pykaldi
v0.2.2
Pykaldi是Kaldi语音识别工具包的Python脚本层。它为Kaldi和OpenFST库中的C ++代码提供了易于使用的,低空的,一流的Python包装器。您可以使用pykaldi编写python代码,以否则需要编写C ++代码,例如调用低级Kaldi功能,在代码中操纵Kaldi和OpenFST对象或实现新的Kaldi工具。
您可以将Kaldi视为一个大型乐高积木,您可以混合并匹配以构建自定义语音识别解决方案。想到Pykaldi的最好方法是作为补充,如果愿意的话,可以搭配Kaldi。实际上,当Pykaldi与Kaldi一起使用时,它处于最佳状态。为此,复制Kaldi提供的无数命令行工具,实用程序脚本和壳级配方的功能是Pykaldi项目的非目标。
像卡尔迪(Kaldi)一样,Pykaldi主要用于言语识别研究人员和专业人士。它充满了装满的东西,需要利用Kaldi和OpenFST库提供的大量实用程序,算法和数据结构来构建Python软件。
如果您不熟悉基于FST的语音识别或对访问Python中Kaldi和OpenFST的胆量没有兴趣,但是只想在Python应用程序的一部分中运行预先训练的Kaldi系统,请不要担心。 Pykaldi包括大多数Python程序员应该可以访问的许多高级应用方向的模块,例如asr , alignment和segmentation 。
如果您有兴趣使用Pykaldi进行研究或构建高级ASR应用程序,那么您很幸运。 Pykaldi提供了您在Python中读,写,检查,操纵或可视化Kaldi和OpenFST对象所需的一切。它包括Python包装器,用于大多数功能和方法,这些功能和方法是Kaldi和OpenFST C ++库的一部分。如果您想读取/写由Kaldi工具生成/消耗的文件,请在util软件包中查看I/O和表实用程序。如果您想使用Kaldi矩阵和向量,例如将它们转换为numpy ndarrays,反之亦然,请查看matrix软件包。如果您想使用Kaldi进行功能提取和转换,请查看feat , ivector和transform Packages。如果您想使用Kaldi工具生产/消耗的晶格或其他FST结构,请查看fstext , lat和kws软件包。如果您想在Kaldi中低水平访问高斯混合模型,隐藏的马尔可夫模型或语音决策树,请查看gmm , sgmm2 , hmm和tree包。如果您想低水平访问Kaldi神经网络模型,请查看nnet3 , cudamatrix和chain套件。如果您想在Kaldi中使用解码器和语言建模实用程序,请查看decoder , lm , rnnlm , tfrnnlm和online2软件包。
有兴趣了解Kaldi和Pykaldi更多有关Kaldi和Pykaldi的读者可能会发现以下资源有用:
由于Python中的自动语音识别(ASR)无疑是Pykaldi的“杀手应用程序”,因此我们将浏览一些ASR场景,以了解Pykaldi API。我们应该注意,Pykaldi不提供用于培训ASR模型的任何高级实用程序,因此您需要使用Kaldi食谱培训模型或使用在线可用的预培训模型。之所以如此,是因为Kaldi C ++库中没有高级ASR培训API。使用复杂的壳级配方对Kaldi ASR模型进行了培训,这些配方可以处理从数据制备到培训中使用的无数Kaldi可执行文件的所有内容。这是设计,将来不太可能发生变化。 Pykaldi确实为Kaldi C ++库中的低级ASR培训实用程序提供包装纸,但是除非您想通过基本的构建块在Python建立ASR培训管道,否则这些库并不是很容易的,这并不是一件容易的事。继续进行乐高的类比,此任务类似于构建此给定的访问您可能需要的乐高积木的卡车的访问。如果您疯了足够尝试,请不要让本段劝阻您。在我们开始构建Pykaldi之前,我们认为这也是一个疯狂的任务。
Pykaldi asr模块包含许多易于使用的高级类,以使将ASR系统放在Python中简单。忽略设置设置所需的样板代码,使用Pykaldi进行ASR可以像以下代码段一样简单:
asr = SomeRecognizer . from_files ( "final.mdl" , "HCLG.fst" , "words.txt" , opts )
with SequentialMatrixReader ( "ark:feats.ark" ) as feats_reader :
for key , feats in feats_reader :
out = asr . decode ( feats )
print ( key , out [ "text" ])在这个简化的示例中,我们首先使用模型final.mdl ,解码图HCLG.fst和符号表words.txt的模型final.mdl的路径实例化SomeRecognizer 。 opts对象包含识别器的配置选项。然后,我们实例化了一个Pykaldi Table Reader SequentialMatrixReader ,以读取存储在Kaldi Archive feats.ark中的功能矩阵。最后,我们迭代特征矩阵,然后一一将它们进行解码。在这里,我们只是为每个话语打印出最好的ASR假设,因此我们只对输出字典的"text" out感兴趣。请记住,输出字典包含许多其他有用的条目,例如最佳假设的框架级别对齐和代表最可能假设的加权晶格。诚然,并非所有的ASR管道都像这个示例一样简单,但是它们通常具有相同的整体结构。在以下各节中,我们将看到如何调整上面给出的代码以实现更复杂的ASR管道。
这是最常见的情况。我们想使用预先训练的Kaldi模型(例如Aspire Chain Models)进行离线ASR进行离线ASR。在这里,我们使用“模型”一词来指代建立ASR系统所需的一切。在这个具体示例中,我们将需要:
请注意,您可以使用此示例代码与Aspire链模型进行解码。
from kaldi . asr import NnetLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . nnet3 import NnetSimpleComputationOptions
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
# Set the paths and read/write specifiers
model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
ivectors_rspec = ( feats_rspec + "ivector-extract-online2 "
"--config=models/aspire/conf/ivector_extractor.conf "
"ark:spk2utt ark:- ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
decodable_opts = NnetSimpleComputationOptions ()
decodable_opts . acoustic_scale = 1.0
decodable_opts . frame_subsampling_factor = 3
asr = NnetLatticeFasterRecognizer . from_files (
model_path , graph_path , symbols_path ,
decoder_opts = decoder_opts , decodable_opts = decodable_opts )
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
SequentialMatrixReader ( ivectors_rspec ) as ivectors_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for ( fkey , feats ), ( ikey , ivectors ) in zip ( feats_reader , ivectors_reader ):
assert ( fkey == ikey )
out = asr . decode (( feats , ivectors ))
print ( fkey , out [ "text" ])
lat_writer [ fkey ] = out [ "lattice" ]最后一部分的示例和短片段之间的基本区别在于,对于每种话语,我们都是从磁盘读取原始音频数据并即时计算两个功能矩阵,而不是从磁盘中读取单个预报的特征矩阵。脚本文件wav.scp包含与我们要解码的话语相对应的WAV文件列表。我们正在提取的附加功能矩阵包含在线I-向量,这些i-向量由神经网络声学模型使用,以执行通道和扬声器适应。扬声器对材料图spk2utt用于在线i-vector提取中为每个说话者累积单独的统计信息。如果扬声器信息不可用,则可以是简单的身份映射。我们将MFCC功能和I-向量打包到元组中,然后将此元组传递给识别器进行解码。 Pykaldi中的神经网络识别器知道如何在可用时处理其他I-vetor功能。模型文件final.mdl包含过渡模型和神经网络声学模型。 The NnetLatticeFasterRecognizer processes feature matrices by first computing phone log-likelihoods using the neural network acoustic model, then mapping those to transition log-likelihoods using the transition model and finally decoding transition log-likelihoods into word sequences using the decoding graph HCLG.fst , which has transition IDs on its input labels and word IDs on its output labels.解码后,我们将识别器生成的晶格保存到Kaldi档案中,以进行将来的处理。
此示例还说明了Kaldi提供的强大I/O机制。我们将它们定义为Kaldi读取指定器,并仅通过实例化Pykaldi表读取器并在它们上迭代来计算功能矩阵,而不是在代码中实现功能提取管道,而是将其定义为Kaldi。这不仅是使用Pykaldi计算特征的最简单的方法,因为功能提取管道由操作系统并联运行。同样,我们使用kaldi写入说明符来实例化pykaldi表作者,该桌子作者将输出晶格写入压缩的kaldi存档。请注意,要使它们起作用,我们需要compute-mfcc-feats , ivector-extract-online2和gzip才能走上我们的PATH 。
这类似于以前的情况,但是我们使用Pytorch声学模型,而不是Kaldi声学模型。在计算出以前的功能之后,我们将它们转换为pytorch张量,使用pytorch神经网络模块进行前向通行证,以输出手机日志样式,并最终将这些log-likelihoods转换为pykaldi矩阵进行解码。识别器使用过渡模型自动将手机ID映射到过渡ID,即典型的Kaldi解码图上的输入标签。
from kaldi . asr import MappedLatticeFasterRecognizer
from kaldi . decoder import LatticeFasterDecoderOptions
from kaldi . matrix import Matrix
from kaldi . util . table import SequentialMatrixReader , CompactLatticeWriter
from models import AcousticModel # Import your PyTorch model
import torch
# Set the paths and read/write specifiers
acoustic_model_path = "models/aspire/model.pt"
transition_model_path = "models/aspire/final.mdl"
graph_path = "models/aspire/graph_pp/HCLG.fst"
symbols_path = "models/aspire/graph_pp/words.txt"
feats_rspec = ( "ark:compute-mfcc-feats --config=models/aspire/conf/mfcc.conf "
"scp:wav.scp ark:- |" )
lat_wspec = "ark:| gzip -c > lat.gz"
# Instantiate the recognizer
decoder_opts = LatticeFasterDecoderOptions ()
decoder_opts . beam = 13
decoder_opts . max_active = 7000
asr = MappedLatticeFasterRecognizer . from_files (
transition_model_path , graph_path , symbols_path , decoder_opts = decoder_opts )
# Instantiate the PyTorch acoustic model (subclass of torch.nn.Module)
model = AcousticModel (...)
model . load_state_dict ( torch . load ( acoustic_model_path ))
model . eval ()
# Extract the features, decode and write output lattices
with SequentialMatrixReader ( feats_rspec ) as feats_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , feats in feats_reader :
feats = torch . from_numpy ( feats . numpy ()) # Convert to PyTorch tensor
loglikes = model ( feats ) # Compute log-likelihoods
loglikes = Matrix ( loglikes . numpy ()) # Convert to PyKaldi matrix
out = asr . decode ( loglikes )
print ( key , out [ "text" ])
lat_writer [ key ] = out [ "lattice" ]本节是占位符。同时查看此脚本。
晶格逆转是一种用于使用ASR中大型N-Gram语言模型或经常性神经网络语言模型(RNNLMS)的标准技术。在此示例中,我们使用kaldi rnnlm恢复了晶格。我们首先通过提供模型的路径来实例化委员。然后,我们使用桌子读取器迭代要撤回的晶格,最后使用桌子作家将回归的格子写回磁盘。
from kaldi . asr import LatticeRnnlmPrunedRescorer
from kaldi . fstext import SymbolTable
from kaldi . rnnlm import RnnlmComputeStateComputationOptions
from kaldi . util . table import SequentialCompactLatticeReader , CompactLatticeWriter
# Set the paths, extended filenames and read/write specifiers
symbols_path = "models/tedlium/config/words.txt"
old_lm_path = "models/tedlium/data/lang_nosp/G.fst"
word_feats_path = "models/tedlium/word_feats.txt"
feat_embedding_path = "models/tedlium/feat_embedding.final.mat"
word_embedding_rxfilename = ( "rnnlm-get-word-embedding %s %s - |"
% ( word_feats_path , feat_embedding_path ))
rnnlm_path = "models/tedlium/final.raw"
lat_rspec = "ark:gunzip -c lat.gz |"
lat_wspec = "ark:| gzip -c > rescored_lat.gz"
# Instantiate the rescorer
symbols = SymbolTable . read_text ( symbols_path )
opts = RnnlmComputeStateComputationOptions ()
opts . bos_index = symbols . find_index ( "<s>" )
opts . eos_index = symbols . find_index ( "</s>" )
opts . brk_index = symbols . find_index ( "<brk>" )
rescorer = LatticeRnnlmPrunedRescorer . from_files (
old_lm_path , word_embedding_rxfilename , rnnlm_path , opts = opts )
# Read the lattices, rescore and write output lattices
with SequentialCompactLatticeReader ( lat_rspec ) as lat_reader ,
CompactLatticeWriter ( lat_wspec ) as lat_writer :
for key , lat in lat_reader :
lat_writer [ key ] = rescorer . rescore ( lat )请注意,我们用来从单词功能和即时嵌入功能嵌入的扩展文件名计算单词嵌入。还值得注意的是我们用来透明地解压缩/压缩晶格档案的读/写规范。要使这些工作,我们需要rnnlm-get-word-embedding , gunzip和gzip才能走上我们的PATH 。
Pykaldi旨在弥合Kaldi与Python所提供的所有美好事物之间的差距。它不仅仅是绑定到卡尔迪库的绑定。这是一个脚本层,可为Python中的必需Kaldi和OpenFST类型提供一流的支持。 Pykaldi矢量和基质类型与Numpy紧密整合。它们可以无缝转换为numpy阵列,反之亦然,而无需复制基本的内存缓冲区。 Pykaldi FST类型,包括Kaldi Style Lattices,是Python的一流公民。面对FST类型和操作的用户的API几乎完全定义在Python模仿PyWrapFST(pywrapfst)的API,这是OpenFST的官方Python包装器。
Pykaldi利用CLIF使用简单的API描述来包裹Kaldi和OpenFST C ++库。可以在Python中导入CLIF生成的CPYTHON扩展模块,以与Kaldi和OpenFST相互作用。尽管Clif非常适合暴露Python中现有的C ++ API,但包装器并不总是会揭示Python易于使用的“ Pythonic” API。 Pykaldi通过在Python(有时在C ++中)扩展了RAW CLIF包装器来解决这一问题,以提供更多的“ Pythonic” API。下图说明了pykaldi适合卡尔迪生态系统的位置。
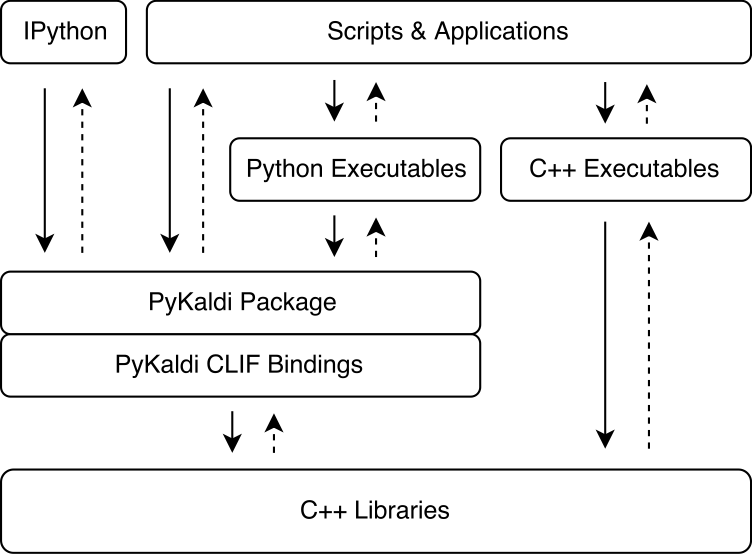
Pykaldi具有模块化设计,可以易于维护和扩展。源文件是在Kaldi源树的复制品的目录树中组织的。每个目录定义一个子弹,并仅包含为关联的Kaldi库编写的包装代码。包装器代码包括:
CLIF C ++ API描述定义要包装的类型和函数及其Python API,
C ++标头定义Kaldi代码的垫片,该垫片不符合Clif期望的Google C ++样式
Python模块将与CLIF生成的相关扩展模块组合在一起,并扩展了RAW CLIF包装器,以提供更多的“ Pythonic” API。
您可以在我们的论文中阅读有关Pykaldi的设计和技术细节的更多信息。
下表显示了每个Pykaldi软件包的状态(我们目前不打算沿以下维度添加对NNET,NNET2和Online的支持):
| 包裹 | 包裹? | Pythonic? | 文档? | 测试? |
|---|---|---|---|---|
| 根据 | ✔ | ✔ | ✔✔ | ✔ |
| 链 | ✔ | ✔ | ✔✔ | |
| cudamatrix | ✔ | ✔ | ✔ | |
| 解码器 | ✔ | ✔ | ✔✔ | |
| 壮举 | ✔ | ✔ | ✔✔ | |
| fstext | ✔ | ✔ | ✔✔ | |
| GMM | ✔ | ✔ | ✔✔ | ✔ |
| 唔 | ✔ | ✔ | ✔✔ | ✔ |
| ivector | ✔ | ✔ | ||
| KWS | ✔ | ✔ | ✔✔ | |
| 拉特 | ✔ | ✔ | ✔✔ | |
| LM | ✔ | ✔ | ✔✔ | |
| 矩阵 | ✔ | ✔ | ✔✔ | ✔ |
| NNET3 | ✔ | ✔ | ✔ | |
| 在线2 | ✔ | ✔ | ✔✔ | |
| rnnlm | ✔ | ✔ | ✔✔ | |
| SGMM2 | ✔ | ✔ | ||
| tfrnnlm | ✔ | ✔ | ✔✔ | |
| 转换 | ✔ | ✔ | ✔ | |
| 树 | ✔ | ✔ | ||
| util | ✔ | ✔ | ✔✔ | ✔ |
如果您使用的是相对较新的Linux或MacOS,例如Ubuntu> = 16.04,Centos> = 7或MacOS> = 10.13,则应该能够在没有太多麻烦的情况下安装Pykaldi。否则,您可能需要调整安装脚本。
现在,您可以从我们的GitHub发布页面下载官方WHL软件包。我们有python 3.7、3.8,...,3.11的WHL软件包,用于Mac M1/M2的一些(实验)构建。
如果您决定使用WHL软件包,则可以跳过下一个部分,然后直接前往“使用Pykaldi WHL软件包启动新项目”来设置项目。请注意,您仍然需要编译Kaldi的Pykaldi兼容版本。
要从源安装和构建Pykaldi,请按照以下步骤操作。
git clone https://github.com/pykaldi/pykaldi.git
cd pykaldi尽管不是必需的,但我们建议在新的孤立的Python环境中安装Pykaldi及其所有Python依赖性。如果您不想创建新的Python环境,则可以跳过此步骤的其余部分。
您可以使用自己喜欢的任何工具来创建新的Python环境。在这里,我们使用virtualenv ,但是如果您愿意,您可以使用其他工具等conda 。在继续安装的其余部分之前,请确保激活新的Python环境。
virtualenv env
source env/bin/activate运行下面的命令将安装从源构建Pykaldi所需的系统软件包。
# Ubuntu
sudo apt-get install autoconf automake cmake curl g++ git graphviz
libatlas3-base libtool make pkg-config subversion unzip wget zlib1g-dev
# macOS
brew install automake cmake git graphviz libtool pkg-config wget gnu-sed openblas subversion
PATH= " /opt/homebrew/opt/gnu-sed/libexec/gnubin: $PATH "运行以下命令将安装从源构建Pykaldi所需的Python软件包。
pip install --upgrade pip
pip install --upgrade setuptools
pip install numpy pyparsing
pip install ninja # not required but strongly recommended除了上述软件包外,我们还需要以下软件的Pykaldi兼容安装:
Google Protobuf,推荐v3.5.0。必须安装C ++库和Python软件包。
Pykaldi兼容Clif的叉子。为了简化Pykaldi开发,我们对Clif代码库进行了一些更改。我们希望随着时间的推移对这些变化进行上游。这些变化在Pykaldi分支:
# This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/clif # This command will be automatically run for you in the tools install scripts.
git clone -b pykaldi https://github.com/pykaldi/kaldi您可以使用tools目录中的脚本在本地安装或更新这些软件。确保检查这些脚本的输出。如果您看不到Done installing {protobuf,CLIF,Kaldi}在最后打印,则意味着由于某种原因,安装失败了。
cd tools
./check_dependencies.sh # checks if system dependencies are installed
./install_protobuf.sh # installs both the C++ library and the Python package
./install_clif.sh # installs both the C++ library and the Python package
./install_kaldi.sh # installs the C++ library
cd ..请注意,如果您要在Apple Silicion上编译Kaldi,并且./install_kaldi.sh始于开始编译SCTK,则可能需要从工具/kaldi/tools/makefile中删除-march =本机,例如,通过在此行中不满意,
SCTK_CXFLAGS = -w # -march=native 如果将Kaldi安装在tools目录中,并且所有Python依赖(Numpy,Pyparsing,Pyclif,Protobuf)安装在Active Python环境中,则可以使用以下命令安装Pykaldi。
python setup.py install安装后,您可以使用以下命令运行Pykaldi测试。
python setup.py test然后,您还可以创建一个WHL软件包。 WHL软件包使将Pykaldi安装到您的语音项目的新项目环境中变得容易。
python setup.py bdist_wheel然后可以在“ DIST”文件夹中找到WHL文件。 WHL文件名取决于Pykaldi版本,您的Python版本和您的架构。对于python 3.9构建x86_64,使用pykaldi 0.2.2它看起来像:dist/pykaldi-0.2.2.2-cp39-cp39-cp39-linux_x86_64.whl
创建一个新的项目文件夹,例如:
mkdir -p ~ /projects/myASR
cd ~ /projects/myASR创建并激活具有与WHL软件包相同的Python版本的虚拟环境,例如Python 2.9:
virtualenv -p /usr/bin/python3.9 myasr_env
. myasr_env/bin/activate将numpy和pykaldi安装到您的Myasr环境中:
pip3 install numpy
pip3 install pykaldi-0.2.2-cp39-cp39-linux_x86_64.whl 将pykaldi/tools/install_kaldi.sh复制到您的myasr项目。使用install_kaldi.sh脚本为您的项目安装pykaldi兼容的kaldi版本:
./install_kaldi.sh将pykaldi/tools/path.sh复制到您的项目。 PATH.SH用于使Pykaldi在Kaldi文件夹中找到Kaldi库和二进制文件。 source path.sh with:
. path.sh恭喜,您准备在项目中使用Pykaldi!
注意:每当您打开新外壳时,都需要源自项目环境和路径。SH:
. myasr_env/bin/activate
. path.sh注意:不幸的是,Pykaldi Conda套餐已经过时了。如果您想维护它,请与我们联系。
在CUDA支持的情况下安装Pykaldi:
conda install -c pykaldi pykaldi在没有CUDA支持的情况下安装Pykaldi(仅CPU):
conda install -c pykaldi pykaldi-cpu请注意,Pykaldi Conda软件包不提供Kaldi可执行文件。如果您想与Pykaldi一起使用Kaldi可执行文件,例如作为读/写规范的一部分,则需要单独安装Kaldi。
注意:下面的Docker说明可能已过时。如果您想维护Pykaldi的Docker映像,请与我们联系。
如果您想在Docker容器中使用Pykaldi,请按照docker文件夹中的说明进行操作。
默认情况下,Pykaldi install命令使用所有可用的(逻辑)处理器来加速构建过程。如果与处理器的数量相比,系统内存的大小相对较小,则并行编译/链接作业可能最终会耗尽系统内存并导致交换。您可以限制用于构建Pykaldi的并行作业数量,如下所示:
MAKE_NUM_JOBS=2 python setup.py install我们不知道在Windows上构建Pykaldi需要什么。它可能需要对构建系统进行大量更改。
目前,Pykaldi与上游Kaldi存储库不兼容。您需要与我们的Kaldi叉相抵制它。
如果您的系统上已经有兼容的Kaldi安装,则无需在pykaldi/tools目录中安装新的安装。相反,您可以在运行Pykaldi安装命令之前简单地设置以下环境变量。
export KALDI_DIR= < directory where Kaldi is installed, e.g. " $HOME /tools/kaldi " >目前,Pykaldi与上游CLIF存储库不兼容。您需要使用我们的CLIF叉来构建它。
如果您的系统上已经有兼容的CLIF安装,则无需在pykaldi/tools目录中安装新的CLIF安装。相反,您可以在运行Pykaldi安装命令之前简单地设置以下环境变量。
export PYCLIF= < path to pyclif executable, e.g. " $HOME /anaconda3/envs/clif/bin/pyclif " >
export CLIF_MATCHER= < path to clif-matcher executable, e.g. " $HOME /anaconda3/envs/clif/clang/bin/clif-matcher " >虽然更新Protobuf和Clif的需求不应经常出现,但您可能需要或需要更新用于构建Pykaldi的Kaldi安装。在tools目录中重新启动相关的安装脚本应更新现有安装。如果这不起作用,请打开问题。
如果可以在Kaldi库中找到kaldi-tensorflow-rnnlm库,则Pykaldi tfrnnlm软件包将自动构建,并与其他Pykaldi一起构建。构建Kaldi后,请访问KALDI_DIR/src/tfrnnlm/ Directory,并按照makefile中给出的说明进行操作。确保将kaldi-tensorflow-rnnlm库的符号链接添加到KALDI_DIR/src/lib/ Directory中。
Shennong-使用Pykaldi的工具箱,例如MFCC,PLP等。
Kaldi Model Server-用于实时解码的螺纹Kaldi模型服务器。可以使用NNET3兼容模型直接从麦克风中解码语音。提供英语和德语的示例模型。使用Pykaldi Online2解码器。
MEDERBOT-使用Pykaldi/Kaldi-Model-Server后端来满足转录和摘要的Web应用程序的示例,以在浏览器中显示ASR输出。
subtitle2go-任何媒体文件的自动字幕生成。将Pykaldi用于ASR与批处理解码器。
如果您有一个酷炫的开源项目,该项目利用您想在这里展示的Pykaldi,请告诉我们!
如果您使用Pykaldi进行研究,请引用我们的论文如下:
@inproceedings{pykaldi,
title = {PyKaldi: A Python Wrapper for Kaldi},
author = {Dogan Can and Victor R. Martinez and Pavlos Papadopoulos and
Shrikanth S. Narayanan},
booktitle={Acoustics, Speech and Signal Processing (ICASSP),
2018 IEEE International Conference on},
year = {2018},
organization = {IEEE}
}
我们感谢所有贡献!如果您发现错误,请随时打开问题或拉动请求。如果您想请求或添加新功能,请打开一个问题进行讨论。


