชาติอย่างเต็มที่:
อ้างถึงระบบการคัดเลือกคณิตศาสตร์โอลิมปิกในประเทศต่างๆ เช่น สหราชอาณาจักร และสหรัฐอเมริกา
ครอบคลุมคณิตศาสตร์หลายแขนงตั้งแต่ทฤษฎีจำนวน พีชคณิต ไปจนถึงเรขาคณิต
แหล่งข้อมูลประกอบด้วยคำถามการแข่งขัน การวิเคราะห์ และเนื้อหาฟอรั่มบนเว็บไซต์คณิตศาสตร์ที่มีชื่อเสียง
วิธีการประเมินผลที่เป็นนวัตกรรมใหม่
ทีมวิจัยได้พัฒนาเครื่องตรวจสอบคำตอบโอเพ่นซอร์ส Omni-Judge ซึ่งใช้โมเดล Llama3-Instruct ที่ปรับแต่งมาอย่างดี เพื่อระบุความสอดคล้องระหว่างเอาต์พุตของโมเดลและคำตอบมาตรฐานได้อย่างรวดเร็ว วิธีการนี้ไม่เพียงแต่รับประกันอัตราความสอดคล้อง 95% เท่านั้น แต่ยังให้โซลูชันที่สะดวกสำหรับการประเมินปัญหาทางคณิตศาสตร์ที่ซับซ้อนอีกด้วย
การเปิดตัว Omni-MATH ไม่เพียงแต่เป็นความท้าทายครั้งใหม่ต่อความสามารถทางคณิตศาสตร์ของ AI เท่านั้น แต่ยังเป็นเครื่องมือประเมินที่สำคัญสำหรับการประยุกต์ใช้ในอนาคตและการพัฒนา AI ในสาขาคณิตศาสตร์ขั้นสูงอีกด้วย ด้วยความก้าวหน้าอย่างต่อเนื่องของเทคโนโลยี AI เราอาจจะได้เห็นประสิทธิภาพอันน่าทึ่งของ AI ในการแข่งขันคณิตศาสตร์โอลิมปิกในอนาคตอันใกล้นี้
ที่อยู่โครงการ: https://github.com/KbsdJames/Omni-MATH/
โดยรวมแล้ว การเกิดขึ้นของ Omni-MATH ถือเป็นก้าวใหม่ในการประเมินความสามารถทางคณิตศาสตร์ของ AI ช่วยให้นักวิจัยและนักพัฒนาได้รับเครื่องมือและข้อมูลอันทรงคุณค่า และส่งเสริมการพัฒนา AI อย่างต่อเนื่องในสาขาคณิตศาสตร์ ในอนาคต เนื่องจาก Omni-MATH ได้รับการปรับปรุงและปรับปรุงอย่างต่อเนื่อง ฉันเชื่อว่ามันจะมีบทบาทมากขึ้นในสาขาคณิตศาสตร์ AI