Count Sketch Optimizers
1.0.0
Compression des optimisateurs de gradient via le comptage
Un article ICML 2019 de Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
Formé avec l'activation de contrôle de contrôle et de formation de précision mixte (FP16) sur les serveurs NVIDIA V100 DGX-1
| Bert-grand | Adam | Count-Min Sketch (CMS) - RMSProp |
|---|---|---|
| Temps (jours) | 5.32 | 5.52 |
| Taille (MB) | 7 097 | 5 133 |
| Tester la perplexité | 4.04 | 4.18 |
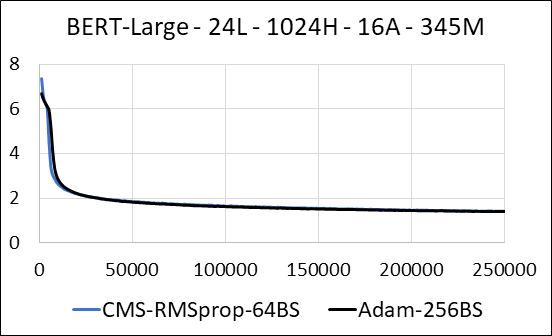
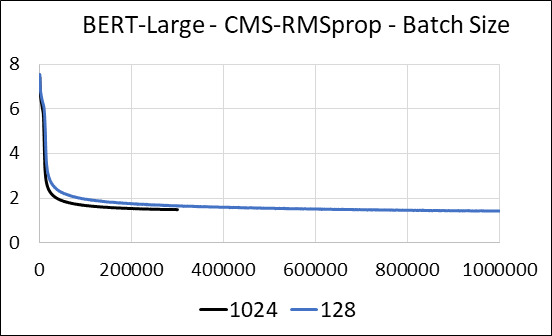
Nous prenons en charge la compression des couches denses du réseau neuronal sans mettre à jour la rareté. Pendant la formation, nous mettons à jour les variables auxiliaires et effectuons la mise à jour du gradient pour chaque paramètre dans un seul noyau Cuda fusionné. Le noyau dense équivaut au noyau clairsemé. La principale différence est que nous évitons explicitement de générer les variables auxiliaires pour les couches denses dans la mémoire globale. Au lieu de cela, nous y accédons à l'intérieur de la mémoire partagée du multiprocesseur de streaming GPU. Sans cette caractéristique clé, notre approche n'enregistrerait aucune mémoire GPU pour les couches denses. Dans le cas clairsemé, nous supposons que les mises à jour de gradient non nulles sont nettement plus petites que la variable auxiliaire. (Voir dense_exp_cms.py pour plus de détails)


