Count Sketch Optimizers
1.0.0
Сжатие градиентных оптимизаторов через счетные счеты
Бумага ICML 2019 Райана Спринг, Анастасиос Кириллидис, Виджай Мохан, Аншумали Шривастава
Обученные с помощью контрольно-пропускной точки активации и смешанной точности (FP16) на серверах NVIDIA V100 DGX-1
| Берт-широкий | Адам | Эскиз графа -мин (CMS) - RMSProp |
|---|---|---|
| Время (дни) | 5.32 | 5.52 |
| Размер (MB) | 7 097 | 5,133 |
| Тест недоумения | 4.04 | 4.18 |
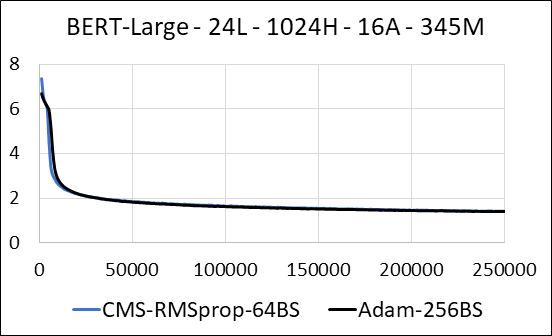
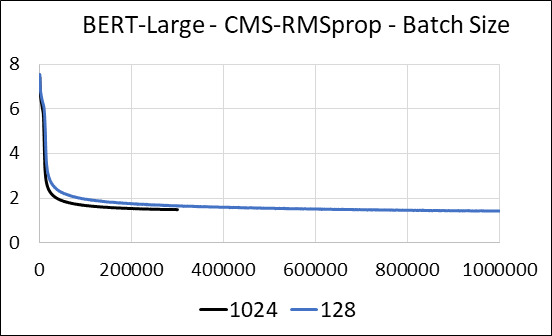
Мы поддерживаем сжатие плотных слоев нейронной сети без обновления разреженности. Во время обучения мы обновляем вспомогательные переменные и выполняем обновление градиента для каждого параметра в одном плавном ядре CUDA. Плотное ядро эквивалентно разреженному ядру. Основное отличие заключается в том, что мы явно избегаем генерирования вспомогательных переменных для плотных слоев в глобальной памяти. Вместо этого мы получаем доступ к ним внутри общей памяти о многопроцессоре потокового графического процессора. Без этой ключевой функции наш подход не сохранит память GPU для плотных слоев. В разреженном случае мы предполагаем, что обновления ненулевых градиентов значительно меньше вспомогательной переменной. (См. Dense_exp_cms.py для получения более подробной информации)


