Count Sketch Optimizers
1.0.0
Optimizadores de gradiente de comprimir a través de bocadillos de conteo
Un artículo ICML 2019 de Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
Entrenado con puntos de control de activación y entrenamiento mixto de precisión (FP16) en servidores NVIDIA V100 DGX-1
| Bernemacia | Adán | Boceto de minuto de conteo (CMS) - RMSPOP |
|---|---|---|
| Tiempo (días) | 5.32 | 5.52 |
| Tamaño (MB) | 7.097 | 5,133 |
| Examen de la prueba | 4.04 | 4.18 |
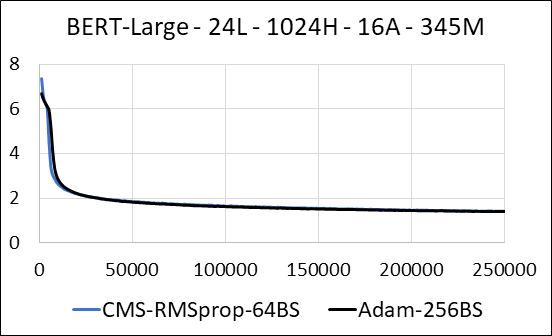
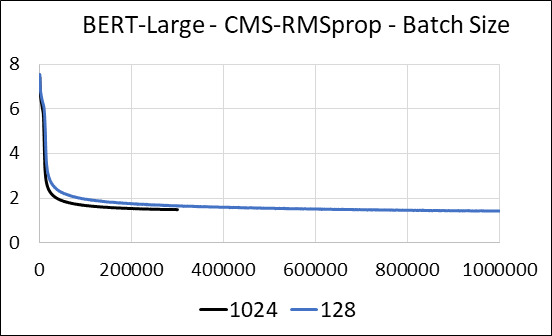
Apoyamos la comprimir las capas densas de la red neuronal sin escasario de actualización. Durante el entrenamiento, actualizamos las variables auxiliares y realizamos la actualización de gradiente para cada parámetro en un solo núcleo CUDA fusionado. El núcleo denso es equivalente al escaso núcleo. La principal diferencia es que evitamos explícitamente generar las variables auxiliares para las capas densas en la memoria global. En cambio, accedemos a ellos dentro de la memoria compartida del multiprocesador de transmisión de GPU. Sin esta característica clave, nuestro enfoque no guardaría ninguna memoria de GPU para las capas densas. En el caso escaso, suponemos que las actualizaciones de gradiente distintas de cero son significativamente más pequeñas que la variable auxiliar. (Ver Dense_EXP_CMS.py para más detalles)


