Count Sketch Optimizers
1.0.0
Mengompres pengoptimal gradien melalui count-sketches
Kertas ICML 2019 oleh Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
Dilatih dengan pengambilan pemeriksaan aktivasi dan pelatihan presisi campuran (FP16) di server NVIDIA V100 DGX-1
| Bert-Large | Adam | Count -Min Sketch (CMS) - RMSPROP |
|---|---|---|
| Waktu (hari) | 5.32 | 5.52 |
| Ukuran (MB) | 7.097 | 5.133 |
| Uji kebingungan | 4.04 | 4.18 |
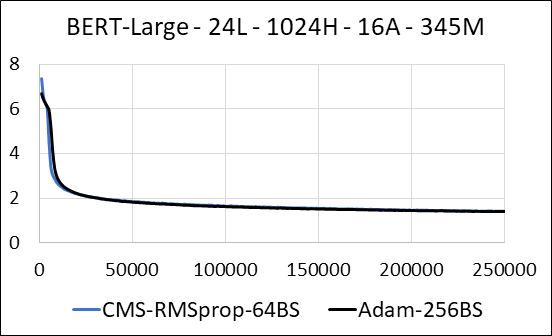
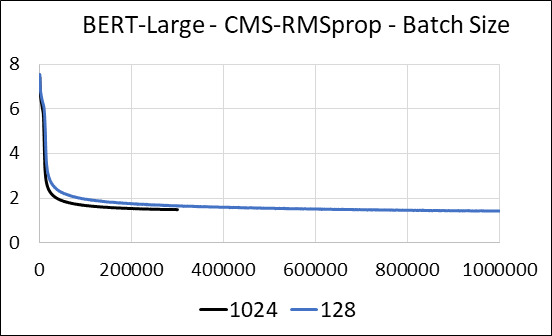
Kami mendukung mengompresi lapisan padat jaringan saraf tanpa pembaruan sparsity. Selama pelatihan, kami memperbarui variabel tambahan dan melakukan pembaruan gradien untuk setiap parameter dalam satu kernel CUDA yang menyatu. Kernel padat setara dengan kernel yang jarang. Perbedaan utama adalah bahwa kami secara eksplisit menghindari menghasilkan variabel tambahan untuk lapisan padat dalam memori global. Sebaliknya, kami mengaksesnya di dalam memori bersama dari multiprosesor streaming GPU. Tanpa fitur utama ini, pendekatan kami tidak akan menyimpan memori GPU untuk lapisan padat. Dalam kasus yang jarang, kami berasumsi bahwa pembaruan gradien non-nol secara signifikan lebih kecil dari variabel tambahan. (Lihat disense_exp_cms.py untuk detail lebih lanjut)


