Count Sketch Optimizers
1.0.0
บีบอัดการเพิ่มประสิทธิภาพการไล่ระดับสีผ่านการนับแผ่นรอง
กระดาษ ICML 2019 โดย Ryan Spring, Anastasios Kyrillidis, Vijai Mohan, Anshumali Shrivastava
ได้รับการฝึกฝนด้วยการเปิดใช้งานจุดตรวจสอบและการฝึกอบรมแบบผสมผสาน (FP16) บนเซิร์ฟเวอร์ NVIDIA V100 DGX-1
| เบิร์ตขนาดใหญ่ | อดัม | Count -Min Sketch (CMS) - RMSPROP |
|---|---|---|
| เวลา (วัน) | 5.32 | 5.52 |
| ขนาด (MB) | 7,097 | 5,133 |
| ทดสอบความงุนงง | 4.04 | 4.18 |
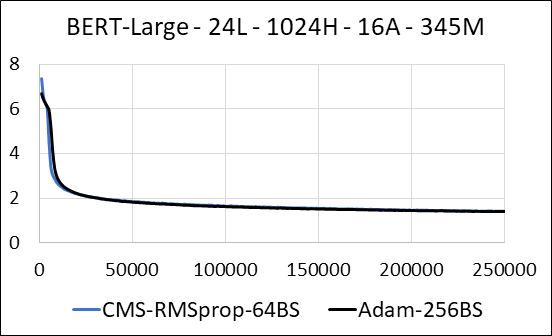
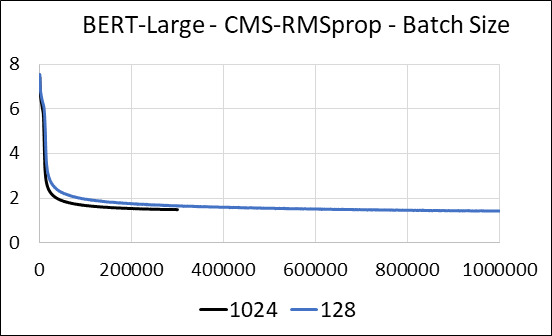
เราสนับสนุนการบีบอัดเลเยอร์หนาแน่นของเครือข่ายประสาทโดยไม่ต้องอัปเดต sparsity ในระหว่างการฝึกอบรมเราจะอัปเดตตัวแปรเสริมและดำเนินการอัปเดตการไล่ระดับสีสำหรับแต่ละพารามิเตอร์ในเคอร์เนล CUDA ที่หลอมรวมเดียว เคอร์เนลหนาแน่นเทียบเท่ากับเคอร์เนลที่กระจัดกระจาย ความแตกต่างที่สำคัญคือเราหลีกเลี่ยงการสร้างตัวแปรเสริมสำหรับเลเยอร์หนาแน่นในหน่วยความจำทั่วโลกอย่างชัดเจน แต่เราเข้าถึงพวกเขาภายในหน่วยความจำที่ใช้ร่วมกันของ GPU สตรีมมัลติโปรเซสเซอร์ หากไม่มีคุณสมบัติสำคัญนี้วิธีการของเราจะไม่บันทึกหน่วยความจำ GPU ใด ๆ สำหรับเลเยอร์หนาแน่น ในกรณีที่กระจัดกระจายเราคิดว่าการอัปเดตการไล่ระดับสีที่ไม่เป็นศูนย์นั้นเล็กกว่าตัวแปรเสริมอย่างมีนัยสำคัญ (ดู DENSE_EXP_CMS.PY สำหรับรายละเอียดเพิ่มเติม)


