Count Sketch Optimizers
1.0.0
ضغط محسّنات التدرج عبر اللوحات العددية
ورقة ICML 2019 لريان سبرينج ، أناستاسيوس كيريليديس ، فيجاي موهان ، أنشومالي شريفاستافا
تدرب مع تفعيل التفتيش والتدريب الدقيق المختلط (FP16) على خوادم NVIDIA V100 DGX-1
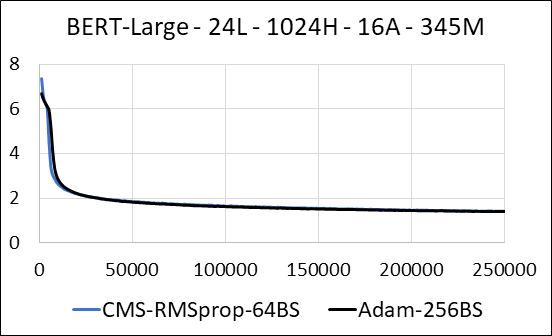
| بيرت large | آدم | Count -Min Sketch (CMS) - RMSPROP |
|---|---|---|
| الوقت (أيام) | 5.32 | 5.52 |
| الحجم (MB) | 7،097 | 5،133 |
| اختبار الحيرة | 4.04 | 4.18 |
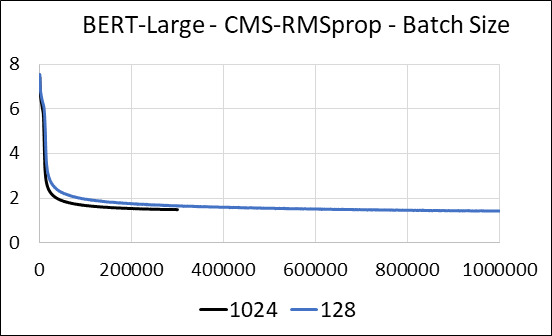
نحن ندعم ضغط الطبقات الكثيفة من الشبكة العصبية دون تحديث التباعد. أثناء التدريب ، نقوم بتحديث المتغيرات الإضافية وأداء تحديث التدرج لكل معلمة في kernel واحد منصهر. النواة الكثيفة تعادل النواة المتفرقة. الفرق الرئيسي هو أننا نتجنب صراحة توليد المتغيرات الإضافية للطبقات الكثيفة في الذاكرة العالمية. بدلاً من ذلك ، نصل إليها داخل الذاكرة المشتركة لعلاج GPU الذي يتدفق. بدون هذه الميزة الرئيسية ، لن يحفظ نهجنا أي ذاكرة GPU للطبقات الكثيفة. في الحالة المتفرقة ، نفترض أن تحديثات التدرج غير الصفر أصغر بكثير من المتغير المساعد. (انظر Dense_exp_cms.py لمزيد من التفاصيل)


