Count Sketch Optimizers
1.0.0
通过计数 - 佐剂压缩梯度优化器
Ryan Spring,Anastasios Kyrillidis,Vijai Mohan,Anshumali Shrivastava的ICML 2019年论文
在NVIDIA V100 DGX-1服务器上接受激活检查点和混合精度训练(FP16)培训
| Bert-large | 亚当 | 计数敏草图(CMS)-RMSPROP |
|---|---|---|
| 时间(天) | 5.32 | 5.52 |
| 尺寸(MB) | 7,097 | 5,133 |
| 测试困惑 | 4.04 | 4.18 |
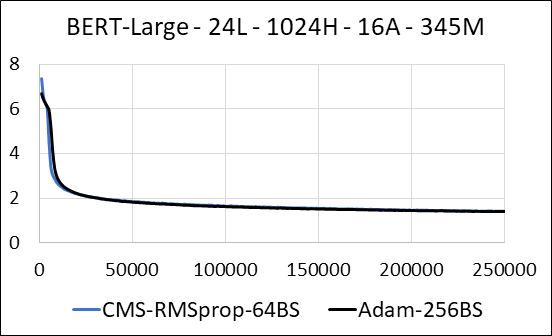
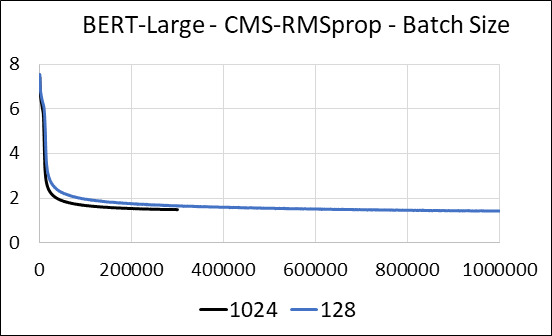
我们支持在没有更新稀疏性的情况下压缩神经网络的密集层。在培训期间,我们更新辅助变量,并在单个Fused Cuda内核中执行每个参数的梯度更新。密集的内核等同于稀疏的内核。主要区别在于,我们明确避免在全球内存中为密集层生成辅助变量。相反,我们在GPU流媒体多处理器的共享内存中访问它们。没有此关键功能,我们的方法将无法为密集层保存任何GPU内存。在稀疏的情况下,我们假设非零梯度更新明显小于辅助变量。 (有关更多详细信息,请参见dense_exp_cms.py)


