pykaldi
v0.2.2
Pykaldi es una capa de secuencias de comandos de Python para el kit de herramientas de reconocimiento de voz de Kaldi. Proporciona envoltorios de pitón de primera clase fácil de usar, de primera clase, de primera clase para el código C ++ en las bibliotecas Kaldi y OpenFST. Puede usar Pykaldi para escribir el código Python para cosas que de otro modo requerirían escribir código C ++, como llamar a funciones de Kaldi de bajo nivel, manipular Kaldi y OpenFST objetos en código o implementar nuevas herramientas Kaldi.
Puedes pensar en Kaldi como una gran caja de Legos que puedes mezclar y combinar para construir soluciones personalizadas de reconocimiento de voz. La mejor manera de pensar en Pykaldi es como un suplemento, un compañero si lo desea, a Kaldi. De hecho, Pykaldi está en su mejor momento cuando se usa junto a Kaldi. Con ese fin, replicar la funcionalidad de innumerables herramientas de línea de comandos, scripts de utilidad y recetas de nivel de shell proporcionadas por Kaldi es un no gol para el proyecto Pykaldi.
Al igual que Kaldi, Pykaldi está destinado principalmente a investigadores y profesionales de reconocimiento de voz. Está repleto de golosinas que uno necesitaría construir un software Python aprovechando la amplia colección de utilidades, algoritmos y estructuras de datos proporcionadas por Kaldi y Bibliotecas OpenFST.
Si no está familiarizado con el reconocimiento de voz basado en FST o no tiene interés en tener acceso a las entrañas de Kaldi y Openfst en Python, pero solo quiere ejecutar un sistema Kaldi previamente capacitado como parte de su aplicación de Python, no se preocupe. Pykaldi incluye una serie de módulos orientados a aplicaciones de alto nivel, como asr , alignment y segmentation , que deberían ser accesibles para la mayoría de los programadores de Python.
Si está interesado en usar Pykaldi para investigar o construir aplicaciones ASR avanzadas, está de suerte. Pykaldi viene con todo lo que necesitas leer, escribir, inspeccionar, manipular o visualizar los objetos Kaldi y abiertos en Python. Incluye envoltorios de pitón para la mayoría de las funciones y métodos que forman parte de las API públicas de las bibliotecas Kaldi y OpenFST C ++. Si desea leer/escribir archivos producidos/consumidos por Kaldi Tools, consulte la E/S y las utilidades de la tabla en el paquete util . Si desea trabajar con matrices y vectores de Kaldi, por ejemplo, conviértalos en ndarrays y viceversa, consulte el paquete matrix . Si desea usar Kaldi para la extracción y transformación de características, consulte los paquetes de feat , ivector y transform . Si desea trabajar con redes u otras estructuras FST producidas/consumidas por Kaldi Tools, consulte los paquetes fstext , lat y kws . Si desea acceso de bajo nivel a los modelos de mezcla gaussiana, modelos ocultos de Markov o árboles de decisión fonética en Kaldi, consulte los paquetes gmm , sgmm2 , hmm y tree . Si desea acceso de bajo nivel a los modelos de red neuronal Kaldi, consulte los paquetes nnet3 , cudamatrix y chain . Si desea utilizar los decodificadores y las utilidades de modelado de idiomas en Kaldi, consulte los paquetes decoder , lm , rnnlm , tfrnnlm y online2 .
Los lectores interesados que deseen aprender más sobre Kaldi y Pykaldi podrían encontrar útiles los siguientes recursos:
Dado que el reconocimiento automático de voz (ASR) en Python es, sin duda, la "aplicación asesina" para Pykaldi, repasaremos algunos escenarios ASR para tener una idea de la API de Pykaldi. Debemos tener en cuenta que Pykaldi no proporciona servicios públicos de alto nivel para capacitar a los modelos ASR, por lo que debe capacitar a sus modelos con recetas de Kaldi o usar modelos previamente capacitados disponibles en línea. La razón por la cual esto es así es simplemente porque no hay una API de entrenamiento ASR de alto nivel en las bibliotecas Kaldi C ++. Los modelos Kaldi ASR están entrenados utilizando recetas complejas de nivel de concha que manejan todo, desde la preparación de datos hasta la orquestación de innumerables ejecutables de Kaldi utilizados en el entrenamiento. Esto es por diseño y es poco probable que cambie en el futuro. Pykaldi proporciona envoltorios para las utilidades de entrenamiento ASR de bajo nivel en las bibliotecas Kaldi C ++, pero no son realmente útiles a menos que desee construir una tubería de entrenamiento ASR en Python a partir de bloques de construcción básicos, lo cual no es una tarea fácil. Continuando con la analogía de LEGO, esta tarea es similar a construir este acceso dado a un camión lleno de Legos que podría necesitar. Sin embargo, si estás lo suficientemente loco como para intentarlo, no dejes que este párrafo te desanime. Antes de comenzar a construir Pykaldi, pensamos que también era la tarea de un loco.
El módulo Pykaldi asr incluye una serie de clases fáciles de usar y de alto nivel para que sea fácil de armar sistemas ASR en Python. Ignorar el código de Boilerplate necesario para configurar las cosas, hacer ASR con Pykaldi puede ser tan simple como el siguiente fragmento de código:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ]) En este ejemplo simplificado, primero instanciamos un reconocimiento hipotético SomeRecognizer con las rutas para el modelo final.mdl , el gráfico de decodificación HCLG.fst y las words.txt de la tabla de símbolos.txt. El objeto opts contiene las opciones de configuración para el reconocimiento. Luego, instanciamos un lector de la tabla de Pykaldi SequentialMatrixReader para leer las matrices de características almacenadas en el archivo feats.ark . Finalmente, iteramos sobre las matrices de características y las decodificamos una por una. Aquí simplemente estamos imprimiendo la mejor hipótesis ASR para cada enunciado, por lo que solo estamos interesados en la entrada "text" del diccionario de out . Tenga en cuenta que el diccionario de salida contiene un montón de otras entradas útiles, como la alineación del nivel de marco de la mejor hipótesis y una red ponderada que representa las hipótesis más probables. Es cierto que no todas las tuberías ASR serán tan simples como este ejemplo, pero a menudo tendrán la misma estructura general. En las siguientes secciones, veremos cómo podemos adaptar el código dado anteriormente para implementar tuberías ASR más complicadas.
Este es el escenario más común. Queremos hacer ASR fuera de línea utilizando modelos Kaldi previamente capacitados, como los modelos de cadena Aspire. Aquí estamos utilizando el término "modelos" libremente para referirnos a todo lo que uno necesitaría para armar un sistema ASR. En este ejemplo específico, vamos a necesitar:
Tenga en cuenta que puede usar este código de ejemplo para decodificar con los modelos de cadena Aspire.
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ] La diferencia fundamental entre este ejemplo y el fragmento corto de la última sección es que para cada enunciado estamos leyendo los datos de audio sin procesar del disco y calculando dos matrices de características en la mosca en lugar de leer una sola matriz de características precomputadas del disco. El archivo de script wav.scp contiene una lista de archivos WAV correspondientes a las expresiones que queremos decodificar. La matriz de características adicionales que estamos extrayendo contiene vectores I en línea que utilizan el modelo acústico de la red neuronal para realizar la adaptación de canales y altavoces. El mapa del altavoz a la tutor spk2utt se utiliza para acumular estadísticas separadas para cada altavoz en la extracción en vector i en línea. Puede ser un mapeo de identidad simple si la información del altavoz no está disponible. Empacamos las características de MFCC y los vectores I a una tupla y pasamos esta tupla al reconocimiento para decodificar. Los reconocedores de la red neuronal en Pykaldi saben cómo manejar las características adicionales del vector I cuando están disponibles. El archivo del modelo final.mdl contiene tanto el modelo de transición como el modelo acústico de la red neuronal. NnetLatticeFasterRecognizer procesa matrices de características mediante la calculación de Lig-Likeliess de la red neuronal utilizando el modelo acústico de la red neuronal, luego asignando las que se realizan a la transición log-Likeliess utilizando el modelo de transición y finalmente decodificando el registro de transición-Likelies de las secuencias de palabras en las secuencias de palabras que decodifican el gráfico HCLG.fst , que tiene identificaciones de transición en sus etiquetas de transición y etiquetas de palabras en sus emisiones de palabras. Después de la decodificación, salvamos la red generada por el reconocedor a un archivo Kaldi para un procesamiento futuro.
Este ejemplo también ilustra los poderosos mecanismos de E/S proporcionados por Kaldi. En lugar de implementar las tuberías de extracción de características en el código, las definimos como Kaldi lee especificadores y calculamos las matrices de características simplemente instanciando a los lectores de la tabla de Pykaldi e iterando sobre ellos. Esta no es solo la forma más simple, sino también la forma más rápida de calcular las características con Pykaldi, ya que el sistema operativo ejecuta la tubería de extracción de características en paralelo. Del mismo modo, utilizamos un especificador de escritura kaldi para instanciar un escritor de mesa de Pykaldi que escribe redes de salida en un archivo Kaldi comprimido. Tenga en cuenta que para que estos funcionen, necesitamos compute-mfcc-feats , ivector-extract-online2 y gzip para estar en nuestro PATH .
Esto es similar al escenario anterior, pero en lugar de un modelo acústico de Kaldi, utilizamos un modelo acústico de Pytorch. Después de calcular las características como antes, las convertimos en un tensor de Pytorch, hacemos el pase hacia adelante utilizando un módulo de red neuronal de Pytorch que sale del teléfono de los teléfonos-probabilidades y finalmente convirtimos esas probabilidades de registro en una matriz de Pykaldi para decodificar. El reconocedor utiliza el modelo de transición para asignar automáticamente las ID de teléfono a las ID de transición, las etiquetas de entrada en un gráfico de decodificación de kaldi típico.
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]Esta sección es un marcador de posición. Mientras tanto, mira este guión.
La redacción de la red es una técnica estándar para usar grandes modelos de lenguaje N-Gram o modelos de lenguaje de red neuronal recurrente (RNNLMS) en ASR. En este ejemplo, reestructuramos las redes usando un Kaldi Rnnlm. Primero creamos instanciar a un rescator al proporcionar las rutas para los modelos. Luego usamos un lector de tabla para iterar sobre las redes que queremos rescorar y finalmente usamos un escritor de mesa para volver a escribir en redes en disco.
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat ) Observe el nombre de archivo extendido que usamos para calcular la palabra incrustaciones de las características de la palabra y las incrustaciones de características sobre la mosca. También se destacan los especificadores de lectura/escritura que usamos para descomprimir/comprimir de manera transparente los archivos de la red. Para que estos funcionen, necesitamos rnnlm-get-word-embedding , gunzip y gzip para estar en nuestro PATH .
Pykaldi tiene como objetivo cerrar la brecha entre Kaldi y todas las cosas bonitas que Python tiene para ofrecer. Es más que una colección de enlaces en las bibliotecas Kaldi. Es una capa de secuencias de comandos que proporciona soporte de primera clase para los tipos esenciales de Kaldi y OpenFST en Python. Los tipos de vector y matriz de Pykaldi están estrechamente integrados con Numpy. Se pueden convertir sin problemas en matrices numpy y viceversa sin copiar los buffers de memoria subyacentes. Los tipos de Pykaldi FST, incluidas las redes de estilo Kaldi, son ciudadanos de primera clase en Python. La API para el usuario que enfrenta los tipos y operaciones de FST se define casi por completo en Python imitando la API expuesta por Pyrapfst, el envoltorio oficial de Python para OpenFST.
Pykaldi aprovecha el poder del clif para envolver las bibliotecas Kaldi y OpenFST C ++ utilizando descripciones de API simples. Los módulos de extensión de CPython generados por Clif se pueden importar en Python para interactuar con Kaldi y OpenFST. Si bien Clif es excelente para exponer la API C ++ existente en Python, los envoltorios no siempre exponen una API "pitónica" que es fácil de usar de Python. Pykaldi aborda esto extendiendo los envoltorios de clif sin procesar en Python (y a veces en C ++) para proporcionar una API más "pitónica". A continuación, la figura ilustra dónde encaja Pykaldi en el ecosistema Kaldi.
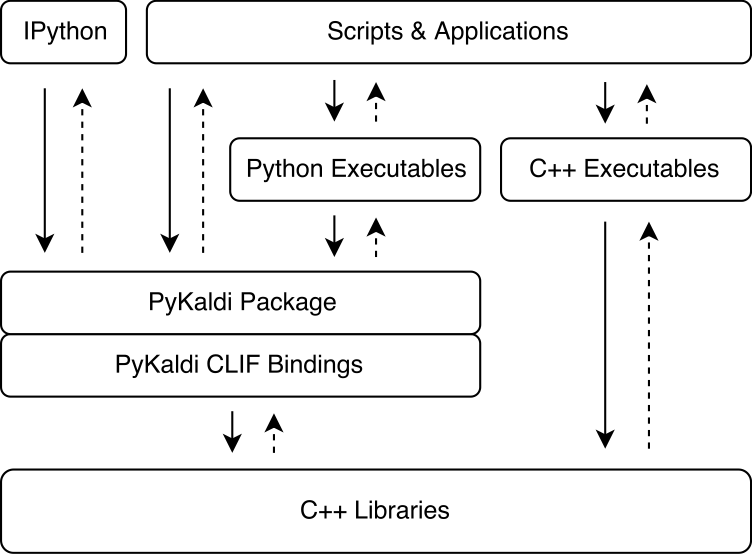
Pykaldi tiene un diseño modular que hace que sea fácil mantener y extender. Los archivos de origen se organizan en un árbol de directorio que es una réplica del árbol de origen Kaldi. Cada directorio define un subpackaje y contiene solo el código de envoltura escrito para la biblioteca Kaldi asociada. El código de envoltura consta de:
CLIF C ++ Descripciones de API Definición de los tipos y funciones a envolver y su API de Python,
Encabezados C ++ Definición de las cuñas para el código Kaldi que no cumple con el estilo de Google C ++ esperado por Clif,
Los módulos de pitón agrupan los módulos de extensión relacionados generados con clif y extendiendo los envoltorios de clif sin procesar para proporcionar una API más "pitónica".
Puede leer más sobre el diseño y los detalles técnicos de Pykaldi en nuestro artículo.
La siguiente tabla muestra el estado de cada paquete Pykaldi (actualmente no planeamos agregar soporte para NNET, NNET2 y en línea) a lo largo de las siguientes dimensiones:
| Paquete | ¿Envuelto? | Pitónico? | ¿Documentación? | Pruebas? |
|---|---|---|---|---|
| base | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| cadena | ✔ | ✔ | ✔ ✔ ✔ | |
| cudamatriz | ✔ | ✔ | ✔ | |
| descifrador | ✔ | ✔ | ✔ ✔ ✔ | |
| logro | ✔ | ✔ | ✔ ✔ ✔ | |
| fstext | ✔ | ✔ | ✔ ✔ ✔ | |
| gmm | ✔ | ✔ | ✔ ✔ | ✔ |
| Mmm | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| morder | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔ ✔ ✔ | |
| Lat | ✔ | ✔ | ✔ ✔ ✔ | |
| lm | ✔ | ✔ | ✔ ✔ ✔ | |
| matriz | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| en línea2 | ✔ | ✔ | ✔ ✔ ✔ | |
| rnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| sgmm2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔ ✔ ✔ | |
| transformar | ✔ | ✔ | ✔ | |
| árbol | ✔ | ✔ | ||
| utilizar | ✔ | ✔ | ✔ ✔ ✔ | ✔ |
Si está utilizando un Linux o macOS relativamente reciente, como Ubuntu> = 16.04, CentOS> = 7 o macOS> = 10.13, debería poder instalar Pykaldi sin demasiados problemas. De lo contrario, es probable que necesite ajustar los scripts de instalación.
Ahora puede descargar paquetes WHL oficiales de nuestra página de lanzamiento de GitHub. Tenemos paquetes WHL para Python 3.7, 3.8, ..., 3.11 en Linux y algunas construcciones (experimentales) para Mac M1/M2.
Si decide usar un paquete WHL, puede omitir las siguientes secciones y dirigirse directamente a "Iniciar un nuevo proyecto con un paquete Pykaldi WHL" para configurar su proyecto. Tenga en cuenta que aún necesita compilar una versión compatible con Pykaldi de Kaldi.
Para instalar y construir Pykaldi desde la fuente, siga los pasos que se dan a continuación.
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldiAunque no es necesario, recomendamos instalar Pykaldi y todas sus dependencias de Python dentro de un nuevo entorno de Python aislado. Si no desea crear un nuevo entorno de Python, puede omitir el resto de este paso.
Puede usar cualquier herramienta que desee para crear un nuevo entorno de Python. Aquí usamos virtualenv , pero puede usar otra herramienta como conda si lo prefiere. Asegúrese de activar el nuevo entorno Python antes de continuar con el resto de la instalación.
virtualenv env
source env/bin/activateEjecutar los comandos a continuación instalará los paquetes del sistema necesarios para construir Pykaldi desde la fuente.
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "Ejecutar los comandos a continuación instalará los paquetes de Python necesarios para construir Pykaldi desde la fuente.
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommendedAdemás de los paquetes mencionados anteriormente, también necesitamos instalaciones compatibles con Pykaldi del siguiente software:
Google ProtoBuf, recomendado v3.5.0. Se deben instalar tanto la biblioteca C ++ como el paquete Python.
Pykaldi Horcor compatible de Clif. Para optimizar el desarrollo de Pykaldi, realizamos algunos cambios en la base de código Clif. Esperamos pasar estos cambios con el tiempo. Estos cambios están en la rama de Pykaldi:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi Puede usar los scripts en el directorio tools para instalar o actualizar este software localmente. Asegúrese de verificar la salida de estos scripts. Si no ves Done installing {protobuf,CLIF,Kaldi} impreso al final, significa que la instalación ha fallado por alguna razón.
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..Nota, si está compilando Kaldi en Apple Silicion y ./install_kaldi.sh se atasca justo al principio compilando SCTK, es posible que deba eliminar -march = nativo de herramientas/kaldi/herramientas/makefile, por ejemplo, al no comunicarlo en esta línea como esta:
SCTK_CXFLAGS = -w # -march=native Si Kaldi se instala dentro del directorio tools y todas las dependencias de Python (Numpy, PyParsing, Pyclif, ProtoBuf) se instalan en el entorno Python Active, puede instalar Pykaldi con el siguiente comando.
python setup.py installUna vez instalado, puede ejecutar pruebas de Pykaldi con el siguiente comando.
python setup.py testLuego también puede crear un paquete WHL. El paquete WHL facilita la instalación de Pykaldi en un nuevo entorno de proyecto para su proyecto de habla.
python setup.py bdist_wheelEl archivo WHL se puede encontrar en la carpeta "Dist". El nombre de archivo WHL depende de la versión de Pykaldi, su versión de Python y su arquitectura. Para una construcción de Python 3.9 en x86_64 con Pykaldi 0.2.2 puede parecer: Dist/Pykaldi-0.2.2-CP39-CP39-Linux_X86_64.Whl
Cree una nueva carpeta de proyecto, por ejemplo:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASRCree y active un entorno virtual con la misma versión de Python que el paquete WHL, por ejemplo, para Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activateInstale Numpy y Pykaldi en su entorno MYASR:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl Copie pykaldi/herramientas/instalación_kaldi.sh a su proyecto myAsr. Use el script install_kaldi.sh para instalar una versión Kaldi compatible con Pykaldi para su proyecto:
./install_kaldi.shCopie pykaldi/herramientas/path.sh a su proyecto. Path.Sh se usa para hacer que Pykaldi encuentre las bibliotecas y binarios de Kaldi en la carpeta Kaldi. Fuente ruta.sh con:
. path.sh¡Felicitaciones, estás listo para usar Pykaldi en tu proyecto!
Nota: Cada vez que abre un nuevo shell, debe obtener el entorno y la ruta del proyecto.
. myasr_env/bin/activate
. path.shNota: Desafortunadamente, los paquetes de conda de Pykaldi están desactualizados. Si desea mantenerlo, póngase en contacto con nosotros.
Para instalar Pykaldi con soporte CUDA:
conda install -c pykaldi pykaldiPara instalar Pykaldi sin soporte CUDA (solo CPU):
conda install -c pykaldi pykaldi-cpuTenga en cuenta que el paquete Pykaldi Conda no proporciona ejecuciones de Kaldi. Si desea usar ejecutables de Kaldi junto con Pykaldi, por ejemplo, como parte de los especificadores de lectura/escritura, debe instalar Kaldi por separado.
Nota: Las instrucciones de Docker a continuación pueden estar desactualizadas. Si desea mantener una imagen de Docker para Pykaldi, póngase en contacto con nosotros.
Si desea usar Pykaldi dentro de un contenedor Docker, siga las instrucciones en la carpeta docker .
De forma predeterminada, el comando Pykaldi Install utiliza todos los procesadores disponibles (lógicos) para acelerar el proceso de compilación. Si el tamaño de la memoria del sistema es relativamente pequeño en comparación con el número de procesadores, los trabajos de compilación/vinculación paralelos pueden terminar agotando la memoria del sistema y dar como resultado el intercambio. Puede limitar el número de trabajos paralelos utilizados para construir Pykaldi de la siguiente manera:
MAKE_NUM_JOBS=2 python setup.py installNo tenemos idea de lo que se necesita para construir Pykaldi en Windows. Probablemente requeriría muchos cambios en el sistema de compilación.
Por el momento, Pykaldi no es compatible con el repositorio de Kaldi aguas arriba. Necesitas construirlo contra nuestro Kaldi Fork.
Si ya tiene una instalación de Kaldi compatible en su sistema, no necesita instalar uno nuevo dentro del directorio pykaldi/tools . En su lugar, simplemente puede establecer la siguiente variable de entorno antes de ejecutar el comando de instalación de Pykaldi.
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >Por el momento, Pykaldi no es compatible con el repositorio de Clif aguas arriba. Debe construirlo usando nuestro horquilla Clif.
Si ya tiene una instalación de clif compatible en su sistema, no necesita instalar uno nuevo dentro del directorio pykaldi/tools . En su lugar, simplemente puede establecer las siguientes variables de entorno antes de ejecutar el comando de instalación de Pykaldi.
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " > Si bien la necesidad de actualizar ProtoBuf y Clif no debe surgir muy a menudo, es posible que desee o necesite actualizar la instalación de Kaldi utilizada para construir Pykaldi. Volver a ejecutar el script de instalación relevante en el directorio tools debe actualizar la instalación existente. Si esto no funciona, abra un problema.
El paquete Pykaldi tfrnnlm se construye automáticamente junto con el resto de Pykaldi si la biblioteca kaldi-tensorflow-rnnlm se puede encontrar entre las bibliotecas Kaldi. Después de construir Kaldi, vaya a KALDI_DIR/src/tfrnnlm/ directorio y siga las instrucciones dadas en el makefile. Asegúrese de que el enlace simbólico para la biblioteca kaldi-tensorflow-rnnlm se agregue al directorio KALDI_DIR/src/lib/ .
Shennong: una caja de herramientas para la extracción de características del habla, como MFCC, PLP, etc. usando Pykaldi.
Servidor de modelos Kaldi: un servidor de modelos Kaldi roscado para decodificación en vivo. Puede decodificar directamente el habla desde su micrófono con un modelo compatible con NNET3. Los modelos de ejemplo para inglés y alemán están disponibles. Utiliza el decodificador Pykaldi Online2.
MeetingBot-Ejemplo de una aplicación web para la transcripción y resumen de la reunión que utiliza un backend de Pykaldi/Kaldi-Model-Server para mostrar la salida ASR en el navegador.
SUBTITLE2GO - Generación automática de subtítulos para cualquier archivo multimedia. Utiliza Pykaldi para ASR con un decodificador por lotes.
Si tiene un proyecto de código abierto genial que hace uso de Pykaldi que le gustaría mostrar aquí, ¡háganoslo saber!
Si usa Pykaldi para la investigación, cite nuestro artículo de la siguiente manera:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
¡Apreciamos todas las contribuciones! Si encuentra un error, no dude en abrir un problema o una solicitud de extracción. Si desea solicitar o agregar una nueva función, abra un problema para la discusión.


