pykaldi
v0.2.2
Pykaldi是Kaldi語音識別工具包的Python腳本層。它為Kaldi和OpenFST庫中的C ++代碼提供了易於使用的,低空的,一流的Python包裝器。您可以使用pykaldi編寫python代碼,以否則需要編寫C ++代碼,例如調用低級Kaldi功能,在代碼中操縱Kaldi和OpenFST對像或實現新的Kaldi工具。
您可以將Kaldi視為一個大型樂高積木,您可以混合併匹配以構建自定義語音識別解決方案。想到Pykaldi的最好方法是作為補充,如果願意的話,可以搭配Kaldi。實際上,當Pykaldi與Kaldi一起使用時,它處於最佳狀態。為此,複製Kaldi提供的無數命令行工具,實用程序腳本和殼級配方的功能是Pykaldi項目的非目標。
像卡爾迪(Kaldi)一樣,Pykaldi主要用於言語識別研究人員和專業人士。它充滿了裝滿的東西,需要利用Kaldi和OpenFST庫提供的大量實用程序,算法和數據結構來構建Python軟件。
如果您不熟悉基於FST的語音識別或對訪問Python中Kaldi和OpenFST的膽量沒有興趣,但是只想在Python應用程序的一部分中運行預先訓練的Kaldi系統,請不要擔心。 Pykaldi包括大多數Python程序員應該可以訪問的許多高級應用方向的模塊,例如asr , alignment和segmentation 。
如果您有興趣使用Pykaldi進行研究或構建高級ASR應用程序,那麼您很幸運。 Pykaldi提供了您在Python中讀,寫,檢查,操縱或可視化Kaldi和OpenFST對象所需的一切。它包括Python包裝器,用於大多數功能和方法,這些功能和方法是Kaldi和OpenFST C ++庫的一部分。如果您想讀取/寫由Kaldi工俱生成/消耗的文件,請在util軟件包中查看I/O和表實用程序。如果您想使用Kaldi矩陣和向量,例如將它們轉換為numpy ndarrays,反之亦然,請查看matrix軟件包。如果您想使用Kaldi進行功能提取和轉換,請查看feat , ivector和transform Packages。如果您想使用Kaldi工俱生產/消耗的晶格或其他FST結構,請查看fstext , lat和kws軟件包。如果您想在Kaldi中低水平訪問高斯混合模型,隱藏的馬爾可夫模型或語音決策樹,請查看gmm , sgmm2 , hmm和tree包。如果您想低水平訪問Kaldi神經網絡模型,請查看nnet3 , cudamatrix和chain套件。如果您想在Kaldi中使用解碼器和語言建模實用程序,請查看decoder , lm , rnnlm , tfrnnlm和online2軟件包。
有興趣了解Kaldi和Pykaldi更多有關Kaldi和Pykaldi的讀者可能會發現以下資源有用:
由於Python中的自動語音識別(ASR)無疑是Pykaldi的“殺手應用程序”,因此我們將瀏覽一些ASR場景,以了解Pykaldi API。我們應該注意,Pykaldi不提供用於培訓ASR模型的任何高級實用程序,因此您需要使用Kaldi食譜培訓模型或使用在線可用的預培訓模型。之所以如此,是因為Kaldi C ++庫中沒有高級ASR培訓API。使用複雜的殼級配方對Kaldi ASR模型進行了培訓,這些配方可以處理從數據製備到培訓中使用的無數Kaldi可執行文件的所有內容。這是設計,將來不太可能發生變化。 Pykaldi確實為Kaldi C ++庫中的低級ASR培訓實用程序提供包裝紙,但是除非您想通過基本的構建塊在Python建立ASR培訓管道,否則這些庫並不是很容易的,這並不是一件容易的事。繼續進行樂高的類比,此任務類似於構建此給定的訪問您可能需要的樂高積木的卡車的訪問。如果您瘋了足夠嘗試,請不要讓本段勸阻您。在我們開始構建Pykaldi之前,我們認為這也是一個瘋狂的任務。
Pykaldi asr模塊包含許多易於使用的高級類,以使將ASR系統放在Python中簡單。忽略設置設置所需的樣板代碼,使用Pykaldi進行ASR可以像以下代碼段一樣簡單:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ])在這個簡化的示例中,我們首先使用模型final.mdl ,解碼圖HCLG.fst和符號表words.txt的模型final.mdl的路徑實例化SomeRecognizer 。 opts對象包含識別器的配置選項。然後,我們實例化了一個Pykaldi Table Reader SequentialMatrixReader ,以讀取存儲在Kaldi Archive feats.ark中的功能矩陣。最後,我們迭代特徵矩陣,然後一一將它們進行解碼。在這裡,我們只是為每個話語打印出最好的ASR假設,因此我們只對輸出字典的"text" out感興趣。請記住,輸出字典包含許多其他有用的條目,例如最佳假設的框架級別對齊和代表最可能假設的加權晶格。誠然,並非所有的ASR管道都像這個示例一樣簡單,但是它們通常具有相同的整體結構。在以下各節中,我們將看到如何調整上面給出的代碼以實現更複雜的ASR管道。
這是最常見的情況。我們想使用預先訓練的Kaldi模型(例如Aspire Chain Models)進行離線ASR進行離線ASR。在這裡,我們使用“模型”一詞來指代建立ASR系統所需的一切。在這個具體示例中,我們將需要:
請注意,您可以使用此示例代碼與Aspire鏈模型進行解碼。
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ]最後一部分的示例和短片段之間的基本區別在於,對於每種話語,我們都是從磁盤讀取原始音頻數據並即時計算兩個功能矩陣,而不是從磁盤中讀取單個預報的特徵矩陣。腳本文件wav.scp包含與我們要解碼的話語相對應的WAV文件列表。我們正在提取的附加功能矩陣包含在線I-向量,這些i-向量由神經網絡聲學模型使用,以執行通道和揚聲器適應。揚聲器對材料圖spk2utt用於在線i-vector提取中為每個說話者累積單獨的統計信息。如果揚聲器信息不可用,則可以是簡單的身份映射。我們將MFCC功能和I-向量打包到元組中,然後將此元組傳遞給識別器進行解碼。 Pykaldi中的神經網絡識別器知道如何在可用時處理其他I-vetor功能。模型文件final.mdl包含過渡模型和神經網絡聲學模型。 NnetLatticeFasterRecognizer過程通過使用神經網絡聲學模型將手機日誌樣式的矩陣具有矩陣,然後使用過渡模型將其映射到過渡日誌類模型,並最終使用解碼圖HCLG.fst的Word IDS iDS in IDS ONTUPT IDS ON ONTUPT IDS和該word IDS Ontut intupt intupt and Oncut intupt and toptions intuption模型。解碼後,我們將識別器生成的晶格保存到Kaldi檔案中,以進行將來的處理。
此示例還說明了Kaldi提供的強大I/O機制。我們將它們定義為Kaldi讀取指定器,並僅通過實例化Pykaldi表讀取器並在它們上迭代來計算功能矩陣,而不是在代碼中實現功能提取管道,而是將其定義為Kaldi。這不僅是使用Pykaldi計算特徵的最簡單的方法,因為功能提取管道由操作系統並聯運行。同樣,我們使用kaldi寫入說明符來實例化pykaldi表作者,該桌子作者將輸出晶格寫入壓縮的kaldi存檔。請注意,要使它們起作用,我們需要compute-mfcc-feats , ivector-extract-online2和gzip才能走上我們的PATH 。
這類似於以前的情況,但是我們使用Pytorch聲學模型,而不是Kaldi聲學模型。在計算出以前的功能之後,我們將它們轉換為pytorch張量,使用pytorch神經網絡模塊進行前向通行證,以輸出手機日誌樣式,並最終將這些log-likelihoods轉換為pykaldi矩陣進行解碼。識別器使用過渡模型自動將手機ID映射到過渡ID,即典型的Kaldi解碼圖上的輸入標籤。
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]本節是佔位符。同時查看此腳本。
晶格逆轉是一種用於使用ASR中大型N-Gram語言模型或經常性神經網絡語言模型(RNNLMS)的標準技術。在此示例中,我們使用kaldi rnnlm恢復了晶格。我們首先通過提供模型的路徑來實例化委員。然後,我們使用桌子讀取器迭代要撤回的晶格,最後使用桌子作家將回歸的格子寫回磁盤。
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat )請注意,我們用來從單詞功能和即時嵌入功能嵌入的擴展文件名計算單詞嵌入。還值得注意的是我們用來透明地解壓縮/壓縮晶格檔案的讀/寫規範。要使這些工作,我們需要rnnlm-get-word-embedding , gunzip和gzip才能走上我們的PATH 。
Pykaldi旨在彌合Kaldi與Python所提供的所有美好事物之間的差距。它不僅僅是綁定到卡爾迪庫的綁定。這是一個腳本層,可為Python中的必需Kaldi和OpenFST類型提供一流的支持。 Pykaldi矢量和基質類型與Numpy緊密整合。它們可以無縫轉換為numpy陣列,反之亦然,而無需複制基本的內存緩衝區。 Pykaldi FST類型,包括Kaldi Style Lattices,是Python的一流公民。面對FST類型和操作的用戶的API幾乎完全定義在Python模仿PyWrapFST(pywrapfst)的API,這是OpenFST的官方Python包裝器。
Pykaldi利用CLIF使用簡單的API描述來包裹Kaldi和OpenFST C ++庫。可以在Python中導入CLIF生成的CPYTHON擴展模塊,以與Kaldi和OpenFST相互作用。儘管Clif非常適合暴露Python中現有的C ++ API,但包裝器並不總是會揭示Python易於使用的“ Pythonic” API。 Pykaldi通過在Python(有時在C ++中)擴展了RAW CLIF包裝器來解決這一問題,以提供更多的“ Pythonic” API。下圖說明了pykaldi適合卡爾迪生態系統的位置。
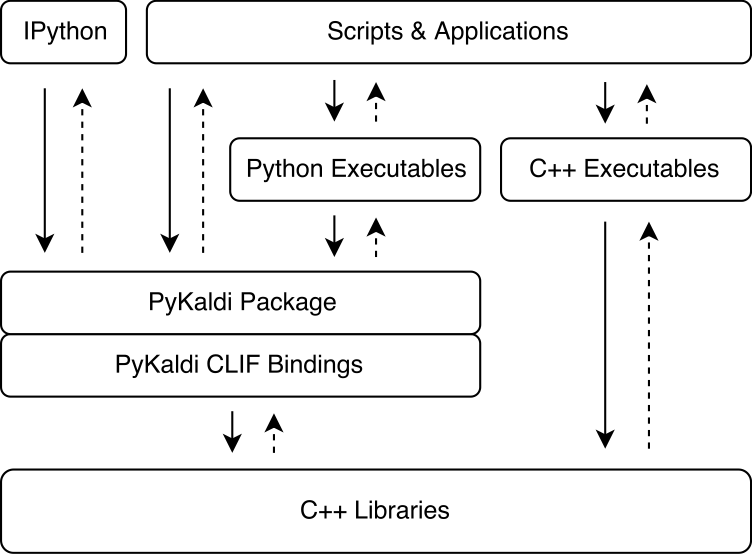
Pykaldi具有模塊化設計,可以易於維護和擴展。源文件是在Kaldi源樹的複製品的目錄樹中組織的。每個目錄定義一個子彈,並僅包含為關聯的Kaldi庫編寫的包裝代碼。包裝器代碼包括:
CLIF C ++ API描述定義要包裝的類型和函數及其Python API,
C ++標頭定義Kaldi代碼的墊片,該墊片不符合Clif期望的Google C ++樣式
Python模塊將與CLIF生成的相關擴展模塊組合在一起,並擴展了RAW CLIF包裝器,以提供更多的“ Pythonic” API。
您可以在我們的論文中閱讀有關Pykaldi的設計和技術細節的更多信息。
下表顯示了每個Pykaldi軟件包的狀態(我們目前不打算沿以下維度添加對NNET,NNET2和Online的支持):
| 包裹 | 包裹? | Pythonic? | 文件? | 測試? |
|---|---|---|---|---|
| 根據 | ✔ | ✔ | ✔✔ | ✔ |
| 鏈 | ✔ | ✔ | ✔✔ | |
| cudamatrix | ✔ | ✔ | ✔ | |
| 解碼器 | ✔ | ✔ | ✔✔ | |
| 壯舉 | ✔ | ✔ | ✔✔ | |
| fstext | ✔ | ✔ | ✔✔ | |
| GMM | ✔ | ✔ | ✔✔ | ✔ |
| 唔 | ✔ | ✔ | ✔✔ | ✔ |
| ivector | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔✔ | |
| 拉特 | ✔ | ✔ | ✔✔ | |
| LM | ✔ | ✔ | ✔✔ | |
| 矩陣 | ✔ | ✔ | ✔✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| 在線2 | ✔ | ✔ | ✔✔ | |
| rnnlm | ✔ | ✔ | ✔✔ | |
| SGMM2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔✔ | |
| 轉換 | ✔ | ✔ | ✔ | |
| 樹 | ✔ | ✔ | ||
| util | ✔ | ✔ | ✔✔ | ✔ |
如果您使用的是相對較新的Linux或MacOS,例如Ubuntu> = 16.04,Centos> = 7或MacOS> = 10.13,則應該能夠在沒有太多麻煩的情況下安裝Pykaldi。否則,您可能需要調整安裝腳本。
現在,您可以從我們的GitHub發布頁面下載官方WHL軟件包。我們有python 3.7、3.8,...,3.11的WHL軟件包,用於Mac M1/M2的一些(實驗)構建。
如果您決定使用WHL軟件包,則可以跳過下一個部分,然後直接前往“使用Pykaldi WHL軟件包啟動新項目”來設置項目。請注意,您仍然需要編譯Kaldi的Pykaldi兼容版本。
要從源安裝和構建Pykaldi,請按照以下步驟操作。
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldi儘管不是必需的,但我們建議在新的孤立的Python環境中安裝Pykaldi及其所有Python依賴性。如果您不想創建新的Python環境,則可以跳過此步驟的其餘部分。
您可以使用自己喜歡的任何工具來創建新的Python環境。在這裡,我們使用virtualenv ,但是如果您願意,您可以使用其他工具等conda 。在繼續安裝的其餘部分之前,請確保激活新的Python環境。
virtualenv env
source env/bin/activate運行下面的命令將安裝從源構建Pykaldi所需的系統軟件包。
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "運行以下命令將安裝從源構建Pykaldi所需的Python軟件包。
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommended除了上述軟件包外,我們還需要以下軟件的Pykaldi兼容安裝:
Google Protobuf,推薦v3.5.0。必須安裝C ++庫和Python軟件包。
Pykaldi兼容Clif的叉子。為了簡化Pykaldi開發,我們對Clif代碼庫進行了一些更改。我們希望隨著時間的推移對這些變化進行上游。這些變化在Pykaldi分支:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi您可以使用tools目錄中的腳本在本地安裝或更新這些軟件。確保檢查這些腳本的輸出。如果您看不到Done installing {protobuf,CLIF,Kaldi}在最後打印,則意味著由於某種原因,安裝失敗了。
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..請注意,如果您要在Apple Silicion上編譯Kaldi,並且./install_kaldi.sh始於開始編譯SCTK,則可能需要從工具/kaldi/tools/makefile中刪除-march =本機,例如,通過在此行中不滿意,
SCTK_CXFLAGS = -w # -march=native 如果將Kaldi安裝在tools目錄中,並且所有Python依賴(Numpy,Pyparsing,Pyclif,Protobuf)安裝在Active Python環境中,則可以使用以下命令安裝Pykaldi。
python setup.py install安裝後,您可以使用以下命令運行Pykaldi測試。
python setup.py test然後,您還可以創建一個WHL軟件包。 WHL軟件包使將Pykaldi安裝到您的語音項目的新項目環境中變得容易。
python setup.py bdist_wheel然後可以在“ DIST”文件夾中找到WHL文件。 WHL文件名取決於Pykaldi版本,您的Python版本和您的架構。對於python 3.9構建x86_64,使用pykaldi 0.2.2它看起來像:dist/pykaldi-0.2.2.2-cp39-cp39-cp39-linux_x86_64.whl
創建一個新的項目文件夾,例如:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASR創建並激活具有與WHL軟件包相同的Python版本的虛擬環境,例如Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activate將numpy和pykaldi安裝到您的Myasr環境中:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl 將pykaldi/tools/install_kaldi.sh複製到您的myasr項目。使用install_kaldi.sh腳本為您的項目安裝pykaldi兼容的kaldi版本:
./install_kaldi.sh將pykaldi/tools/path.sh複製到您的項目。 PATH.SH用於使Pykaldi在Kaldi文件夾中找到Kaldi庫和二進製文件。 source path.sh with:
. path.sh恭喜,您準備在項目中使用Pykaldi!
注意:每當您打開新外殼時,都需要源自項目環境和路徑。 SH:
. myasr_env/bin/activate
. path.sh注意:不幸的是,Pykaldi Conda套餐已經過時了。如果您想維護它,請與我們聯繫。
在CUDA支持的情況下安裝Pykaldi:
conda install -c pykaldi pykaldi在沒有CUDA支持的情況下安裝Pykaldi(僅CPU):
conda install -c pykaldi pykaldi-cpu請注意,Pykaldi Conda軟件包不提供Kaldi可執行文件。如果您想與Pykaldi一起使用Kaldi可執行文件,例如作為讀/寫規範的一部分,則需要單獨安裝Kaldi。
注意:下面的Docker說明可能已過時。如果您想維護Pykaldi的Docker映像,請與我們聯繫。
如果您想在Docker容器中使用Pykaldi,請按照docker文件夾中的說明進行操作。
默認情況下,Pykaldi install命令使用所有可用的(邏輯)處理器來加速構建過程。如果與處理器的數量相比,系統內存的大小相對較小,則並行編譯/鏈接作業可能最終會耗盡系統內存並導致交換。您可以限制用於構建Pykaldi的並行作業數量,如下所示:
MAKE_NUM_JOBS=2 python setup.py install我們不知道在Windows上構建Pykaldi需要什麼。它可能需要對構建系統進行大量更改。
目前,Pykaldi與上游Kaldi存儲庫不兼容。您需要與我們的Kaldi叉相抵制它。
如果您的系統上已經有兼容的Kaldi安裝,則無需在pykaldi/tools目錄中安裝新的安裝。相反,您可以在運行Pykaldi安裝命令之前簡單地設置以下環境變量。
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >目前,Pykaldi與上游CLIF存儲庫不兼容。您需要使用我們的CLIF叉來構建它。
如果您的系統上已經有兼容的CLIF安裝,則無需在pykaldi/tools目錄中安裝新的CLIF安裝。相反,您可以在運行Pykaldi安裝命令之前簡單地設置以下環境變量。
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " >雖然更新Protobuf和Clif的需求不應經常出現,但您可能需要或需要更新用於構建Pykaldi的Kaldi安裝。在tools目錄中重新啟動相關的安裝腳本應更新現有安裝。如果這不起作用,請打開問題。
如果可以在Kaldi庫中找到kaldi-tensorflow-rnnlm庫,則Pykaldi tfrnnlm軟件包將自動構建,並與其他Pykaldi一起構建。構建Kaldi後,請訪問KALDI_DIR/src/tfrnnlm/ Directory,並按照makefile中給出的說明進行操作。確保將kaldi-tensorflow-rnnlm庫的符號鏈接添加到KALDI_DIR/src/lib/ Directory中。
Shennong-使用Pykaldi的工具箱,例如MFCC,PLP等。
Kaldi Model Server-用於實時解碼的螺紋Kaldi模型服務器。可以使用NNET3兼容模型直接從麥克風中解碼語音。提供英語和德語的示例模型。使用Pykaldi Online2解碼器。
MEDERBOT-使用Pykaldi/Kaldi-Model-Server後端來滿足轉錄和摘要的Web應用程序的示例,以在瀏覽器中顯示ASR輸出。
subtitle2go-任何媒體文件的自動字幕生成。將Pykaldi用於ASR與批處理解碼器。
如果您有一個酷炫的開源項目,該項目利用您想在這裡展示的Pykaldi,請告訴我們!
如果您使用Pykaldi進行研究,請引用我們的論文如下:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
我們感謝所有貢獻!如果您發現錯誤,請隨時打開問題或拉動請求。如果您想請求或添加新功能,請打開一個問題進行討論。


