Count Sketch Optimizers
1.0.0
Komprimierende Gradientenoptimierer über Count-Sketches
Ein ICML 2019 -Papier von Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
Trainiert mit Aktivierungsprüfung und gemischtes Präzisionstraining (FP16) auf NVIDIA V100 DGX-1-Servern
| Bert-Large | Adam | Count -min Sketch (CMS) - RMSProp |
|---|---|---|
| Zeit (Tage) | 5.32 | 5.52 |
| Größe (MB) | 7.097 | 5,133 |
| Verwirrung testen | 4.04 | 4.18 |
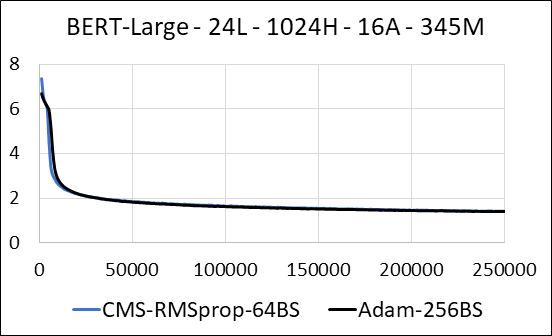
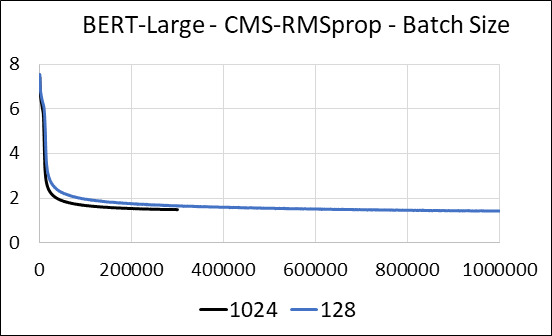
Wir unterstützen die Komprimierung der dichten Schichten des neuronalen Netzwerks ohne Update -Sparsity. Während des Trainings aktualisieren wir die Hilfsvariablen und führen das Gradienten -Update für jeden Parameter in einem einzigen fusionierten Cuda -Kernel durch. Der dichte Kernel entspricht dem spärlichen Kernel. Der Hauptunterschied besteht darin, dass wir es explizit vermeiden, die Hilfsvariablen für die dichten Schichten im globalen Gedächtnis zu generieren. Stattdessen greifen wir im gemeinsamen Speicher des GPU -Streaming -Multiprozessors auf sie zu. Ohne diese Schlüsselfunktion würde unser Ansatz keinen GPU -Speicher für die dichten Ebenen speichern. Im spärlichen Fall gehen wir davon aus, dass die Gradienten-Updates ungleich Null erheblich kleiner sind als die Hilfsvariable. (Weitere Informationen finden Sie unter dense_exp_cms.py)


