Count Sketch Optimizers
1.0.0
通過計數 - 佐劑壓縮梯度優化器
Ryan Spring,Anastasios Kyrillidis,Vijai Mohan,Anshumali Shrivastava的ICML 2019年論文
在NVIDIA V100 DGX-1服務器上接受激活檢查點和混合精度訓練(FP16)培訓
| Bert-large | 亞當 | 計數敏草圖(CMS)-RMSPROP |
|---|---|---|
| 時間(天) | 5.32 | 5.52 |
| 尺寸(MB) | 7,097 | 5,133 |
| 測試困惑 | 4.04 | 4.18 |
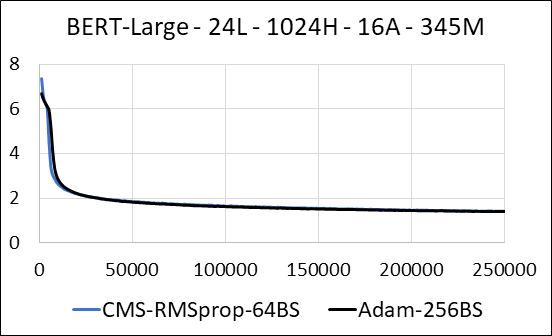
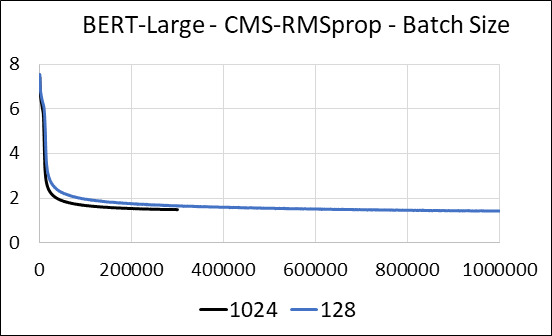
我們支持在沒有更新稀疏性的情況下壓縮神經網絡的密集層。在培訓期間,我們更新輔助變量,並在單個Fused Cuda內核中執行每個參數的梯度更新。密集的內核等同於稀疏的內核。主要區別在於,我們明確避免在全球內存中為密集層生成輔助變量。相反,我們在GPU流媒體多處理器的共享內存中訪問它們。沒有此關鍵功能,我們的方法將無法為密集層保存任何GPU內存。在稀疏的情況下,我們假設非零梯度更新明顯小於輔助變量。 (有關更多詳細信息,請參見dense_exp_cms.py)


