Count Sketch Optimizers
1.0.0
Otimizadores de gradiente de compactação via contagem de espacadas
Um artigo ICML 2019 de Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
Treinado com o check-inging de ativação e treinamento misto de precisão (FP16) em servidores NVIDIA V100 DGX-1
| Bert-Large | Adão | Count -Min Sketch (CMS) - RMSPROP |
|---|---|---|
| Tempo (dias) | 5.32 | 5.52 |
| Tamanho (MB) | 7.097 | 5.133 |
| Teste perplexidade | 4.04 | 4.18 |
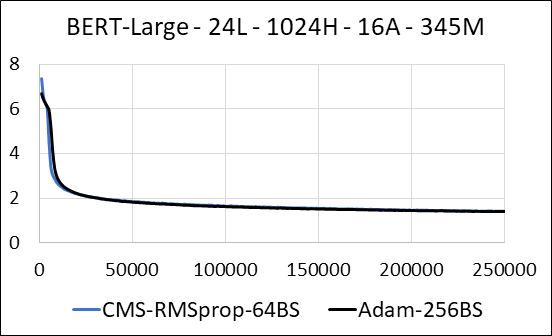
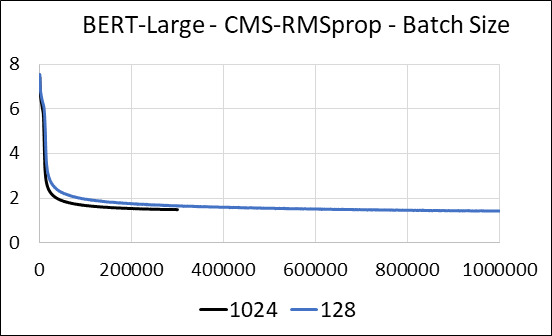
Apoiamos a compactação das camadas densas da rede neural sem a esparsidade de atualização. Durante o treinamento, atualizamos as variáveis auxiliares e executamos a atualização do gradiente para cada parâmetro em um único kernel CUDA fundido. O núcleo denso é equivalente ao núcleo esparso. A principal diferença é que evitamos explicitamente gerar as variáveis auxiliares para as camadas densas na memória global. Em vez disso, acessamos -os dentro da memória compartilhada do multiprocessador de streaming de GPU. Sem esse recurso -chave, nossa abordagem não salvaria nenhuma memória da GPU para as camadas densas. No caso esparso, assumimos que as atualizações de gradiente diferentes de zero são significativamente menores que a variável auxiliar. (Veja dense_exp_cms.py para obter mais detalhes)


