Tim peneliti dari Universitas Peking dan Alibaba bersama-sama merilis tolok ukur evaluasi kemampuan matematika baru Omni-MATH, yang digunakan untuk mengevaluasi kemampuan penalaran model bahasa besar di tingkat Kompetisi Matematika Olimpiade. Tolok ukur tersebut berisi 4.428 pertanyaan tingkat kompetisi yang mencakup lebih dari 33 subbidang matematika, dengan tingkat kesulitan mulai dari tingkat persiapan Olimpiade hingga tingkat kompetisi teratas, dan diverifikasi secara manual untuk memastikan keandalan jawaban yang tinggi. Peluncuran Omni-MATH memberikan standar dan cara baru untuk mengeksplorasi potensi AI di bidang matematika tingkat lanjut, dan juga menyediakan alat yang lebih komprehensif untuk mengevaluasi kemampuan penalaran matematis model bahasa besar. Editor Downcodes akan menjelaskan secara detail desain unik, sistem evaluasi, dan metode evaluasi inovatif Omni-MATH.
Karena GPT-4 OpenAI telah berulang kali mencapai hasil luar biasa dalam evaluasi matematika tradisional, tim peneliti dari Universitas Peking dan Alibaba bersama-sama meluncurkan tolok ukur evaluasi baru - Omni-MATH, yang dirancang untuk mengevaluasi kinerja model bahasa besar di tingkat Kompetisi Matematika Olimpiade. Keterampilan penalaran. Inisiatif ini tidak hanya memberikan standar baru untuk evaluasi kemampuan matematika AI, tetapi juga membuka cara baru untuk mengeksplorasi potensi AI di bidang matematika tingkat lanjut.
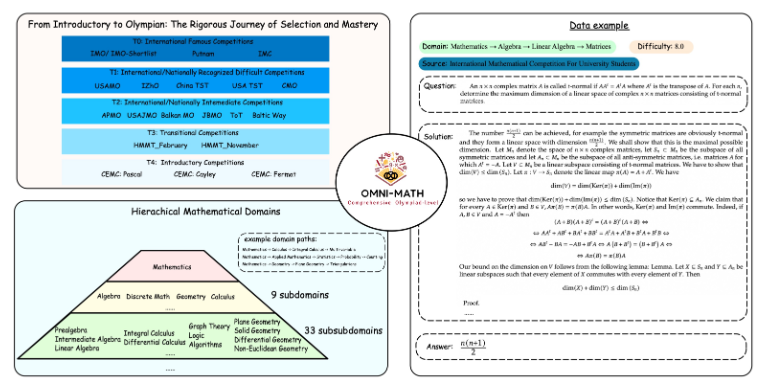
Desain unik Omni-MATH
Perpustakaan evaluasi Omni-MATH berisi 4.428 soal matematika tingkat kompetisi, mencakup lebih dari 33 subbidang matematika, dengan 10 tingkat kesulitan berbeda. Fitur-fiturnya meliputi:
Keandalan tinggi: Semua pertanyaan berasal dari berbagai kompetisi dan forum matematika, dan jawabannya diverifikasi secara manual.
Cakupan luas: dari tingkat persiapan Olimpiade (T4) hingga kompetisi matematika Olimpiade teratas (T0) seperti IMO, IMC dan Putnam dll.
Pertimbangan keberagaman: Pertanyaan keberagaman jawaban dioptimalkan melalui metode evaluasi berdasarkan GPT-4 dan model evaluasi lainnya.
Dalam pemeringkatan terbaru, selain versi totok GPT-4, pemain yang berprestasi antara lain:
GPT-4-mini: Skor rata-rata sekitar 8% lebih tinggi dibandingkan pratinjau GPT-4
Qwen2-MATH-72b: Melebihi hasil GPT-4-turbo
Hasil ini menunjukkan bahwa model kecil sekalipun dapat bekerja dengan baik pada kemampuan tertentu.
Kedalaman dan luasnya sistem evaluasi
Perancangan Omni-MATH mempertimbangkan sepenuhnya proses seleksi dan tingkat kesulitan kompetisi matematika internasional:
Lihat sistem seleksi Olimpiade Matematika di negara-negara seperti Inggris dan Amerika Serikat.
Mencakup banyak bidang matematika mulai dari teori bilangan, aljabar, hingga geometri
Sumber datanya meliputi berbagai soal kompetisi, analisis, dan konten forum di website matematika ternama
Metode evaluasi yang inovatif
Tim peneliti mengembangkan pemverifikasi jawaban sumber terbuka Omni-Judge, yang menggunakan model Llama3-Instruct yang telah disempurnakan untuk dengan cepat menentukan konsistensi antara keluaran model dan jawaban standar. Metode ini tidak hanya menjamin tingkat konsistensi 95%, tetapi juga memberikan solusi yang mudah untuk evaluasi masalah matematika yang kompleks.
Peluncuran Omni-MATH tidak hanya menjadi tantangan baru terhadap kemampuan matematika AI, namun juga menyediakan alat evaluasi penting untuk penerapan dan pengembangan AI di bidang matematika tingkat lanjut di masa depan. Dengan kemajuan teknologi AI yang berkelanjutan, kita mungkin bisa menyaksikan performa AI yang luar biasa dalam kompetisi Olimpiade Matematika dalam waktu dekat.
Alamat proyek: https://github.com/KbsdJames/Omni-MATH/
Secara keseluruhan, kemunculan Omni-MATH menandai pencapaian baru dalam penilaian kemampuan matematika AI. Hal ini memberikan para peneliti dan pengembang alat dan data yang berharga, serta mendorong pengembangan AI yang berkelanjutan di bidang matematika. Di masa depan, seiring dengan penyempurnaan dan pembaruan Omni-MATH, saya yakin Omni-MATH akan memainkan peran yang lebih besar di bidang matematika AI.